



本文系统介绍大模型应用开发全路径,涵盖部署、微调、Prompt工程、Agent开发等核心技术。重点详解langchain-chatchat与langchain框架下的Agent开发实践,提供完整代码示例与工具使用方法,帮助小白和程序员快速掌握大模型应用开发技能,构建增强型智能系统。
大模型相关目录
大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容
从0起步,扬帆起航。
- 大模型应用向开发路径及一点个人思考
- 大模型应用开发实用开源项目汇总
- 大模型问答项目问答性能评估方法
- 大模型数据侧总结
- 大模型token等基本概念及参数和内存的关系
- 大模型应用开发-华为大模型生态规划
- 从零开始的LLaMA-Factory的指令增量微调
- 基于实体抽取-SMC-语义向量的大模型能力评估通用算法(附代码)
- 基于Langchain-chatchat的向量库构建及检索(附代码)
- 一文教你成为合格的Prompt工程师
- 最简明的大模型agent教程
文章目录
一、Agent简介
大模型Agent是结合了大规模神经网络模型和自主计算实体的技术,它具备强大的表达、学习和交互能力,能够在无人干预的情况下,根据环境信息自主决策和控制行为。
简单而言之,agent是增强大模型能力的技术方案路径。主要包括:工具、工具选择方案,大模型工具应用3个部分。运行大体流程:
1用户给出一个任务(Prompt) -> 2思考(Thought) -> 3行动(Action) -> 4观察(Observation)
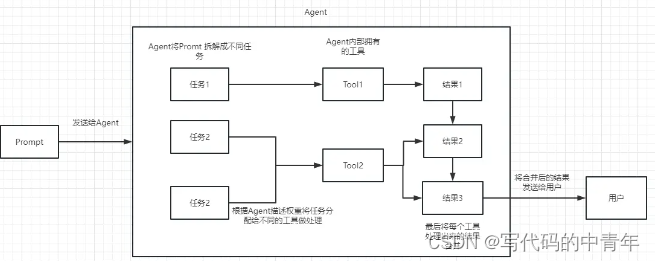
二、langchain-chatchat下的Agent开发
更详细地流程可参考GitHub wiki介绍
于tools_select.py预设新增的工具、工具描述等信息。
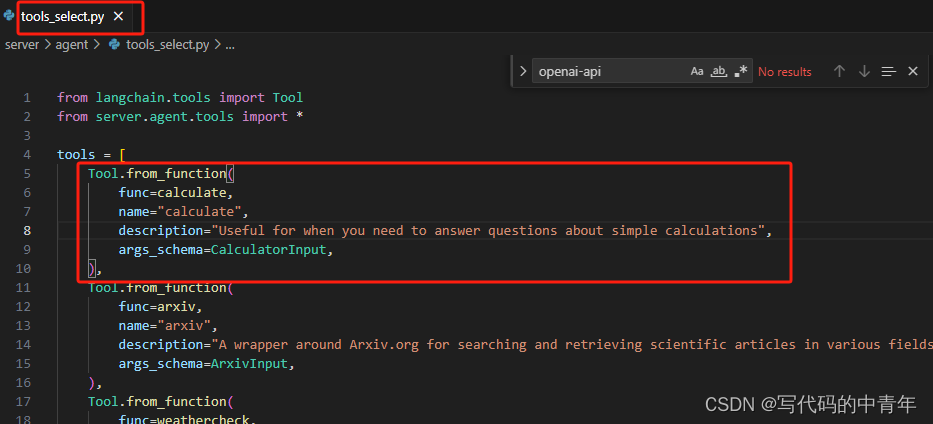
于下述路径下新增同名新工具py文件,并进行工具内容定义。
from pydantic import BaseModel, Field
import requests
from configs.kb_config import SENIVERSE_API_KEY
defweather(location:str, api_key:str):
url =f"https://api.seniverse.com/v3/weather/now.json?key={api_key}&location={location}&language=zh-Hans&unit=c"
response = requests.get(url)if response.status_code ==200:
data = response.json()
weather ={"temperature": data["results"][0]["now"]["temperature"],"description": data["results"][0]["now"]["text"],}return weather
else:raise Exception(f"Failed to retrieve weather: {response.status_code}")defweathercheck(location:str):return weather(location, SENIVERSE_API_KEY)classWeatherInput(BaseModel):
location:str= Field(description="City name,include city and county")
但我们仍不知道大模型、langchain框架选择工具、使用工具、进行输出等过程的调度原理,可参考如下代码:
from langchain.utilities import ArxivAPIWrapper
from langchain_experimental.tools import PythonAstREPLTool
from typing import Dict, Tuple
import os
import json
arxiv = ArxivAPIWrapper()
python=PythonAstREPLTool()classElectricityBillTool:defrun(self, name, start_date, end_date):# 假设这里执行了某些操作来查询电费# 为了简化,我们直接返回一条测试信息returnf"电费查询结果:姓名:{name}, 期间:{start_date} 到 {end_date}, 电费:100元"deftool_wrapper_for_model(tool, expects_kwargs=True):deftool_(args_json):
args = json.loads(args_json)if expects_kwargs:return tool.run(**args)# 使用 **args 将字典展开为关键字参数else:# 如果 run 方法期望位置参数,我们假设所有参数都聚合在一个叫 'query' 的键下return tool.run(args['query'])# 使用位置参数调用return tool_
electricity_bill_tool = ElectricityBillTool()# 以下是给模型看的工具描述:
TOOLS =[{'name_for_human':'arxiv','name_for_model':'Arxiv','description_for_model':'A wrapper around Arxiv.org Useful for when you need to answer questions about Physics, Mathematics, Computer Science, Quantitative Biology, Quantitative Finance, Statistics, Electrical Engineering, and Economics from scientific articles on arxiv.org.','parameters':[{"name":"query","type":"string","description":"the document id of arxiv to search",'required':True}],'tool_api': tool_wrapper_for_model(arxiv, expects_kwargs=False)},{'name_for_human':'python','name_for_model':'python','description_for_model':"A Python shell. Use this to execute python commands. When using this tool, sometimes output is abbreviated - Make sure it does not look abbreviated before using it in your answer. ""Don't add comments to your python code.",'parameters':[{"name":"query","type":"string","description":"a valid python command.",'required':True}],'tool_api': tool_wrapper_for_model(python, expects_kwargs=False)},{'name_for_human':'electricity_bill','name_for_model':'ElectricityBill','description_for_model':'查询电费工具,根据姓名、开始时间和结束时间查询电费。','parameters':[{"name":"name","type":"string","description":"姓名",'required':True},{"name":"start_date","type":"string","description":"开始时间",'required':True},{"name":"end_date","type":"string","description":"结束时间",'required':True}],'tool_api': tool_wrapper_for_model(electricity_bill_tool, expects_kwargs=True)}]
