



前言
本文将从微调的本质、微调的原理、微调的应用三个方面,带您一文搞懂模型微调 Fine-tuning 。
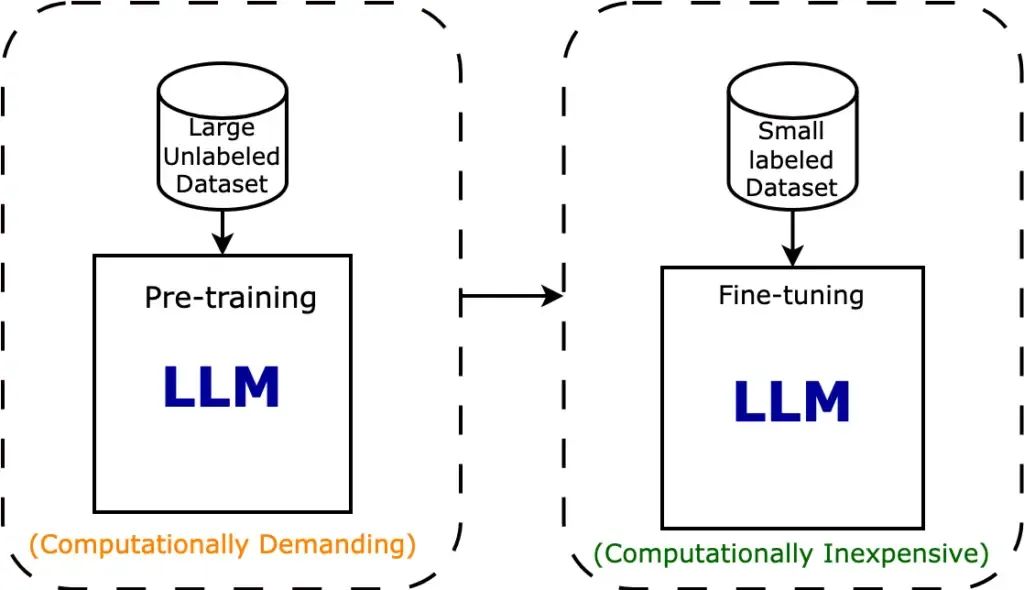
Fine-tuning模型微调
一、微调的本质
**如何利用预训练模型?**两种流行方法是迁移学习和微调。
迁移学习是一个更广泛的概念,它包括了多种利用预训练模型的方法,而微调是迁移学习中的一种具体实现方式。
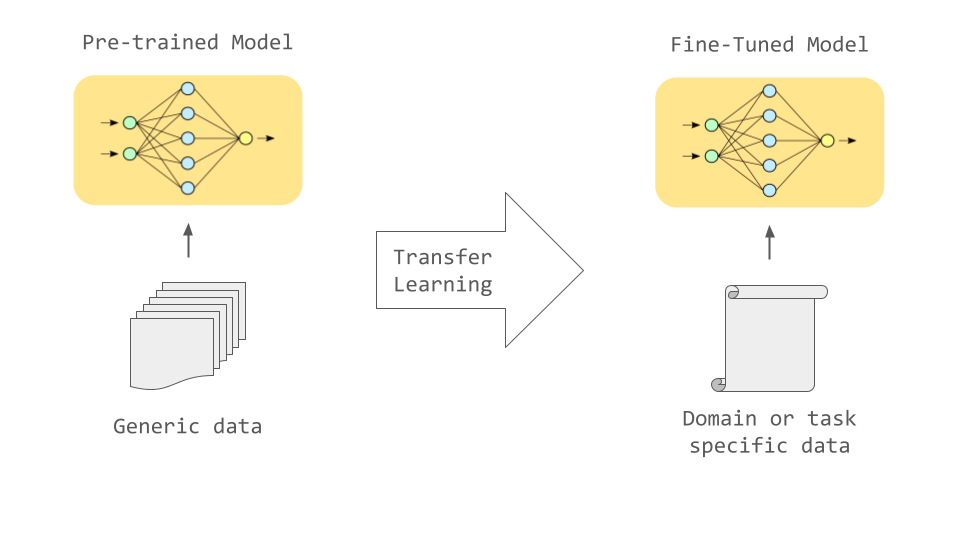
迁移学习和微调
**迁移学习(Transfer Learning):**使用在大型数据集上预训练的模型作为起点,然后将其应用于新的、相关但可能较小或特定领域的数据集。
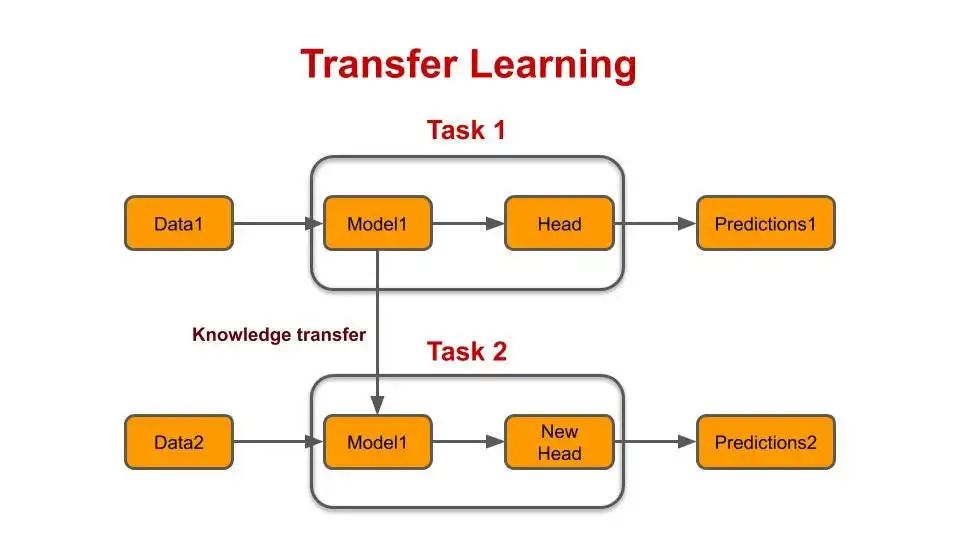
Transfer Learning 迁移学习
