



为了满足数据中心算力需求,谷歌在 2014 年开始研发基于特定领域架构(Domain-specific Architecture,DSA)的 TPU(Tensor Processing Unit),专门为深度学习任务设计的定制硬件加速器,加速谷歌的机器学习工作负载,特别是训练和推理大模型。
David Patterson(大卫·帕特森)是计算机体系结构领域科学家,自 1976 年起担任加州大学伯克利分校的计算机科学教授并在 2016 年宣布退休,在 2017 年加入谷歌 TPU 团队,2020 年在加州大学伯克利分校发表演讲《A Decade of Machine Learning Accelerators:Lessons Learned and Carbon Footprint》,分享了 TPU 近几年的发展历程以及心得体会,本文主要摘录并深入探讨其中的 8 点思考。
模型对内存和算力的需求
AI 模型近几年所需的内存空间和算力平均每年增长 50%,模型所需内存和算力增长大约 10~20 倍。但是芯片设计到实际应用需要一定的周期,其中芯片设计需要 1 年,部署需要 1 年,实际使用并优化大约需要 3 年,因此总共需要 5 年时间。
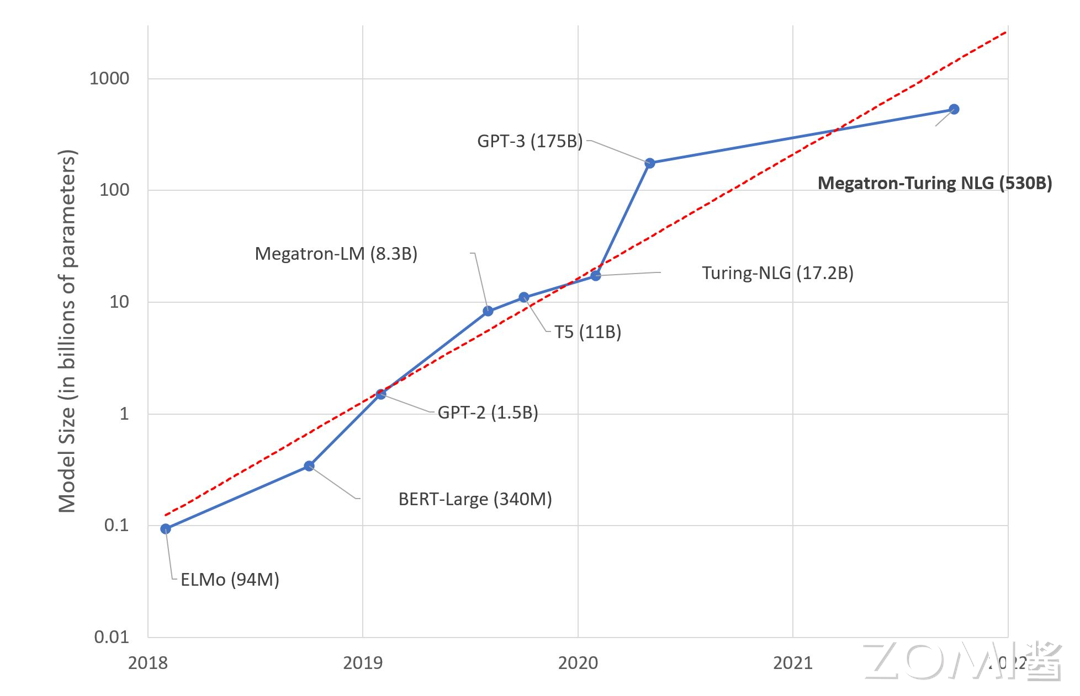
训练模型参数量的增长速度比推理模型更快,2016-2023 年,SOTA 训练模型的算力需求年均增长 10 倍,GPT-2 模型的参数量从 15 亿增长到 GPT-3 1750 亿,提高了 100 倍。
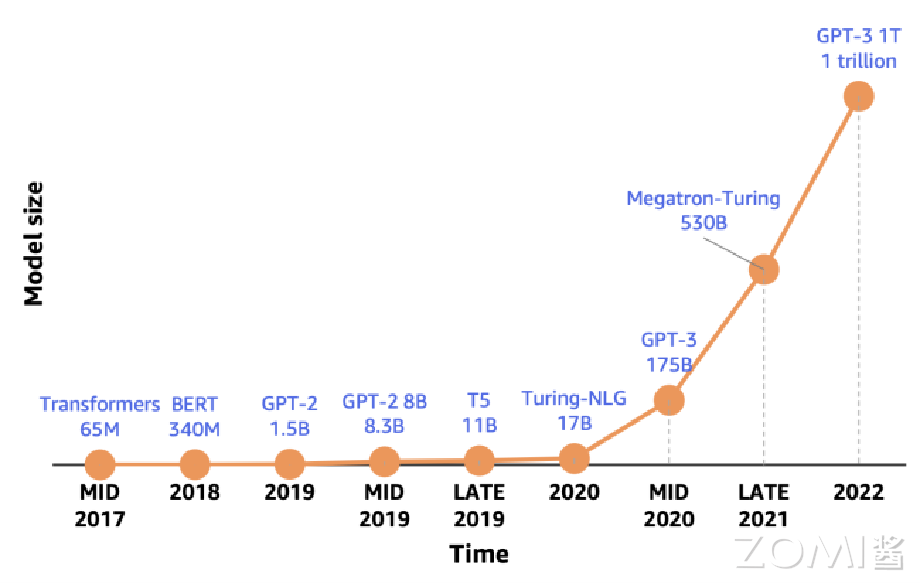
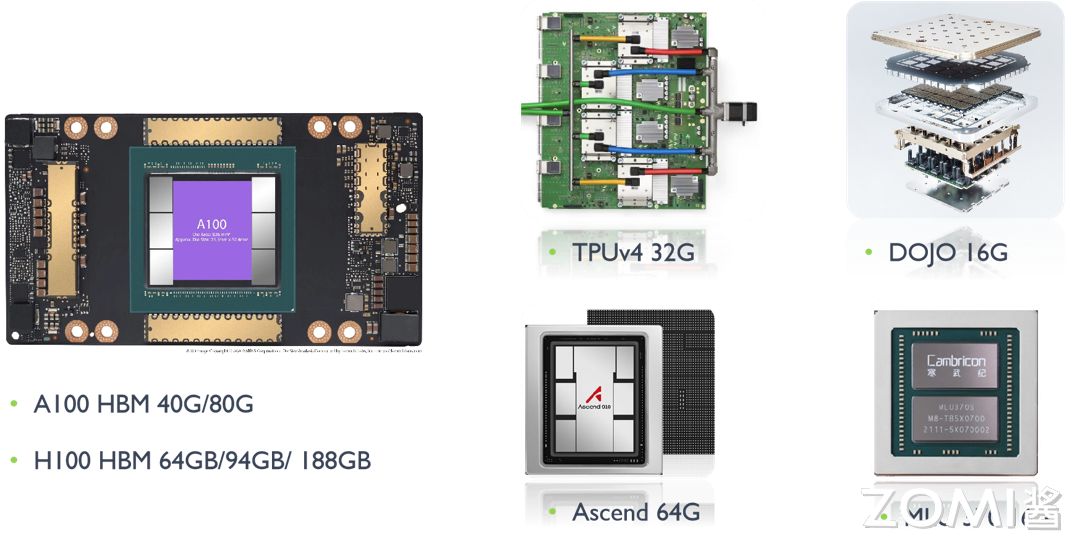
但是 AI 芯片的内存容量增长相比来说就比较缓慢,A100 的 HBM 最大内存是 80 G,H100 最大内存是 188 G,谷歌 TPU v5 内存是 32 G,特斯拉 DOJO 内存是 16 G,华为昇腾内存是 64 G,寒武纪 MLU 370 内存是 16 G。
模型结构快速演变
