






大家好,我是一粟。
前段时间 n8n 这个海外的 AI Agent 自动化工具真的太火了,身边搞智能体的朋友几乎都在聊它。
刚好,我有一个困扰了我很久的问题:
我每天都需要花费大量的时间去浏览各大海外的网站,并从中筛选和阅读收集最新的 AI 新闻资讯。这个过程真的是非常的耗费时间的,且效率十分的低下。
那有没有一个平台或者工具能满足我的这个需求呢?
最开始我使用的是国内的扣子。但当时它最大的问题就是,没办法访问到国外的一些新闻资讯,然后这个需求就不了了之了。
于是就在前几天,我抱着试试看的心态去体验了一下 n8n 这个自动化智能体平台,只能说超出我的预期和想象。
首先 n8n 是开源的,可以在云服务或者本地使用 Docker 进行部署,这一点真的很方便。
其次,因为它是海外的软件,只要你的网络条件允许,那就可以使用像 Google、Ins 等这些应用节点。
然后使用 HTTP 请求,调用一些获取海外新闻的 API,比如 GNews、News API 等。
最后,还能定时执行并触发整个工作流。
可以说这 3 点,完美的满足了我自动获取每日最新 AI 新闻的这个需求。
整体的搭建流程其实和扣子差不多,都是在可视化的界面上拖动节点,就像小时候搭积木一样。
每天定时触发,从 News 和 GNews 中获取到最新的 AI 新闻,对获取到的数据进行清洗,去重后扔到大模型节点,将英文/韩文/日语等翻译为中文,最后整理并保存到飞书节点。