TOOL_DESC ="""{name_for_model}: Call this tool to interact with the {name_for_human} API. What is the {name_for_human} API useful for? {description_for_model} Parameters: {parameters} Format the arguments as a JSON object."""
REACT_PROMPT ="""Answer the following questions as best you can. You have access to the following tools:
{tool_descs}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can be repeated zero or more times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {query}"""defbuild_planning_prompt(TOOLS, query):
tool_descs =[]
tool_names =[]for info in TOOLS:
tool_descs.append(
TOOL_DESC.format(
name_for_model=info['name_for_model'],
name_for_human=info['name_for_human'],
description_for_model=info['description_for_model'],
parameters=json.dumps(
info['parameters'], ensure_ascii=False),))
tool_names.append(info['name_for_model'])
tool_descs ='\n\n'.join(tool_descs)
tool_names =','.join(tool_names)
prompt = REACT_PROMPT.format(tool_descs=tool_descs, tool_names=tool_names, query=query)return prompt
defparse_latest_plugin_call(text:str)-> Tuple[str,str]:
i = text.rfind('\nAction:')
j = text.rfind('\nAction Input:')
k = text.rfind('\nObservation:')if0<= i < j:# If the text has `Action` and `Action input`,if k < j:# but does not contain `Observation`,# then it is likely that `Observation` is ommited by the LLM,# because the output text may have discarded the stop word.
text = text.rstrip()+'\nObservation:'# Add it back.
k = text.rfind('\nObservation:')if0<= i < j < k:
plugin_name = text[i +len('\nAction:'):j].strip()
plugin_args = text[j +len('\nAction Input:'):k].strip()return plugin_name, plugin_args
return'',''defuse_api(tools, response):
use_toolname, action_input = parse_latest_plugin_call(response)if use_toolname =="":return"no tool founds"
used_tool_meta =list(filter(lambda x: x["name_for_model"]== use_toolname, tools))iflen(used_tool_meta)==0:return"no tool founds"
api_output = used_tool_meta[0]["tool_api"](action_input)return api_output
defget_model_response(prompt, stop):from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role":"user","content": prompt}],
stream=False,
stop = stop,)
response = completion.choices[0].message.content
return response
defmain(query, choose_tools):
prompt = build_planning_prompt(choose_tools, query)# 组织prompt
stop =["Observation:","Observation:\n"]print(prompt)
response = get_model_response(prompt, stop)while"Final Answer:"notin response:# 出现final Answer时结束
api_output = use_api(choose_tools, response)# 抽取入参并执行api
api_output =str(api_output)# 部分api工具返回结果非字符串格式需进行转化后输出if"no tool founds"== api_output:breakprint("\033[32m"+ response +"\033[0m"+"\033[34m"+' '+ api_output +"\033[0m")
prompt = prompt + response +' '+ api_output # 合并api输出
response = get_model_response(prompt, stop)print("\033[32m"+ response +"\033[0m")if __name__ =="__main__":
query ="查一下张三2024年1月的电费"# 所提问题
choose_tools = TOOLS # 选择备选工具print("="*10)
main(query, choose_tools)
三、langchain的Agent开发
主控:
prompt = get_tools_agent_prompt(query)
agent = get_tools_agent()
response = agent.run(prompt)
get_tools_agent_prompt:
defget_tools_agent_prompt(query, history=None):from datetime import datetime
current_time = datetime.now()
prompt =(f"""
如果查询未指定年/月,请参考当前时刻:{current_time}。
请用中文思考及回复。
优先考虑使用工具解决问题,当工具无法解决时,尝试根据经验直接回答。
最终回复时若内容较多需要注意保持可读性,添加合理的换行。
下面是用户问题:
"""+ query
)return prompt
get_tools_agent
defget_tools_agent():
llm = get_llm()
tools = get_tools()
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
max_iterations=5,
handle_parsing_errors=True,)return agent
# 获取llmdefget_llm():
api_key = os.getenv("PROXY_API_KEY")
api_url = os.getenv("PROXY_SERVER_URL")
api_url = api_url.split('/chat')[0]
model = os.getenv("PROXYLLM_BACKEND")if"openai"in api_url:
llm = ChatOpenAI(temperature=0,model=model,openai_api_base=api_url,openai_api_key=api_key,)elif"bigmodel"in api_url:
