 机器学习入门:概念、算法与模型构建
机器学习入门:概念、算法与模型构建





 这篇博客介绍了机器学习的基础步骤,包括定义函数集合、确定选择函数的准则、找到最佳函数以及测试。机器学习的过程被比喻为将大象放入冰箱,强调了训练和测试的重要性。文章还对比了深度学习与传统方法在函数映射关系上的差异,并指出学术界和工业界的研究焦点分别在于设计函数集合、选择准则以及优化训练过程。
这篇博客介绍了机器学习的基础步骤,包括定义函数集合、确定选择函数的准则、找到最佳函数以及测试。机器学习的过程被比喻为将大象放入冰箱,强调了训练和测试的重要性。文章还对比了深度学习与传统方法在函数映射关系上的差异,并指出学术界和工业界的研究焦点分别在于设计函数集合、选择准则以及优化训练过程。
2.2 机器学习的步骤
机器学习的任务是输入一些数据,再输出一些数据, 其实就是一种数据转换器。 从数学意义上讲,就是一个合适的函数映射。 我们的目的是要找到一个可以完成任务 的映射函数。 或者说,要找到一个输入数据与输出数据之间的关系。 这个关系,被学 者取名为模型(Model)。 模型本质是描述输入与输出之间关系。 更进一步讲,模型 就是关系(Relationship)。 如何寻找这种关系呢? 通常还是有一定套路的,如图2所 示步骤。1
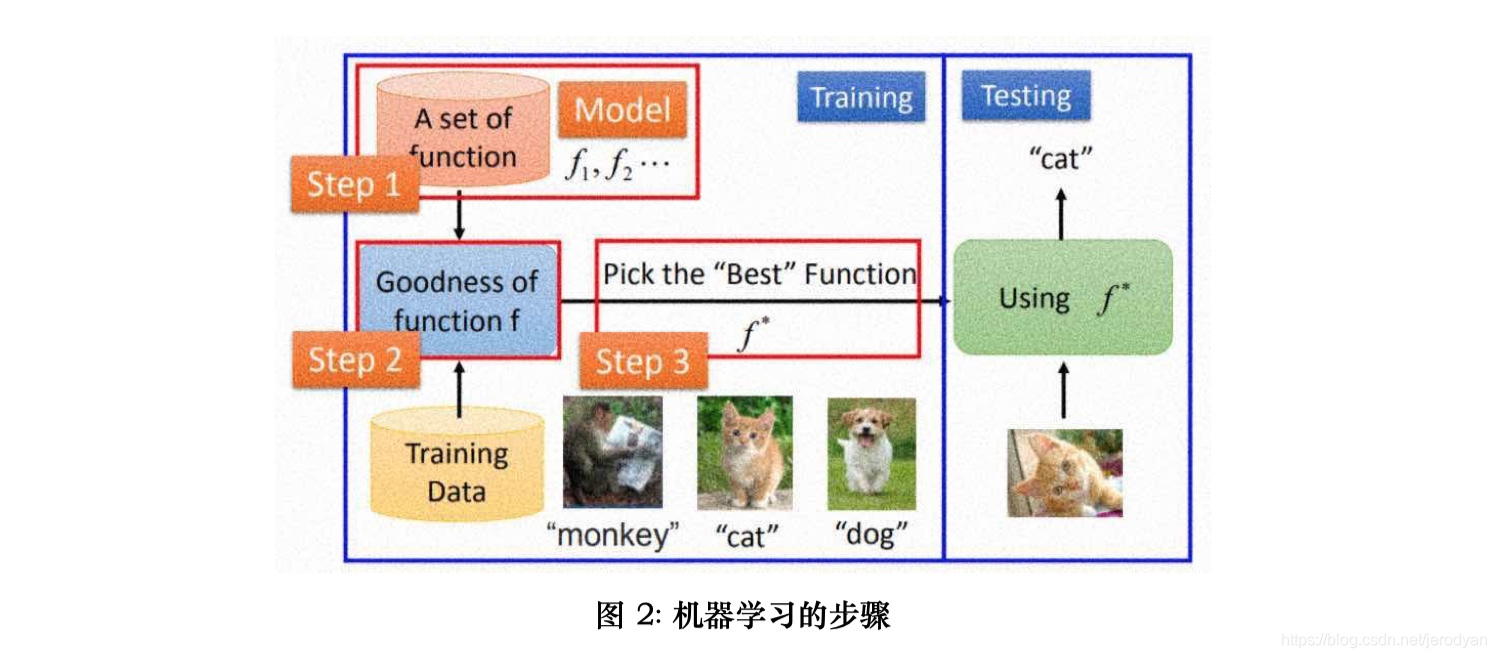
1.) 第一步,定义一个函数集合(Model, A set of functions)。这个集合中的每一 个元素都是一个有确定参数的函数。
2.) 第二步, 因为要在此函数集合中选一个函数, 所以要确定一个函数的挑选准 则(Goodness of function f)。
3.) 第三步, 在上述函数集合中, 根据挑选的准则以及训练数据(Training Data) 想办法找到那个最合适的函数(Pick the best function)。
4.) 第四步, 在测试数据(Testing Data)上测试, 测试刚刚找到的这个函数效 果。
前三步被称为训练(Training),最后一步称为测试(Testing)。
打个比方,把大象放到冰箱里,分为三个步骤:打开冰箱门, 把大象赶进去,关 上冰箱门。 这里,我们也是用三个步骤来搞定它。 当拿到一个任务,确定输入数据和 输出数据后,基本上可以确定大致的方向。 然后,要设计一个函数映射的集合。在这 个集合里, 各个元素函数看起来大模样都差不多, 只有参数的取值不一样。注意,这 个集合里包含的函数通常有无穷多个。 我们只能通过一个方法来描述这个函数,譬如 说一个方程或是一个拓扑结构。 接下来, 要确定一个准则来判断哪个函数好用。 因 为我们的目的是挑一个最合适的函数关系。 比如说,用训练数据的前提下,使得函数 映射输出值与标记值之间的误差最小。 最后,我们所要做的是,根据第二步设定好的 准则找到一组准确的参数取值。 当所有参数取值都确定下来的时候,一个合适的函数 映射关系也就找到了。 至此,训练过程也结束了。
通常,用深度学习方法来得到函数映射关系的形式, 其并不是一个传统意义上的 数学表达式或代数式。 它是一个用网络拓扑结构描述的函数映射关系。其参数数量一 般都是上百万个。 与之相对的,传统方法的映射函数所涉及的参数或系数数量级就小 得多。 一般就是几个,〸几个,上百个系数的都不多见。 这个设计函数集合的思路差 异,在初学的时候要特别注意。 而且,传统方法中的参数一般会有明确的意义, 或者 说设计者会去分析这些参数及系数的意义。 但是深度学习中的参数第一太多,没法分 析; 第二,好像大多也分析不出来什么意义。
当前学术界研究方向和工业界的应用, 也都是在这三个步骤中各自开展的。
1.) 有的聚焦于设计函数映射集合;
2.) 有的着重在设计判断准则,用来挑选函数映射关系;
3.) 有的将精力放在如何更快、更方便地训练,找到那个合适的函数。
无论在哪一个步骤中有技术进展,都会对任务的解决有帮助。 其实,在工作中, 如果最终实际应用效果不好(或称之为泛化能力不足), 你努力的方向可以从这三个 步骤中所涉及的内容来考虑,确定努力的方向。
005-机器学习背后的思维-针对入门小白的概念算法及工具的朴素思考
https://datawhalechina.github.io/leeml-notes/ ↩︎


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