深度神经网络(DNN)是一个发展迅速的领域,2016 年 MLP(Multilayer Perceptron,多层感知器)和 LSTM(Long Short-Term Memory,长短期记忆网络)是主流的神经网络模型,2020 年 CNN(Convolutional Neural Network,卷积神经网络)、RNN(Recurrent Neural Network,循环神经网络)和 BERT(Bidirectional Encoder Representations from Transformers)被广泛应用。
大型语言模型(Large Language Model,LLM)基于 transformer,参数规模从五年前的仅有十亿参数(例如 GPT-2 的 1.5B 参数)稳步增长到如今的万亿参数,例如 OpenAI 的 GPT-3.5、微软的 Phi-3、谷歌的 Gemma、Meta 的 Llamma 等,未来可能会出现新的网络模型,因此 DSA 架构需要足够通用以支持新的模型。
生产部署提供多租户
大部分 AI 相关论文假设同一时间 NPU 只需运行一个模型。实际应用需要切换不同模型:
- 机器翻译涉及语言对比,因此需要使用不同的模型;
- 用一个主模型和配套多个模型进行实验;
- 对吞吐量和延迟有不同要求,不同模型使用不用 batch size。
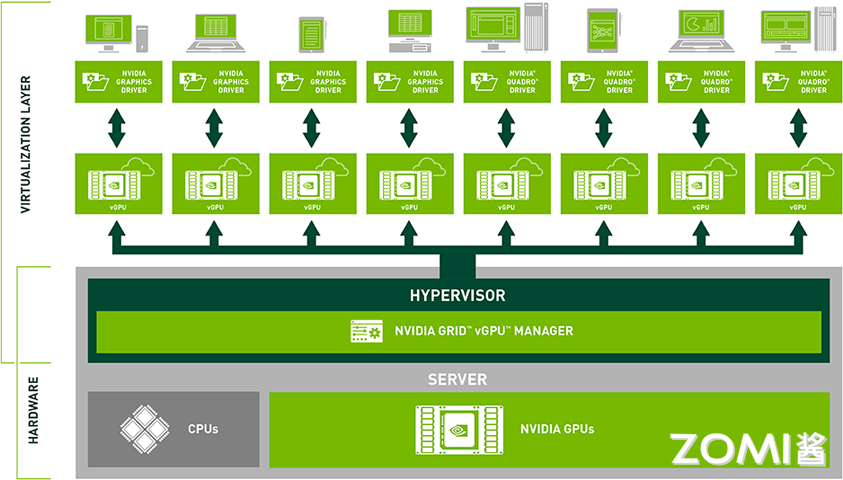
因此需要多租户技术(Multi-tenancy)实现算力切分、显存虚拟化、内存寻址、虚拟内存页等技术。GPU 虚拟化技术可以将物理 GPU 资源虚拟化为多个逻辑 GPU 资源,使多个用户或应用程序能够共享同一块物理 GPU 而不会相互干扰。这种技术可以提高 GPU 资源的利用率和性能,并且能够为不同用户提供独立的 GPU 环境,增强系统的安全性和隔离性。目前常见的 GPU 虚拟化技术包括 NVIDIA vGPU、AMD MxGPU 以及 Intel GVT-g 等虚拟化方案。
SRAM 与 DRAM 的权衡
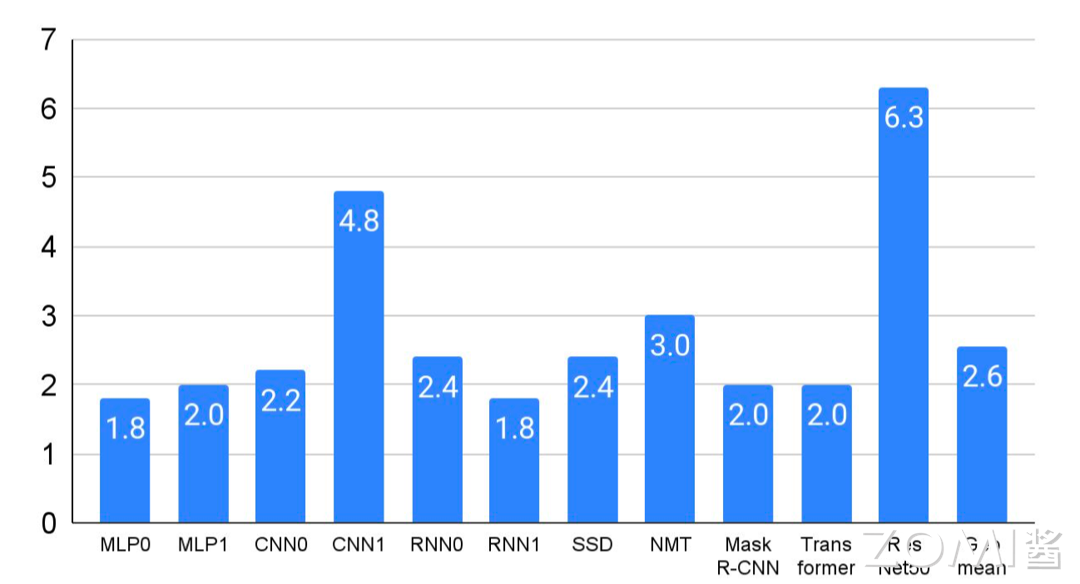
通过统计 8 个模型的基准数据,其中有 6 个模型涉及到多租户技术。如果从 CPU 主机重新加载参数,上下文切换需要 10 秒,因此需要更快的 DRAM(片外存储)用来交换多种模型的数据。
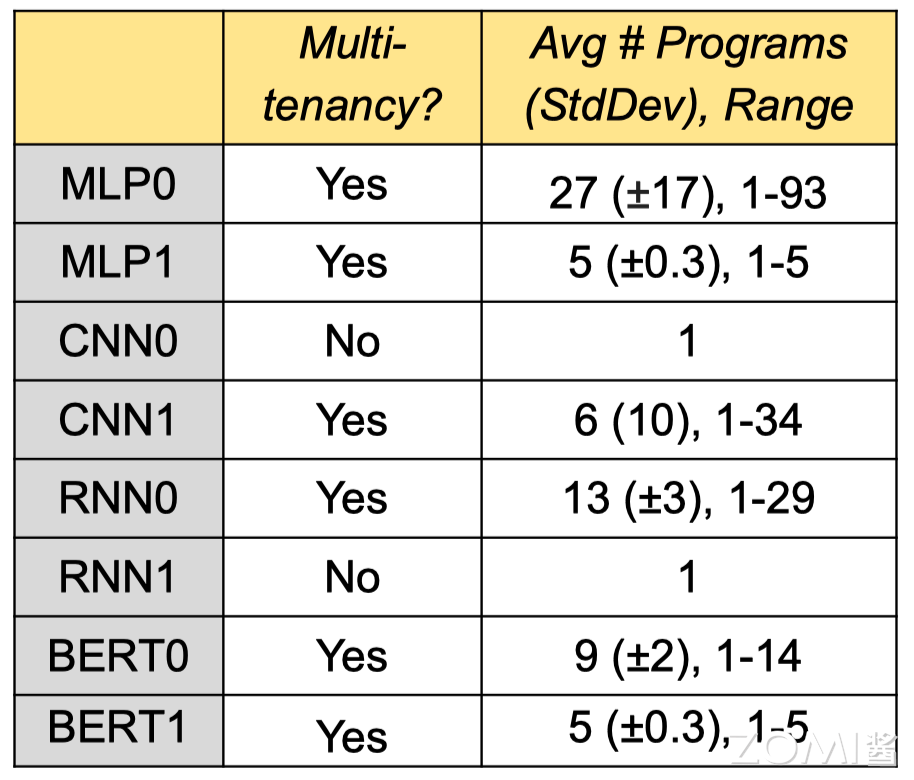