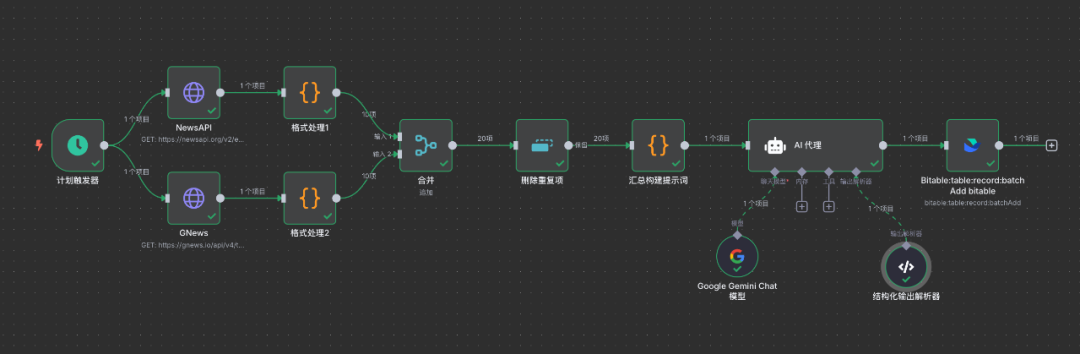
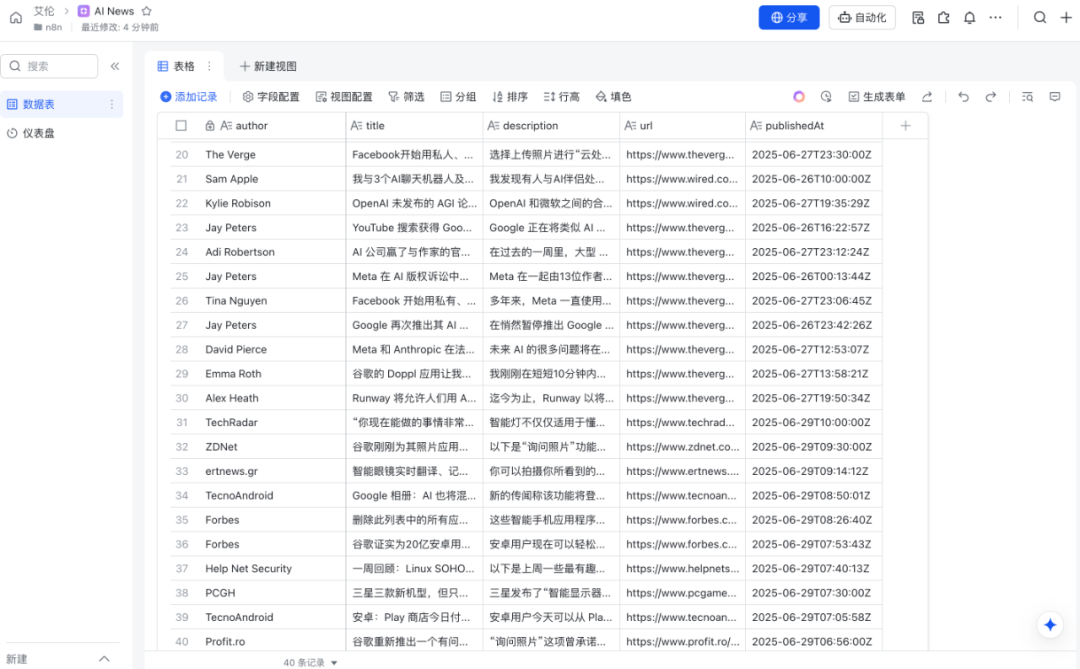
最后的飞书效果如图所示。
接下来我就带大家看看每一个节点具体是如何编写的。
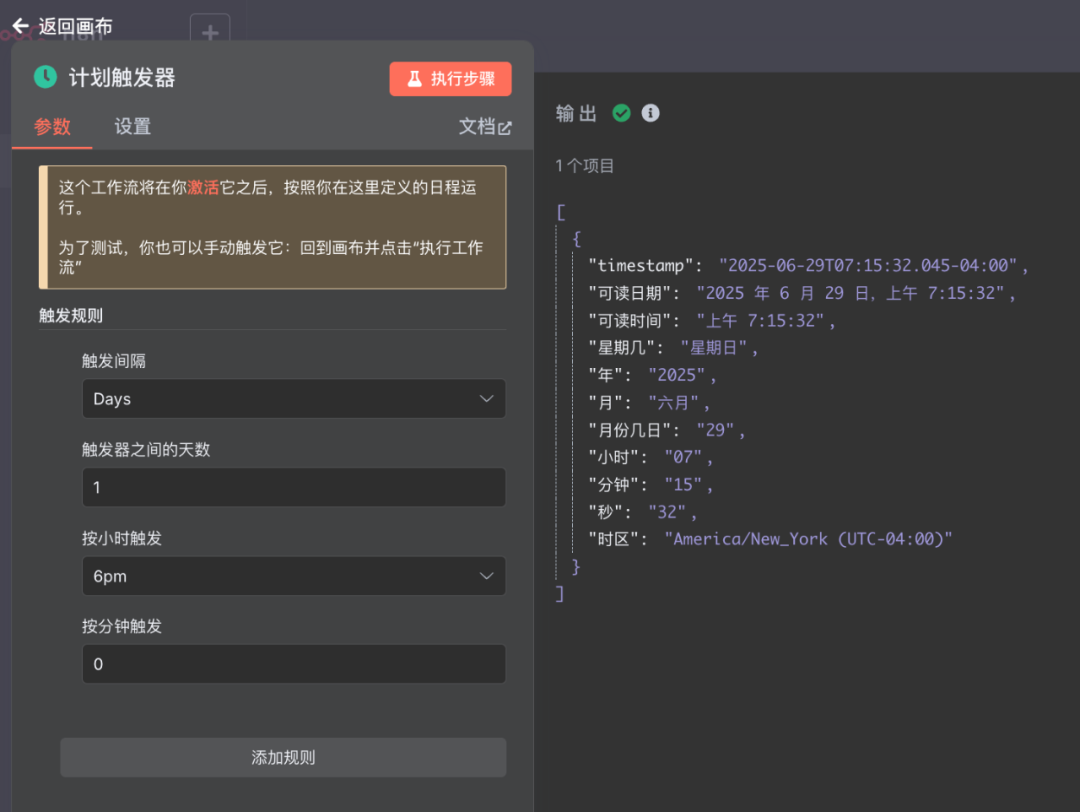
首先是触发器节点,因为它用的不是东八区,而是纽约的时间。如果想在北京时间生效,那得做一下时间的转化。
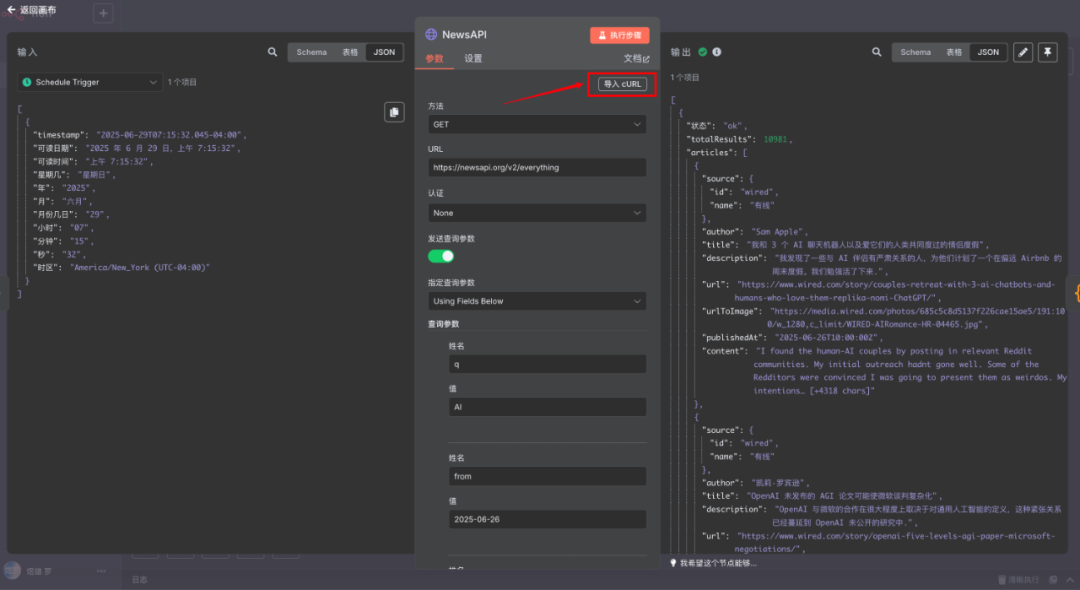
接下来是两个 HTTP 节点。注册 GNews 和 News API 后,直接点击他们的文档,就可以找到 cURL,然后再点击"导入 cURL",粘贴后就可以测试了。
接下来是格式的处理,这里我们要用到的是 Code 节点。
首先是 News API 出参的格式处理,这里我直接把我的 JS 代码贴在下面,朋友们可以直接使用也可以用 DeepSeek 或者其他 AI 大模型重新写一个。
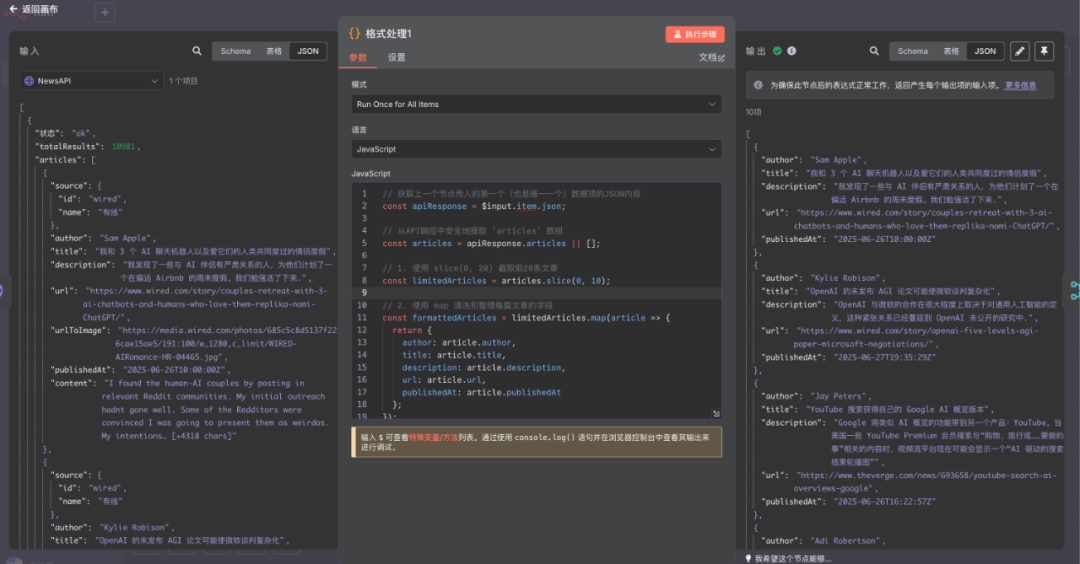
代码如下:
// 获取上一个节点传入的第一个(也是唯一一个)数据项的JSON内容