llm = ChatZhipuAI(temperature=0.01,api_key=api_key,model="glm-4",)elif"dashscope"in api_url:from langchain_community.chat_models.tongyi import ChatTongyi
llm = ChatTongyi(model="qwen-max",top_p=0.01,streaming=True,dashscope_api_key=api_key)return llm
defget_tools():
llm=get_llm()
tools =[
Tool(
name="查询负荷数据及同比环比",
func=calculate_growth,
description="""
当你想要查询某地负荷(最大值、最小值、平均值),查询最大/最小值发生时间,或者查询同比或环比变化的时候很有用,该工具返回某地负荷数据及同比变化率。
输入应该包括地区(公司)名(如果未指定,则默认为直供区)、时间(仅允许YYYY,YYYY-QQ,YYYY-MM,YYYY-MM-DD,YYYY-节气五种格式,也即年、年-季度、年-月、年-月-日,年-节气)、最大/最小/平均(若未明确提及,默认为平均)、同比/环比(可以不输入),以|分隔。
查询某一年时,仅输入年份即可。
例如:上海|2023|最大|环比、广州|2023-Q2|最小|环比、深圳|2021-07|平均、北京|2023-05-01|最大。
""",)]
tools.append(
Tool(
name="查询负荷新高(低)",
func=find_record_breaking_loads,
description="""
当你想要查询某地负荷几创新高或几创新低的时候很有用,该工具返回创下新高/低的次数,及对应的详细信息。
输入应该包括地区(公司)名(如果未指定,则默认为直供区)、基础时间(仅允许YYYY,YYYY-QQ,YYYY-MM,YYYY-MM-DD,YYYY-节气五种格式,也即年、年-季度、年-月、年-月-日,年-节气)、对比时间(如未指定,默认与基础时间的前一年做对比,时间类型同前者)、高/低,以|分隔。
例如:上海|2023-Q1|2022-Q1|高、广州|2023-寒露|2021-寒露|低、深圳|2023|2021|高。
""",),)return tools
defcalculate_growth(context):# 读取CSV文件# df = pd.read_csv('./data/load.csv')# 分割输入参数
params = context.split("|")# 确保至少有三个参数iflen(params)<3:return"至少需要三个参数(region, time_period, compare_type)。"# 提取参数,如果缺少第四个参数,则默认为"同比"eliflen(params)==3:
region, time_period, compare_type = params[:3]
growth_type =Noneeliflen(params)==4:
region, time_period, compare_type, growth_type = context.split("|")else:return"您输入的参数数量不匹配,请仔细核对。"
deffind_record_breaking_loads(context):# 分割输入参数
params = context.split("|")iflen(params)notin[3,4]:return"您输入的参数数量不匹配,请仔细核对。"
region = params[0]
current_time_period = params[1]
high_low = params[-1]# compare_time_period = params[2] if len(params) == 4 else None
compare_time_period = params[2]iflen(params)==4elsestr(int(params[1][:4])-1)+ params[1][4:]# 筛选指定地区的数据
df_region = df[df['公司']== region]# 解析当前时间段try:
current_period_parsed = parse_time_period(df, current_time_period)except ValueError as e:returnf"当前时间段解析错误:{e}"# 解析对比时间段,如果有if compare_time_period:try:
compare_period_parsed = parse_time_period(df, compare_time_period)except ValueError as e:returnf"对比时间段解析错误:{e}"else:
compare_period_parsed =None# 根据时间段获取数据ifisinstance(current_period_parsed,tuple):
current_start_date, current_end_date = current_period_parsed
df_current = df_region[(df_region['时间']>= current_start_date)&(df_region['时间']< current_end_date)]if compare_period_parsed:
compare_start_date, compare_end_date = compare_period_parsed
df_compare = df_region[(df_region['时间']>= compare_start_date)&(df_region['时间']< compare_end_date)]else:# 默认比较去年同期
year =int(current_start_date.split('-')[0])
previous_year = year -1
df_compare = df_region[(df_region['时间']>=f"{previous_year}-{current_start_date[5:]}")&(df_region['时间']<f"{previous_year}-{current_end_date[5:]}")]# 比较负荷值if high_low =='高':
reference_load = df_compare['负荷'].max()else:
reference_load = df_compare['负荷'].min()# 计算创纪录的次数if high_low =='高':
df_records = df_current[df_current['负荷']> reference_load]else:
df_records = df_current[df_current['负荷']< reference_load]# 结果处理ifnot df_records.empty:
record_count =len(df_records)
top_record = df_records.sort_values(by="负荷", ascending=(high_low !='高')).iloc[0]returnf"{region}在{current_time_period}相较{compare_time_period}共有{record_count}次创下新{high_low},其中最{high_low}负荷为{top_record['负荷']}MW,时间为{top_record['时间']}。"else:returnf"{region}在{current_time_period}相较{compare_time_period}未创新{high_low}。"
最后介绍一下 AgentType.ZERO_SHOT_REACT_DESCRIPTION
首先介绍一些常见的关键词:
ReAct:由单词“Reason”和“Act”组合而成,前者对应于推理,即大模型的通用文本逻辑判断能力,或者说是对问题进行思考和拆解的能力;后者对应于行动,即具备专业知识的特定领域精确回答能力,或者说是调用外部工具的能力。ReAct顾名思义就是把思考和行动相结合,通过二者的依次迭代执行完成任务。
Zero-shot:零样本,或者说是无记忆。在运行时,只考虑与当前代理的一次交互,不保留对话历史。
Conversational:引入了对话历史,因为有记忆了,所以需要初始化代理时引入memory参数。其一个缺点是可能无法执行复杂的Tool调用任务。
Chat:常规情况下以OpenAI方式初始化LLM,此类Agent可以以ChatOpenAI方式初始化模型。前者是更通用的接口,用于与不同类型的语言模型进行交互,可以与各种LLM模型集成。ChatOpenAI接口是对其的高级封装,更专注于对话式交互。