红色虚线表示单芯片的最大 SRAM(片上存储),而实际情况下不少模型需要的内存远大于此。部分芯片的设计思路是期望利用 SRAM 解决所有任务,减少内存数据搬运的时间,但是在多租户场景下很难实现。所以 AI 芯片不仅需要更大的 SRAM 片上存储内存空间,更需要存储速度更快的片外存储 DRAM。
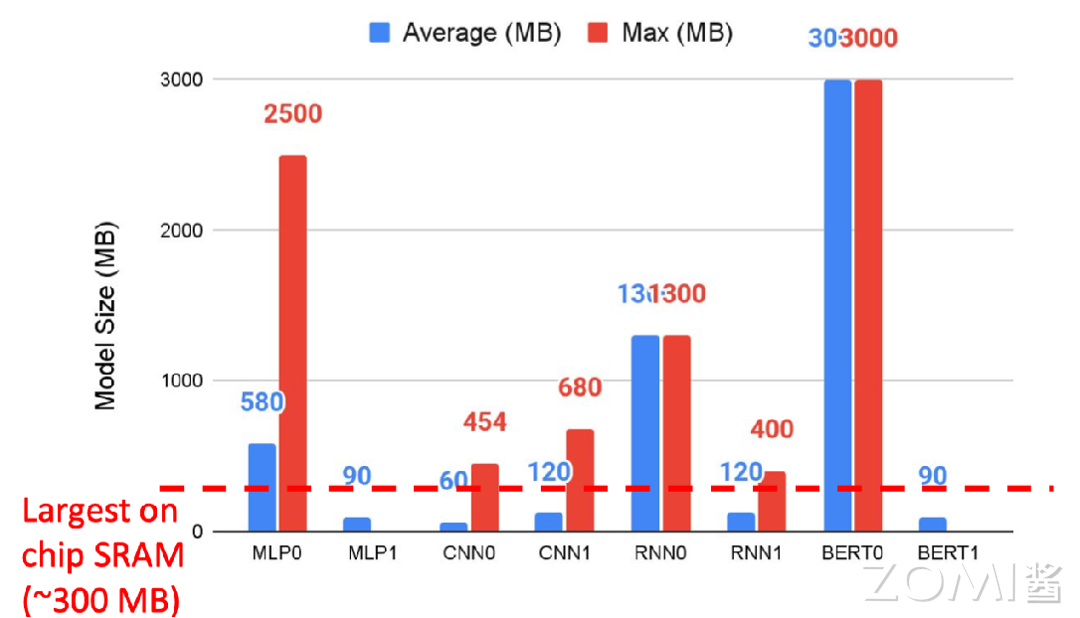
内存比非算力重要
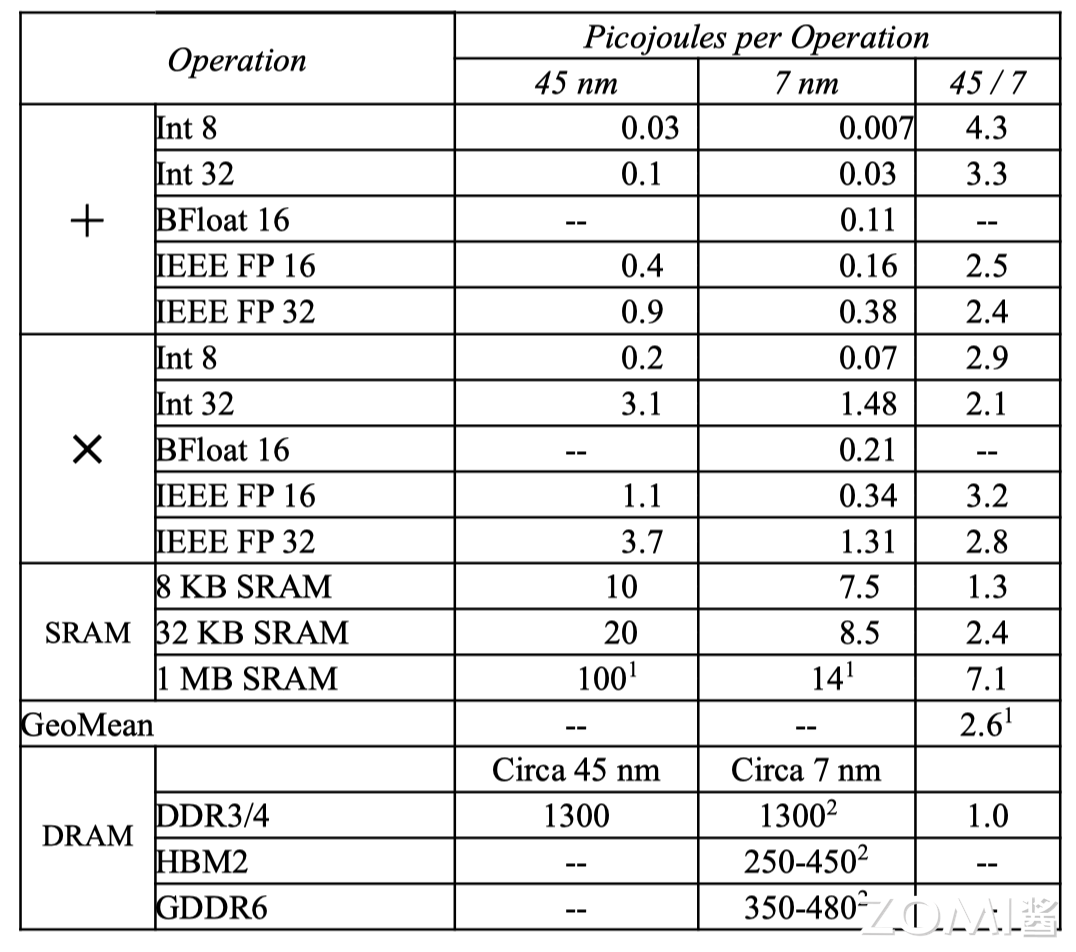
现代微处理器最大的瓶颈是能耗,而不是芯片集成度,访问片外 DRAM 需要的能耗是访问片上 SRAM 的 100 倍,是算术运算能耗的 5000 ~ 10,000 倍。因此 AI 芯片通过增加浮点运算单元(FPU)来分摊内存访问开销。AI 芯片开发者一般通过减少浮点运算数 FLOPs 来优化模型,减少内存访问是更有效的办法,GPGPU 的功耗大多浪费在数据搬运上,而非核心计算,而优化数据流正是 AI 芯片的核心价值。
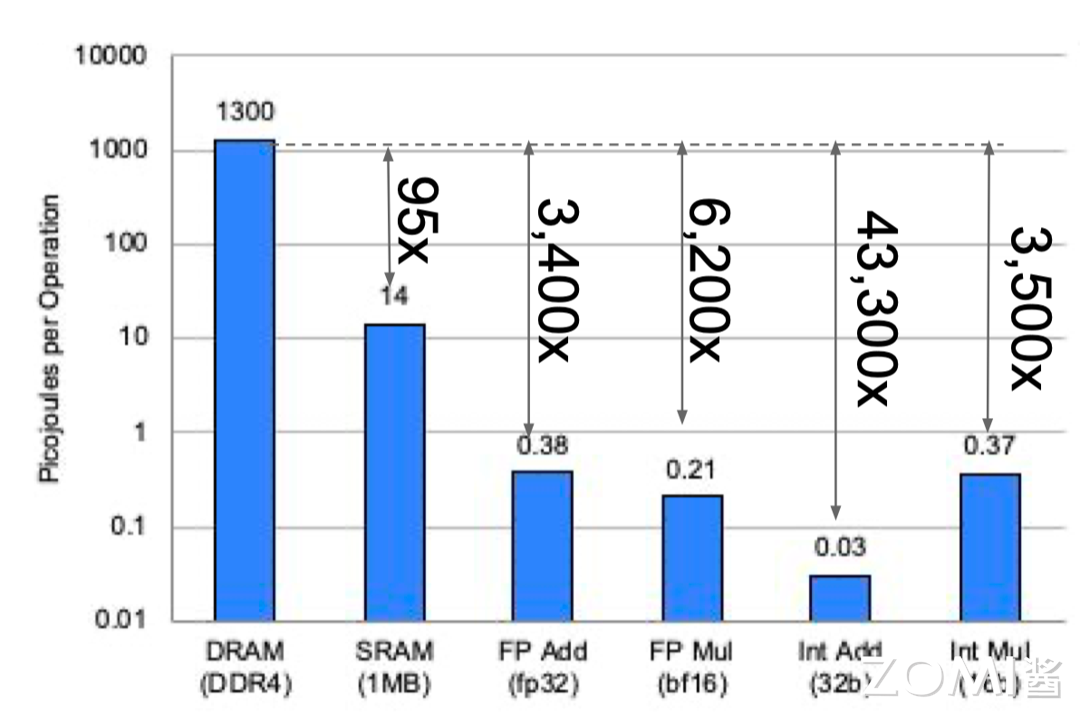
英伟达 Ampere 架构使用第三代 Tensor Core,使不同的 Warp 线程组更好地访问多级缓存。Ampere 架构 Tensor Core 的一个 warp 中有 32 个线程共享数据,而 Volta 架构 Tensor Core 只有 8 个线程,更多的线程之间共享数据,可以更好地在线程间减少矩阵的数据搬运。
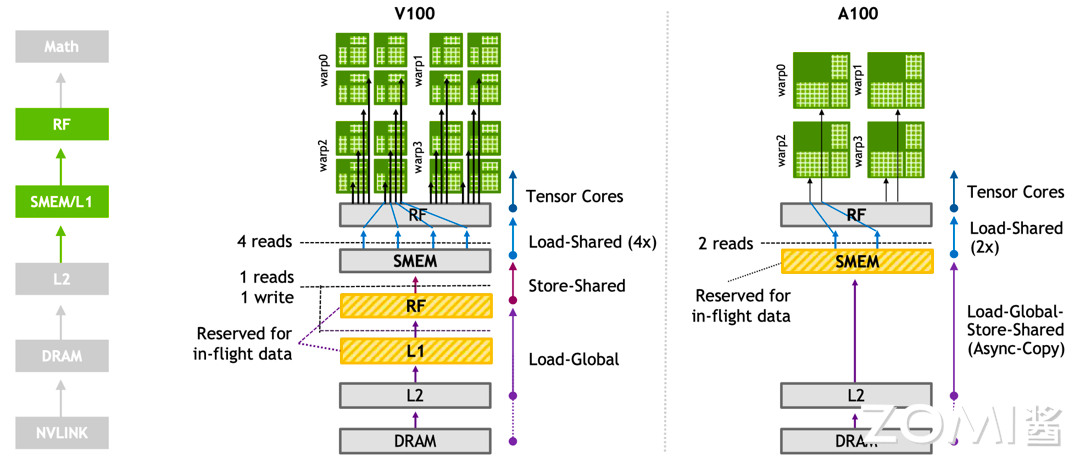
谷歌 TPU v1 有 65536 (256x256)个矩阵乘法单元(Matrix Multiply Unit),时钟周期是 700 MHz,在其中做了专门的数据流编排,从而使数据可以流动地更快,快速地传输给计算单元进行计算。峰值算力达到 92 T Operations/s(65,000×2×700M ≈ 90 TeraOPS),Accumulator 内存大小是 4 MB,Activation Storage 内存大小是 24 MB。
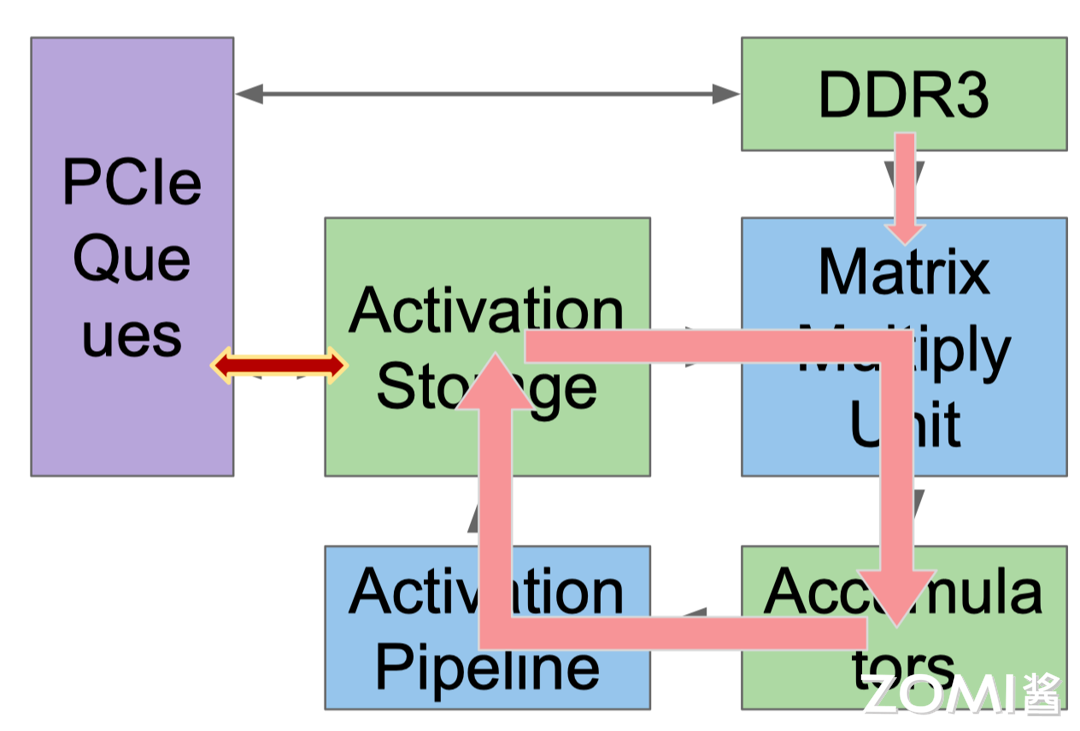
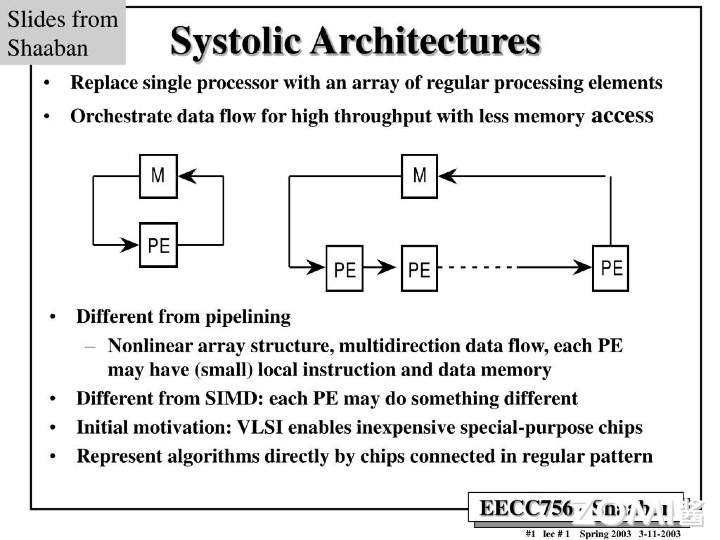