const apiResponse = $input.item.json;
// 从API响应中安全地提取 'articles' 数组
const articles = apiResponse.articles || [];
// 1. 使用 slice(0, 20) 截取前20条文章
const limitedArticles = articles.slice(0, 10);
// 2. 使用 map 清洗和整理每篇文章的字段
const formattedArticles = limitedArticles.map(article => {
return {
author: article.author,
title: article.title,
description: article.description,
url: article.url,
publishedAt: article.publishedAt
};
});
// 3. 返回处理后的数据
// n8n要求返回一个对象数组,每个对象都会成为下一个节点的一个独立项。
// 我们将整理好的文章数组包装成 n8n 的标准输出格式。
return formattedArticles.map(item => ({ json: item }));
然后是 GNews 的。这里需要注意,因为"name"是嵌套在"source"里面的,所以在代码编写上需要额外的处理,比 News API 会多一步。
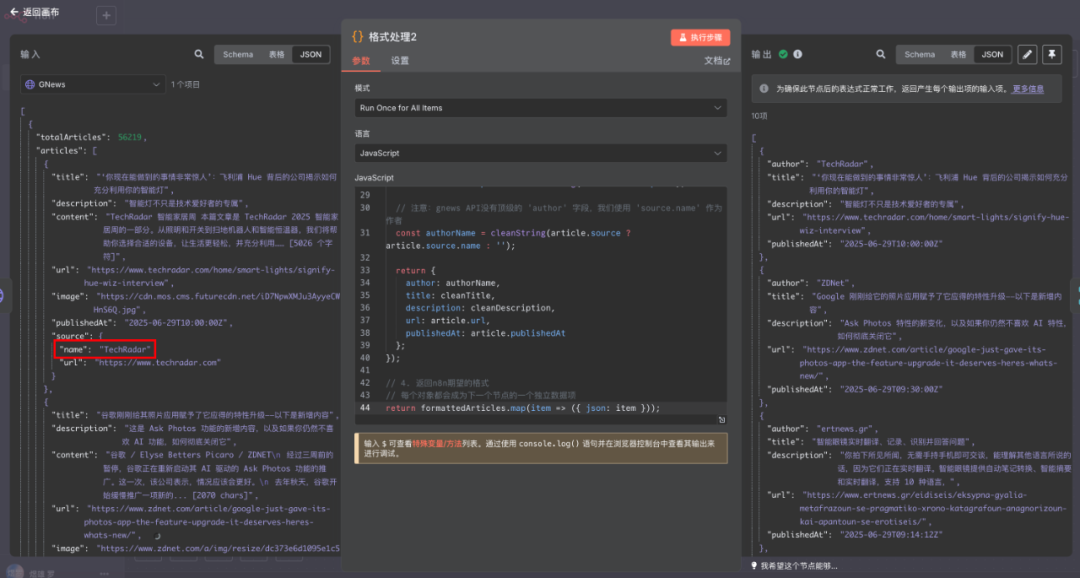
代码如下:
// --- 数据清理函数 ---
// 用于移除特殊字符,确保数据格式正确,特别是写入CSV或数据库时
function cleanString(str) {
// 如果输入不是有效字符串,返回空字符串
if (!str) return '';
// 链式调用替换和清理方法
return str
.replace(/[\r\n\t]/g, ' ') // 将换行、回车、制表符替换为空格
.replace(/[\u0000-\u001F\u007F]/g, '') // 移除ASCII控制字符
.replace(/"/g, '\"') // 转义双引号,防止破坏JSON或CSV格式
.trim(); // 移除字符串首尾的空格
}
// --- 主逻辑 ---
// 1. 获取上一个节点传入的JSON数据
// gnews.io 的响应直接是一个对象,里面包含 articles 数组
const apiResponse = $input.item.json;
// 2. 安全地提取 'articles' 数组
const articles = apiResponse.articles || [];