以上内容转自:https://wangjn.blog.youkuaiyun.com/article/details/134806188
ZERO_SHOT_REACT_DESCRIPTION通常使用
杂的Tool调用任务。
Chat:常规情况下以OpenAI方式初始化LLM,此类Agent可以以ChatOpenAI方式初始化模型。前者是更通用的接口,用于与不同类型的语言模型进行交互,可以与各种LLM模型集成。ChatOpenAI接口是对其的高级封装,更专注于对话式交互。
[外链图片转存中…(img-6baLnFpe-1761885764151)]
以上内容转自:https://wangjn.blog.youkuaiyun.com/article/details/134806188
ZERO_SHOT_REACT_DESCRIPTION通常使用
其他的都作妖
可能大家都想学习AI大模型技术,也_想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习_,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。
为了帮助大家打破壁垒,快速了解大模型核心技术原理,学习相关大模型技术。从原理出发真正入局大模型。在这里我和MoPaaS魔泊云联合梳理打造了系统大模型学习脉络,这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码免费领取🆓**⬇️⬇️⬇️

【大模型全套视频教程】
教程从当下的市场现状和趋势出发,分析各个岗位人才需求,带你充分了解自身情况,get 到适合自己的 AI 大模型入门学习路线。
从基础的 prompt 工程入手,逐步深入到 Agents,其中更是详细介绍了 LLM 最重要的编程框架 LangChain。最后把微调与预训练进行了对比介绍与分析。
同时课程详细介绍了AI大模型技能图谱知识树,规划属于你自己的大模型学习路线,并且专门提前收集了大家对大模型常见的疑问,集中解答所有疑惑!