TPU 使用脉动阵列(systolic array),以固定时间间隔使数据从不同方向流入阵列中的处理单元,最后将数据累积,以完成大型矩阵乘法运算。在 70 年代的芯片只有单金属层,不能很好地实现互连,Kung 和 Leiserson 提出”脉动阵列“以减少布线,简化连接。如今芯片多达 10 个金属层,最大难点是能耗,脉动阵列能效高,使用脉动阵列可以使芯片容纳更多乘法单元,从而分摊内存访问开销。
DSA 既要专业也要灵活
DSA 难点在于既要对模型进行针对性的优化,同时还须保持一定的灵活性。训练之所以比推理更加复杂,是因为训练的计算量更大,包含反向传播、转置和求导等运算。训练时需要将大量运算结果储存起来用于反向传播的计算,因此也需要更大的内存空间。
此外,支持更加广泛的计算数据格式(如 BF16、FP16、HF32)用于 AI 计算,指令、流水、可编程性也更高,需要灵活的编译器和上层软硬件配套,CUDA 在这个方面已经积累了很多年,TPU 逐渐支持了 INT8、BFloat16 等。
半导体供应链的选型
计算逻辑的进步速度很快,但是芯片布线(制程工艺)的发展速度则较慢。SRAM 和 HBM 比 DDR4 和 GDDR6 速度更快,能效更高,因此 AI 芯片需要根据数据的操作格式选用一定的存储设备。在大模型训练过程中普遍使用 BF16,部分会使用 FP8 进行推理,如果选型有问题,比如只能用 FP32 模拟 BF16,将减慢大模型训练迭代的速度。
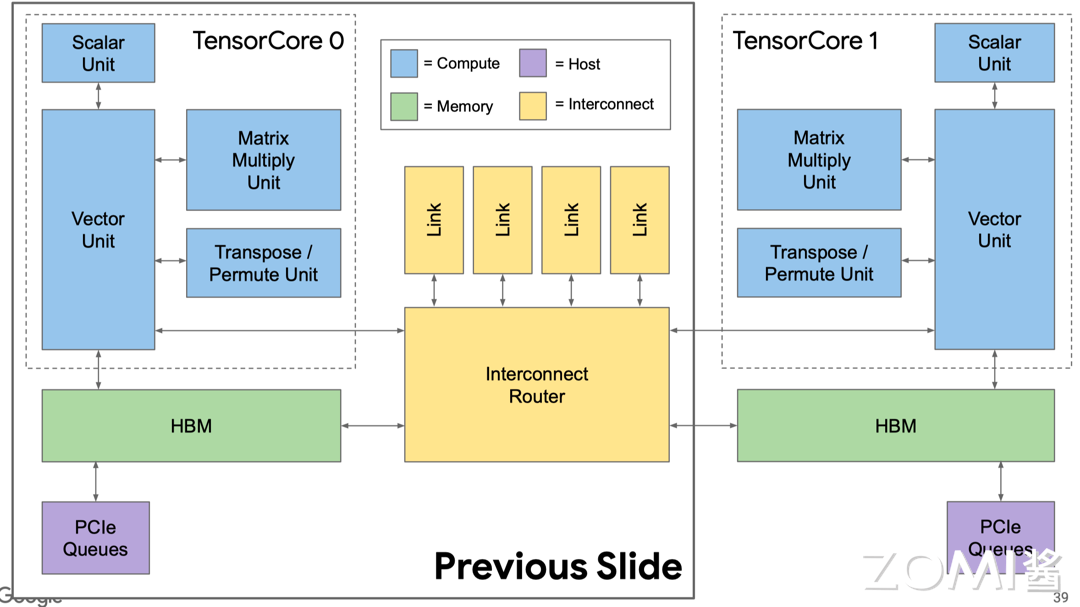
TPU v2 中有两个互连的 Tensor Core,更加方便布线,同时对编译器也更加友好。
编译器优化和 AI 应用兼容
DSA 的编译器需要对 AI 模型进行分析和优化,通过编译器把 AI 使用的指令转换为高效的底层代码,以便在特定硬件上运行时能够更快地执行,充分发挥硬件的性能,具体可分为与机器无关高级操作和与相关低级操作,从而提供不同维度的优化 API 和 PASS(LLVM 编译器所采用的一种结构化技术,用于完成编译对象(如 IR)的分析、优化或转换等功能)。
目前编译器维度比较多,有类似于 CUDA 提供编程体系,有类似于 TVM(深度学习编译器)和 XLA(加速线性代数)提供编译优化,包括对计算图进行图优化、内存优化、并行化、向量化等操作,以提高模型的执行速度和减少资源消耗,优化的具体方式如下:
- 实现 4096 个芯片的多核并行;
- 向量、矩阵、张量等功能单元的数据级并行;
- 322~400 位 VLIW(Very Long Instruction Word)指令集的指令级并行,一条指令可以同时包含多个操作,这些操作可以在同一时钟周期内并行执行;
- 编译优化取决于软硬件能否进行缓存,编译器需要管理内存传输;
- 编译器能够兼容不同功能单元和内存中的数据布局(如 Trans data)。
实际上可以通过算子融合(Operator Fusion)减少内存,从而优化性能。例如可以将矩阵乘法与激活函数进行融合,省略将中间结果写入 HBM 之后再读取出来的步骤,通过 MLPerf 基准测试结果可知,算子融合平均可以带来超过两倍的性能提升。
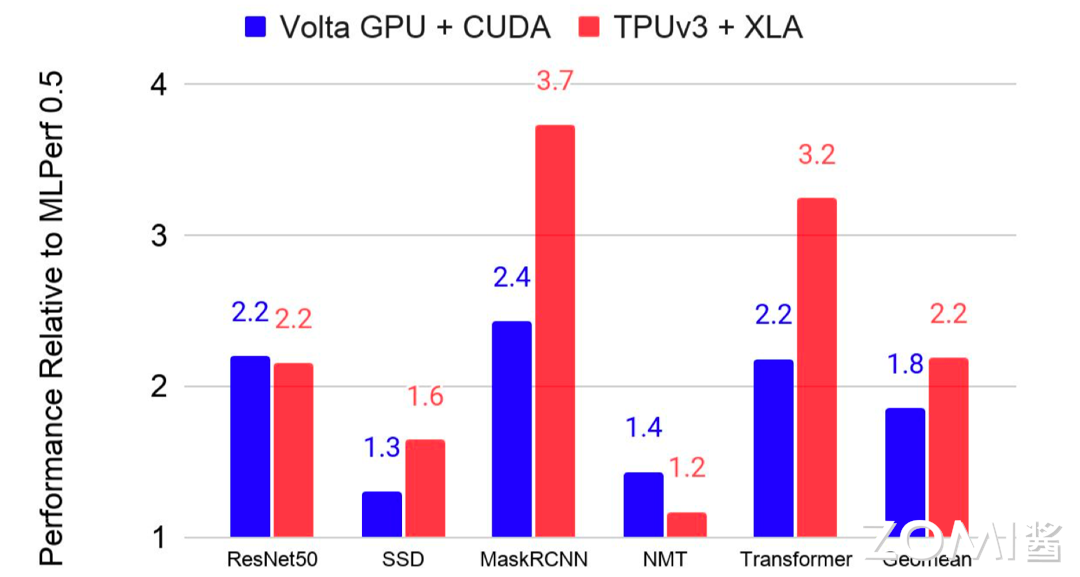
与 CPU 中的 GCC 和 NVIDIA GPU CUDA 相比,DSA 的软件栈还不够成熟。但是编译器优化能够带来更好的性能提升,蓝色表示使用 GPU,红色表示使用 TPU,通过编译器优化后模型的性能大约有 2 倍提升提升。对于 C++编译器而言,能在一年内把性能提升 5%-10%已经算是达到很好的效果了。
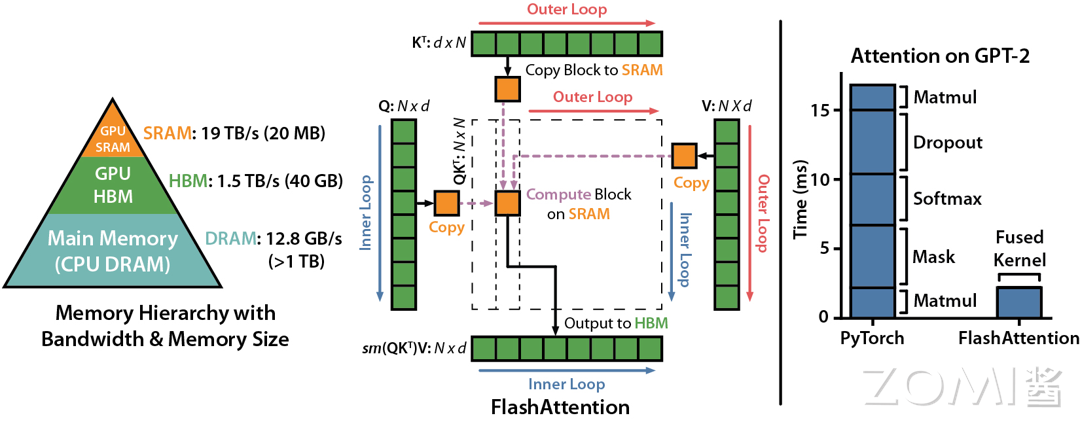
当输入序列(sequence length)较长时,Transformer 的计算过程缓慢且耗费内存。Flash Attention(FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness(FlashAttention:一种具有 IO 感知,且兼具快速、内存高效的新型注意力算法))是 GPT-3.5 中引入的一种注意力机制,是一种改进的自注意力机制,它重新排序了注意力计算的顺序,以提高处理长序列数据时的效率。
GPU 中存储单元主要有 HBM 和 SRAM,HBM 容量大但是访问速度慢,SRAM 容量小却有着较高的访问速度。GPU SRAM 的读写(I/O)的速度为 19 TB/s 和 GPU HBM 的读写(I/O)速度相差十几倍,而对比存储容量也相差了好几个数量级。