// 3. 截取前20条,并进行格式化
const formattedArticles = articles.slice(0, 20).map(article => {
// 对需要清理的文本字段应用 cleanString 函数
const cleanTitle = cleanString(article.title);
const cleanDescription = cleanString(article.description);
// 注意:gnews API没有顶级的 'author' 字段,我们使用 'source.name' 作为作者
const authorName = cleanString(article.source ? article.source.name : '');
return {
author: authorName,
title: cleanTitle,
description: cleanDescription,
url: article.url,
publishedAt: article.publishedAt
};
});
// 4. 返回n8n期望的格式
// 每个对象都会成为下一个节点的一个独立数据项
return formattedArticles.map(item => ({ json: item }));
合并节点就是将格式化后的数据整合在一起,使用"Append"参数就行。
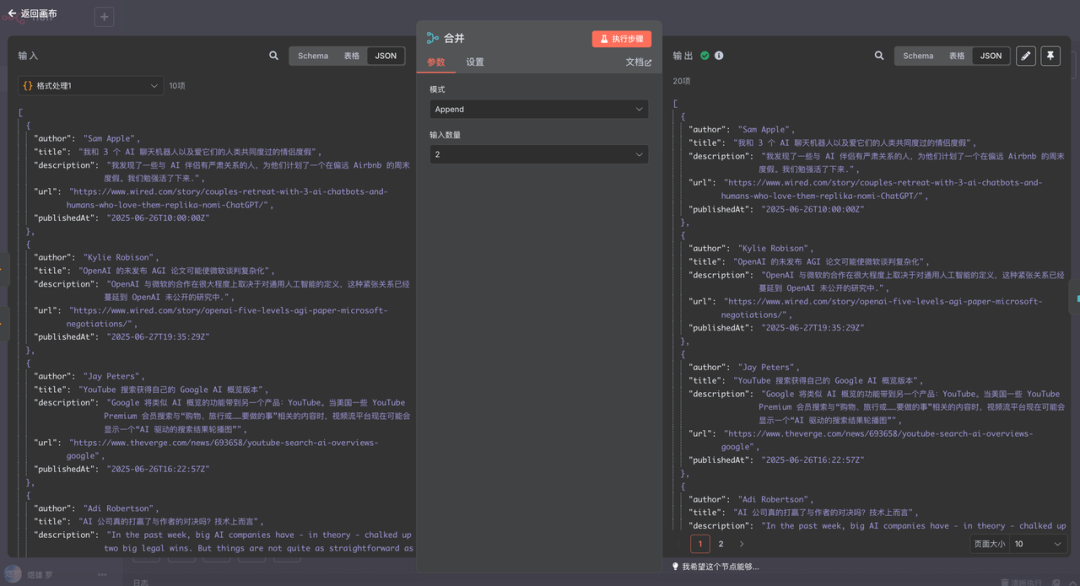
删除重复项节点就是字面意思,这里就不多做介绍了。
在这之后,我又用到了一个 Code 节点,主要是将所有的数据整合为一个 Json,这样方便后面的大模型节点进行翻译的工作。
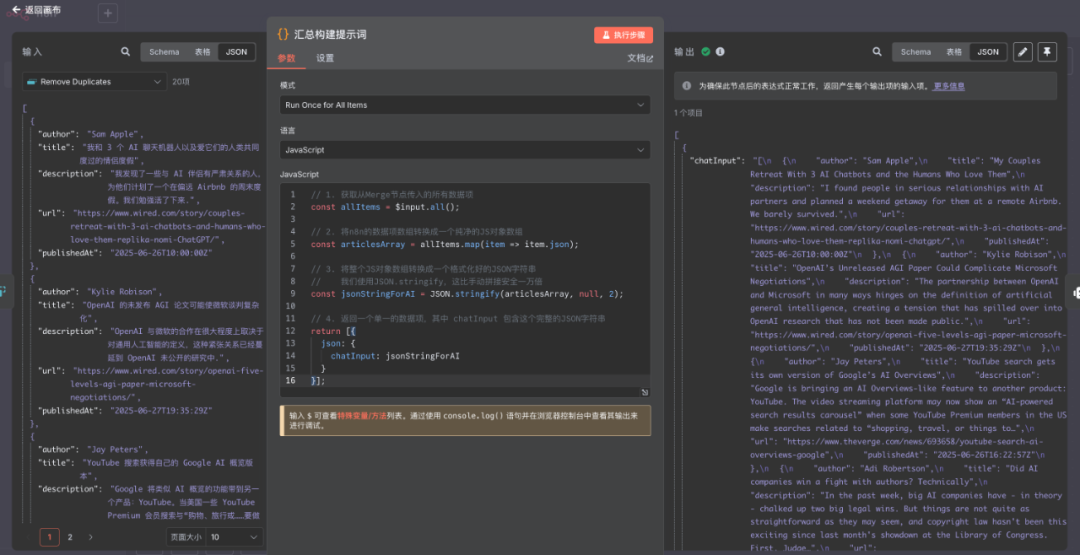
代码如下:
// 1. 获取从Merge节点传入的所有数据项
const allItems = $input.all();
// 2. 将n8n的数据项数组转换成一个纯净的JS对象数组
const articlesArray = allItems.map(item => item.json);
// 3. 将整个JS对象数组转换成一个格式化好的JSON字符串
// 我们使用JSON.stringify,这比手动拼接安全一万倍
const jsonStringForAI = JSON.stringify(articlesArray, null, 2);
// 4. 返回一个单一的数据项,其中 chatInput 包含这个完整的JSON字符串
return [{
json: {
chatInput: jsonStringForAI
}
}];