深耕 AI 领域技术专家带你快速入门大模型
跟着行业技术专家免费学习的机会非常难得,相信跟着学习下来能够对大模型有更加深刻的认知和理解,也能真正利用起大模型,从而“弯道超车”,实现职业跃迁!

【精选AI大模型权威PDF书籍/教程】
精心筛选的经典与前沿并重的电子书和教程合集,包含《深度学习》等一百多本书籍和讲义精要等材料。绝对是深入理解理论、夯实基础的不二之选。

【AI 大模型面试题 】
除了 AI 入门课程,我还给大家准备了非常全面的**「AI 大模型面试题」,**包括字节、腾讯等一线大厂的 AI 岗面经分享、LLMs、Transformer、RAG 面试真题等,帮你在面试大模型工作中更快一步。
【大厂 AI 岗位面经分享(92份)】

【AI 大模型面试真题(102 道)】

【LLMs 面试真题(97 道)】

【640套 AI 大模型行业研究报告】

【AI大模型完整版学习路线图(2025版)】
明确学习方向,2025年 AI 要学什么,这一张图就够了!

👇👇点击下方卡片链接免费领取全部内容👇👇
抓住AI浪潮,重塑职业未来!
科技行业正处于深刻变革之中。英特尔等巨头近期进行结构性调整,缩减部分传统岗位,同时AI相关技术岗位(尤其是大模型方向)需求激增,已成为不争的事实。具备相关技能的人才在就业市场上正变得炙手可热。
行业趋势洞察:
- 转型加速: 传统IT岗位面临转型压力,拥抱AI技术成为关键。
- 人才争夺战: 拥有3-5年经验、扎实AI技术功底和真实项目经验的工程师,在头部大厂及明星AI企业中的薪资竞争力显著提升(部分核心岗位可达较高水平)。
- 门槛提高: “具备AI项目实操经验”正迅速成为简历筛选的重要标准,预计未来1-2年将成为普遍门槛。
与其观望,不如行动!
面对变革,主动学习、提升技能才是应对之道。掌握AI大模型核心原理、主流应用技术与项目实战经验,是抓住时代机遇、实现职业跃迁的关键一步。

01 为什么分享这份学习资料?
当前,我国在AI大模型领域的高质量人才供给仍显不足,行业亟需更多有志于此的专业力量加入。
因此,我们决定将这份精心整理的AI大模型学习资料,无偿分享给每一位真心渴望进入这个领域、愿意投入学习的伙伴!
我们希望能为你的学习之路提供一份助力。如果在学习过程中遇到技术问题,也欢迎交流探讨,我们乐于分享所知。
*02 这份资料的价值在哪里?*
专业背书,系统构建:
-
本资料由我与MoPaaS魔泊云的鲁为民博士共同整理。鲁博士拥有清华大学学士和美国加州理工学院博士学位,在人工智能领域造诣深厚:
-
- 在IEEE Transactions等顶级学术期刊及国际会议发表论文超过50篇。
- 拥有多项中美发明专利。
- 荣获吴文俊人工智能科学技术奖(中国人工智能领域重要奖项)。
-
目前,我有幸与鲁博士共同进行人工智能相关研究。

内容实用,循序渐进:
-
资料体系化覆盖了从基础概念入门到核心技术进阶的知识点。
-
包含丰富的视频教程与实战项目案例,强调动手实践能力。
-
无论你是初探AI领域的新手,还是已有一定技术基础希望深入大模型的学习者,这份资料都能为你提供系统性的学习路径和宝贵的实践参考,助力你提升技术能力,向大模型相关岗位转型发展。



抓住机遇,开启你的AI学习之旅!


















 759
759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