FlashAttention 通过减少 GPU 内存读取/写入,运行速度比 PyTorch 标准注意力快 2-4 倍,所需内存减少 5-20 倍。而且 Flash Attention 的计算是从 HBM 中读取块,在 SRAM 中计算之后再写到 HBM 中,因此想避免从 HBM 里读取或写入注意力矩阵。算法没有减少计算量,而是从 IO 感知出发,减少 HBM 访问次数,从而减少了计算时间。
- [](javascript:;)赞
- [](javascript:;)收藏
- [](javascript:;)评论
- [](javascript:;)分享
- [](javascript:;)举报
下一篇:【AI系统】AI芯片驱动智能革命

提问和评论都可以,用心的回复会被更多人看到 评论
发布评论
全部评论 () 最热 最新
相关文章
-
[
AI思考路径可视化!ReasonGraph:这款开源工具让AI的"思考"一目了然!
目前主流的大语言模型都陆续推出了自己的推理模型,思考过程也挺丰富的,但是它往往也是一长串文本,有时候很难直观的理解推理路径。长篇文字输出让用户难以快速抓住重点,更别提检测潜在的错误或改进模型表现。现在,有一款名为 ReasonGraph 的开源工具横空出世,它将 AI 的思考过程转化为清晰的可视化图表,让推理路径变得清晰易懂。它不仅能将 LLM 的推理路径可视化,还支持实时更新
](https://blog.51cto.com/u_16170893/13576811)
推理过程 SVG 开源工具
-
[
【AI系统】AI的领域、场景与行业应用
在本篇文章中,我们将深入探讨人工智能(AI)的起源、现状以及理论基础,为读者提供一个全面的理解框架。I. 引言 人工智能(AI)作为一门跨学科的研究领域,其目标是模拟、延伸和扩展人的智能。本文旨在概述AI的历史发展、当前趋势以及理论基础,为读者提供一个系统的视角。II. AI的发展历程 AI的历史可以追溯到20世纪中叶,当时科学家们开始探索如何构建能够模拟人类智能的机器。从早期的逻辑推理和问题解决
](https://blog.51cto.com/u_17040849/12206818)
神经网络 理论基础 深度学习 人工智能 AI
-
[
一文读懂:国产AI芯片与英伟达的差距有多大?