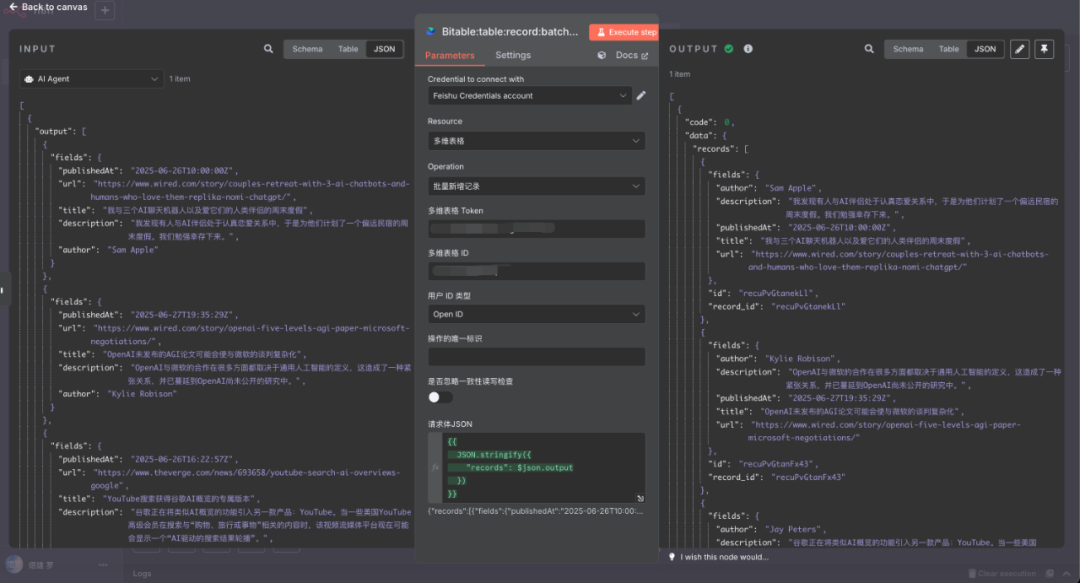
接下来就是 AI 大模型节点了。这里我们使用提示词,将新闻内容全部翻译为中文,然后再用输出解析器,重新整理该节点的输出格式,最后传给飞书做存储。
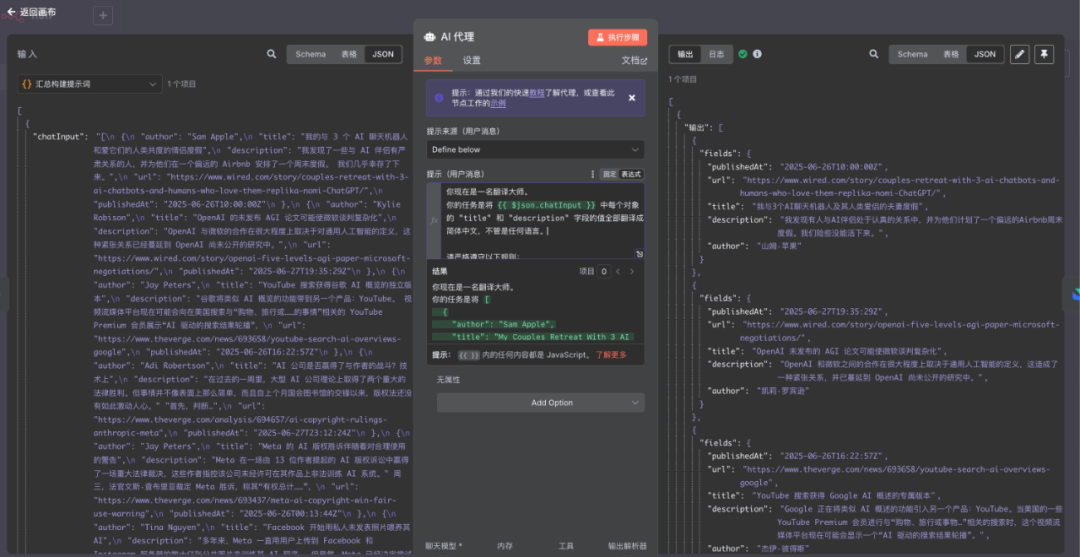
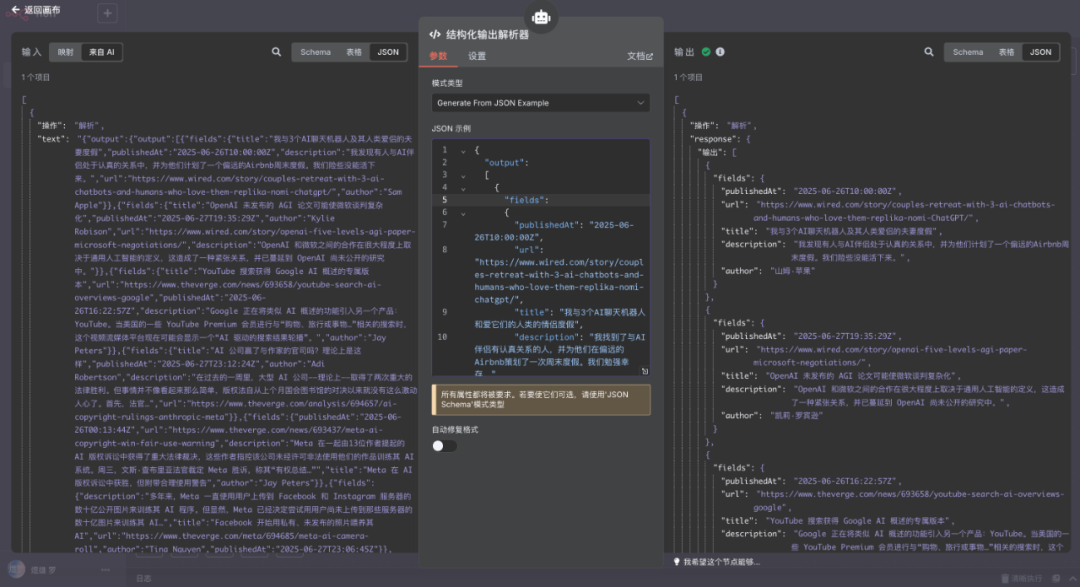
结构化输出解析器里面需要填写一个 Json,这个 Json 就是格式化后的结构。
最后是飞书节点。这里我们需要先将飞书添加到 n8n 当中。
首先点击左下角的"设置",进入到设置界面。
然后再点击"community nodes"按钮,安装飞书节点。
n8n-nodes-feishu-lite
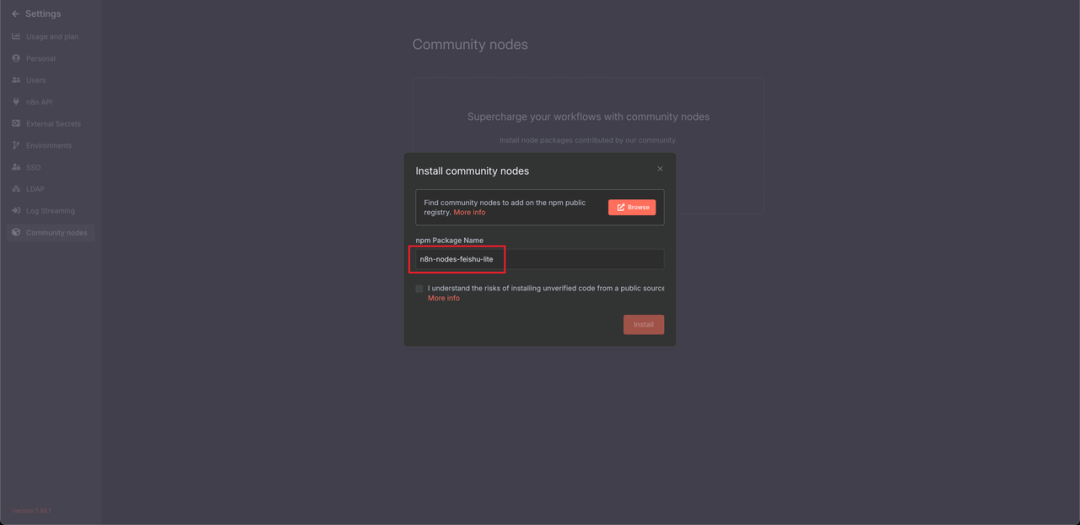
点击下载,就能看到飞书节点已经被安装完毕。
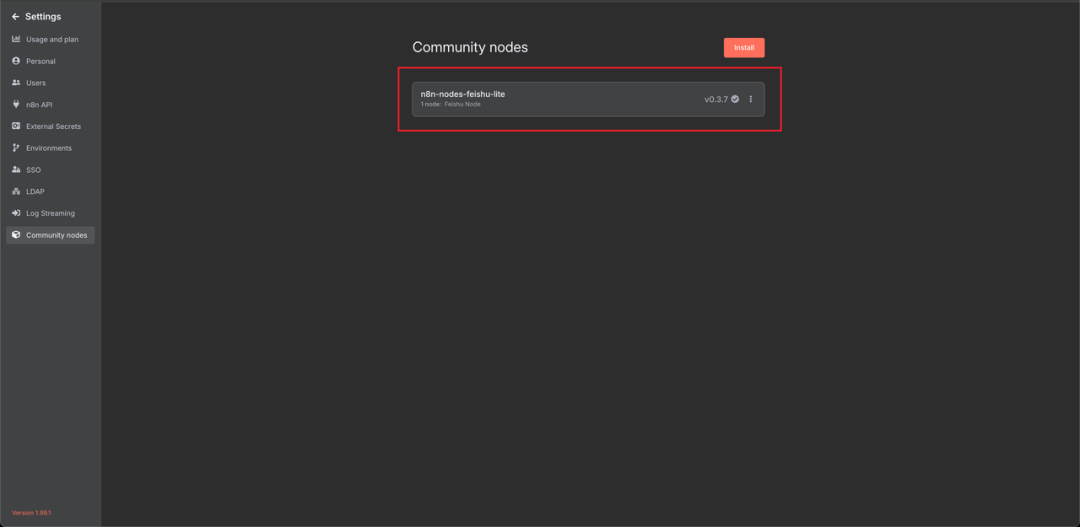
最后的飞书节点如图所示。
构建这整个流程,我基本没有自己上手写过一行代码,都是 DeepSeek 或者 Gemini 完成,我只用和他说我想要的效果就够了。
n8n 真正赋予我们的,是一种上帝视角的创造权。
它就像一个AI时代的“乐高无限套装”,把API、大模型、数据库、各种应用,都变成了我们可以随意拼接的积木。
能做的远不止新闻摘要。
你可以用它搭建自动化的客服机器人、智能的数据分析报告生成器、个性化的学习资料整理工具等等。
本没有自己上手写过一行代码,都是 DeepSeek 或者 Gemini 完成,我只用和他说我想要的效果就够了。
n8n 真正赋予我们的,是一种上帝视角的创造权。
它就像一个AI时代的“乐高无限套装”,把API、大模型、数据库、各种应用,都变成了我们可以随意拼接的积木。
能做的远不止新闻摘要。
你可以用它搭建自动化的客服机器人、智能的数据分析报告生成器、个性化的学习资料整理工具等等。
你的想象力,是它唯一的边界。
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图




如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取

👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,**有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
**或扫描下方二维码领取 **



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