各位小伙伴们,大家好哈。今天我们来聊聊AI芯片的算力。算力时代,AI算力的重要性不言而喻。而AI算力的核心命脉——AI芯片,已成为全球科技竞逐的焦点。但最近,美国对华的芯片禁令限制使得中国企业面临算力供应的不确定性,随着美国进一步限制AI芯片对中国销售,NVIDIA只能进一步阉割芯片性能来为中国定制AI芯片。那么,目前国内的AI芯片发展如何呢?国产AI芯片是否像他们宣称的一样,性能已经可以媲美NV
](https://blog.51cto.com/u_16885734/13963381)
英伟达 CUDA 开发者
-
[
【AI系统】从 CUDA 对 AI 芯片思考
从技术的角度重新看英伟达生态,有很多值得借鉴的方面。本文将主要从流水编排、SIMT 前端、分支预测和交互方式等方面进行分析,同时对比 DSA 架构,思考可以从英伟达 CUDA 中借鉴的要点。英伟达生态的思考点从软件和硬件架构的角度出发,CUDA 和 SIMT 之间存在一定的关系,而目前 AI 芯片采用的 DSA 架构在编程模型和硬件执行模型上还处于较为早期的状态,英伟达强大的生态同样离不开 CUD
](https://blog.51cto.com/u_17152548/12662374)
CUDA 易用性 英伟达
-
[
【AI系统】AI芯片驱动智能革命
在整个 AI 系统的构建中,AI 算法、AI 框架、AI 编译器、AI 推理引擎等都是软件层面的概念,而 AI 芯片则是物理存在的实体,AI 芯片是所有内容的重要基础。本系列文章将会通过对典型的 AI 模型结构的设计演进进行分析,来理解 AI 算法的计算体系如何影响 AI 芯片的设计指标,进而结合几种主流的 AI 芯片基础介绍,帮助大家对 AI 系统的整个体系知识有更全面的认识。什么是 AI 芯片
](https://blog.51cto.com/u_17152548/12662779)
人工智能 数据 深度学习
-
[
AI芯片
AI芯片,又称为人工智能加速器或计算卡,是一种专门用于加速人工智能和机器学习算法的硬件设备。与传统CPU和GPU相比,AI芯片在设计上针对AI算法进行了优化,提供了更大的并行计算能力和更高的能源效率,以满足人工智能和机器学习领域对高性能计算的需求。AI芯片的主要类型包括:GPU:图形处理器(GPU)原本是为图形渲染和游戏设计而生的,但其并行计算能力非常适合用于深度学习等AI计算场景。GPU中的并行
](https://blog.51cto.com/u_16104640/8951967)
并行计算 神经网络 人工智能
-
[
【AI系统】芯片的编程体系
本文主要探讨 SIMD 和 SIMT 的主要区别与联系,SIMT 与 CUDA 编程之间的关系,并且会讨论 GPU 在 SIMT 编程本质,SIMD、SIMT 与 DSA 架构,DSA 架构的主要形态。目前已经有大量的 AI 芯片研发上市,但是如何开发基于硬件的编译栈与编程体系,让开发者更好地使用 AI 芯片,更好的发挥 AI 芯片的算力,让生态更加繁荣,因此理解 AI 芯片的编程体系就显得尤为重
](https://blog.51cto.com/u_17152548/12662350)
数据 指令流 神经网络
-
[
AI深度思考
目前的AI是通过模拟神经网络的训练来实现的,基本可是理解为 已知输入A 和 输出B 对中间的神经网络进行不断的调整 已达到可以任意输入A,就可得出B的能力 这可以叫做学会了一个技能 就和我们学习武术一样 已知的是我们的听到的 看到的 输入 结果就是 武术 我们不知到中间要经历什么 ,但是最后是会学会的从上述总结来看 ,为什么AI算法很重要也很赚钱了,因为AI 也就是什么神经网络的精髓在于,将我们想
](https://blog.51cto.com/u_15177056/5176637)
AI的深度思考 神经网络 输入输出 自定义
-
[
ai芯片公司的芯片架构 ai芯片主要材料
为增进大家对芯片的认识,本文将对AI芯片的原理,以及AI芯片的重新配置予以介绍。芯片是非常重要的电子器件之一,我们的手机和电脑等设备中都有芯片。为增进大家对芯片的认识,本文将对AI芯片的原理,以及AI芯片的重新配置予以介绍。如果你对芯片或是AI芯片具有兴趣,不妨和小编一起继续往下阅读哦。一、AI芯片及其原理AI芯片也被称为AI加速器或计算卡,即专门用于处理人工智能应用中的大量计算任务的模块(其他非
](https://blog.51cto.com/u_16213682/7706338)
ai芯片公司的芯片架构 人工智能 fpga开发 语音识别 神经网络
-
[
AI芯片架构入门 ai芯片技术
AI芯片的创新方向大体是以高性能和/或低功耗为要点。下图中展示了一些目前所知的AI芯片的创新实现方法。1. 脉动式电路所谓脉动式设计,是指运算过程模拟心脏和血管中血液的脉动式流动,数据像流水线一样经过各个处理器,数据可以被重复使用而不需要每次都返回存储器,由于少了数据的搬运,该设计可以大大降低功耗。2. 异步电路异步电路没有时钟,由事件驱动,可以大大提高芯片性能并降低功耗。由于该种电路设计难度较大
](https://blog.51cto.com/u_12968/7665435)
AI芯片架构入门 人工智能 神经网络 模拟电路 数据
-
[
AI芯片前端架构 ai 芯片前景
2022年AI芯片场景 随着技术成熟化,AI芯片的应用场景除了在云端及大数据中心,也会随着算力逐渐向边缘端移动,部署于智能家居、智能制造、智慧金融等领 域;同时还将随着智能产品种类日渐丰富,部署于智能手机、安防摄像头、及自动驾驶汽车等智能终端,智能产品种类也日趋丰富。未来,AI计算将无处不在。 云端:当前仍是AI的中心,需更高性能计算芯片以
](https://blog.51cto.com/u_16213649/8104754)
AI芯片前端架构 数据 自动驾驶 智能终端
-
[
ai芯片的架构 ai芯片 通俗易懂
2. 阅读笔记2.1 背景AI的三大关键基础要素:数据是AI算法的“饲料”算法是AI的背后“推手”算力是基础设施算力源于芯片,通过基础软件的有效组织,最终释放到终端应用上,作为算力的关键基础,AI芯片的性能决定着AI产业的发展。不同类型的芯片所擅长的领域不同AI运算指以“深度学习” 为代表的神经网络算法,需要系统能够高效处理大量非结构化数据( 文本、视频、图像、语音等) 。需要硬件具有高效的线性代
](https://blog.51cto.com/u_12935/6815135)
ai芯片的架构 人工智能 fpga开发 深度学习 数据
-
[
ai芯片技术架构 ai芯片包括哪些芯片
和计算能力三方面的突破,这三方面的能力展现离不开AI芯片。由此,AI芯片的研发制造成了人工智能技术发展过程中的关键环节。不同于其它传统芯片,AI芯片是近年新兴产品,拥有强大市场需求的中国一直对AI芯片的发展寄予厚望,希望在这个新的技术领域中能占领优先发展位置,缩短与半导体发达国家的距离。截止中商产业研究院在今年上半年发布的《2019年中国IC设计行业投资前景研究报告》显示,彼时中国的A
](https://blog.51cto.com/u_16099315/7943082)
ai芯片技术架构 人工智能 低功耗 指令集
-
[
ai芯片架构 ai芯片 通俗易懂
进入公司AI产业快有3个年头,AI芯片和传统芯片,甚至AI芯片和GPU,还有AI芯片的发展历史,面向未来场景的挑战都有很多话题,下面我们一起来聊聊AI芯片和传统芯片的区别哈。芯片是半导体元件产品的统称,而集成电路,缩写是IC,就是将电路小型化,通过电子学和光学,将电路制造在半导体晶圆上面。我们会分为4个小点进行介绍AI芯片前言解读。首先是AI芯片从CPU、GPU、到XPU的发展情况总体介绍,接着是
](https://blog.51cto.com/u_16213567/7396225)
ai芯片架构 人工智能 深度学习 数据 Google
-
[
AI芯片 架构 ai芯片架构 低功耗
ROHM开发出一款设备端学习*AI芯片(配备设备端学习AI加速器的SoC),该产品利用AI(人工智能)技术,能以超低功耗实时预测内置电机和传感器等的电子设备的故障(故障迹象检测),非常适用于IoT领域的边缘计算设备和端点*1。通常,AI芯片要实现其功能,需要进行设置判断标准的“训练”,以及通过学到的信息来判断如何处理的“推理”。在这种情况下,“训练”需要汇集庞大的数据量形成数据库并随时更新,因此进
](https://blog.51cto.com/u_16099203/9247114)
AI芯片 架构 学习 人工智能 服务器 云服务
-
[
基于AI芯片AI项目架构 ai芯片发展趋势
摘要:当前,在算力、算法和大数据三驾马车的支撑下,全球人工智能进入第三次爆发期。然而,作为引爆点的深度学习算法,对现有的算力尤其是芯片提出了更为苛刻的要求。在AI场景中,传统通用CPU由于计算效率低难以适应AI计算要求,GPU、FPGA以及ASIC等AI芯片凭借着自身特点,要么在云端,要么在边缘端,有着优异表现,应用更广。从技术趋势看,短期内GPU仍将是AI芯片的主导,长期看GPU、FPGA以及A
](https://blog.51cto.com/u_16213683/10885688)
基于AI芯片AI项目架构 人工智能 深度学习 数据
-
[
ai芯片架构原理 ai芯片组
去年,华为就曾预告过将针对打造面向边缘和端的全栈全场景解决方案。上文提到的这两款AI芯片,其实是华为AI全栈全场景AI解决方案的一部分。onFednc所谓全场景,即包括公有云、私有云、各种边缘计算、物联网行业终端以及消费类终端等部署环境,即“让 AI 无处不在,无所不及”,而全栈即包括芯片、芯片服务,还有硬件,以及训练和推理的框架和应用在内的全堆栈解决方案。onFednc华为的全栈方案具体包括:o
](https://blog.51cto.com/u_12195/13876855)
ai芯片架构原理 华为计算机平台芯片 edn 人工智能 解决方案
-
[
ai芯片架构 论文 ai芯片主要材料
为增进大家对AI芯片的认识,本文将对AI芯片进行详细阐述。芯片的种类很多,比如图形芯片、处理器芯片等等。随着技术的发展,其中一个芯片应运而生,那就是AI芯片。为增进大家对AI芯片的认识,本文将对AI芯片进行详细阐述。如果你对芯片具有兴趣,不妨和小编一起继续往下阅读哦。广义上讲只要能够运行人工智能算法的芯片都叫作 AI 芯片。通常意义上的 AI 芯片指的是针对人工智能算法做了特殊加速设计的芯片。AI
](https://blog.51cto.com/u_14731/8095735)
ai芯片架构 论文 ai 单片机 智能语音 人工智能
-
[
AI芯片和普通芯片架构的区别 ai芯片是啥
概要:但现在,一些芯片企业家得到了不同程度的欢迎。投资者没有对此嗤之以鼻,而是“慷慨地”拿出其支票簿。英国半导体创业公司Graphcore的联合创始人兼首席执行官Nigel Toon表示:“几年前,许多风险投资加都认为投资半导体行业是一个笑话。你可以想象,一群投资人听到芯片后笑得前仰后合。但现在,一些芯片企业家得到了不同程度的欢迎。投资者没有对此嗤之以鼻,而是“慷慨地”拿出其支票簿。风险投资家们有
](https://blog.51cto.com/u_13416/11851695)
AI芯片和普通芯片架构的区别 人工智能 深度学习 英伟达
-
[
ai芯片架构 gpu fpga ai芯片 gpu 区别
成立仅两年国内专做人工智能FPGA加速算法的初创公司深鉴科技被国际巨头赛灵思收购了,在业界引起不小的震动。目前国内做AI芯片的公司可谓不少了,AI芯片已然成为了当下芯片行业最热领域。但是大部分人对AI芯片的架构应该都不是太了解。那么AI 芯片和传统芯片有何区别?AI芯片的架构到底是怎么样的?先回答问题, (1)性能与传统芯片,比如CPU、GPU有很大的区别。在执行AI算法时,更快、更节能。 (2)
](https://blog.51cto.com/u_16099300/9163782)
ai芯片架构 gpu fpga 人工智能芯片 深度学习 浮点 数据
-
[
python编写知识图谱开源 知识图谱 源码
一、前言本文是《知识图谱完整项目实战(附源码)》系列博文的第3篇:汽车知识图谱系统架构设计,主要介绍汽车领域知识图谱系统的总体架构设计和关键技术。知识图谱的学习是一个基础到实战,从入门到精通的一个逐渐深入的、渐进式的过程。在这个过程中,一个完整的项目,起到的作用往往是对过往所学全部知识的串联和融合。只有经过一个完整项目的实践,才能真正把所学的、离散的、点状的知识点融合到一起,从而形成理论到实战的转
](https://blog.51cto.com/u_16213638/14042690)
python编写知识图谱开源 项目实战 图数据库 架构设计
-
[
win10 部署多个 redis实例 redis多节点部署
Redis简介Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。Redis有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读
](https://blog.51cto.com/u_16213565/14042993)
win10 部署多个 redis实例 数据库 ruby java Redis
-
[
AI加速器最新架构 中国
如何合理选择AI加速器?各种不同芯片架构之间进行选择时,性能、功耗、灵活度、连接性以及总拥有成本(TCO)当然是判断的标准。AI芯片从技术驱动向商业驱动发展。短期内,市场对AI的关注点仍将是:应用场景和落地节奏。一些带来高增长的应用场景已经浮现,与非研究院预测2022年仍将继续加速落地。应用场景方面,三大方向值得关注:数据中心/HPC、汽车以及XR为代表的应用领域;落地节奏上,可基于AI“新三要素
](https://blog.51cto.com/u_39029/14043968)
AI加速器最新架构 中国 数据中心 英伟达 数据
-
[
强化学习进行参数优化
给定一个函数 \(f(x)=x^2+3x-10\),完成以下题目:理解方程求根中的二分法(Bisection),并使用基本的 numpy 库而非 scipy 库,来实现算法。非线性方程求根注:该部分内容参考的是「中南大学数学科学与计算机技术学院」的课件,介绍了二分法的背景和原理,不感兴趣的可略过。在科学研究和工程设计中, 经常会遇到的一大类问题是非线性方程 f(x)=0 的求根问题,其中 f(x)
](https://blog.51cto.com/u_16213724/14044257)
强化学习进行参数优化 python 数据结构与算法 二分法 梯度下降法
-
[
java核心 卷二
更多 Java 高级知识方面的文章,请参见文集《Java 高级知识》JDK 11 reached General Availability on 25 September 2018. Production-ready binaries under the GPL are available from Oracle; binaries from other vendors will follow s
](https://blog.51cto.com/u_16213686/14044426)
java核心 卷二 Java 11新特性 java Java System
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

9周成为大模型工程师
第1周:基础入门
-
了解大模型基本概念与发展历程
-
学习Python编程基础与PyTorch/TensorFlow框架
-
掌握Transformer架构核心原理
-

第2周:数据处理与训练
-
学习数据清洗、标注与增强技术
-
掌握分布式训练与混合精度训练方法
-
实践小规模模型微调(如BERT/GPT-2)
第3周:模型架构深入
-
分析LLaMA、GPT等主流大模型结构
-
学习注意力机制优化技巧(如Flash Attention)
-
理解模型并行与流水线并行技术
第4周:预训练与微调
-
掌握全参数预训练与LoRA/QLoRA等高效微调方法
-
学习Prompt Engineering与指令微调
-
实践领域适配(如医疗/金融场景)
第5周:推理优化
-
学习模型量化(INT8/FP16)与剪枝技术
-
掌握vLLM/TensorRT等推理加速工具
-
部署模型到生产环境(FastAPI/Docker)
第6周:应用开发 - 构建RAG(检索增强生成)系统
-
开发Agent类应用(如AutoGPT)
-
实践多模态模型(如CLIP/Whisper)


第7周:安全与评估
-
学习大模型安全与对齐技术
-
掌握评估指标(BLEU/ROUGE/人工评测)
-
分析幻觉、偏见等常见问题
第8周:行业实战 - 参与Kaggle/天池大模型竞赛
- 复现最新论文(如Mixtral/Gemma)
- 企业级项目实战(客服/代码生成等)
第9周:前沿拓展
- 学习MoE、Long Context等前沿技术
- 探索AI Infra与MLOps体系
- 制定个人技术发展路线图

👉福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】



















 1193
1193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