微调(Fine-tuning):迁移学习的一种具体实现方式,对预训练模型的参数进行进一步的调整和优化,以适应新的任务。
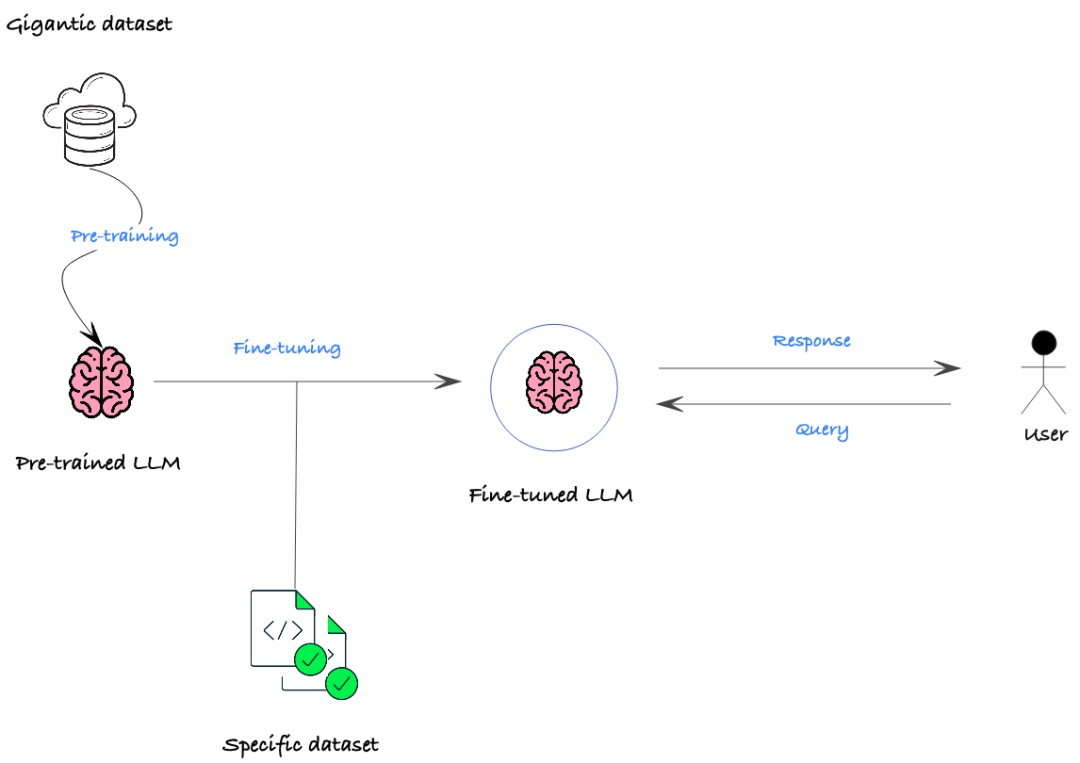
Fine-tuning 微调
为什么需要微调?减少对新数据的需求和降低训练成本。
微调的价值:可以帮助我们更好地利用预训练模型的知识,加速和优化新任务的训练过程,同时减少对新数据的需求和降低训练成本。
- **减少对新数据的需求:从头开始训练一个大型神经网络通常需要大量的数据和计算资源,而在实际应用中,我们可能只有有限的数据集。**通过微调预训练模型,我们可以利用预训练模型已经学到的知识,减少对新数据的需求,从而在小数据集上获得更好的性能。
- 降低训练成本:由于我们只需要调整预训练模型的部分参数,而不是从头开始训练整个模型,因此可以大大减少训练时间和所需的计算资源。这使得微调成为一种高效且经济的解决方案,尤其适用于资源有限的环境。
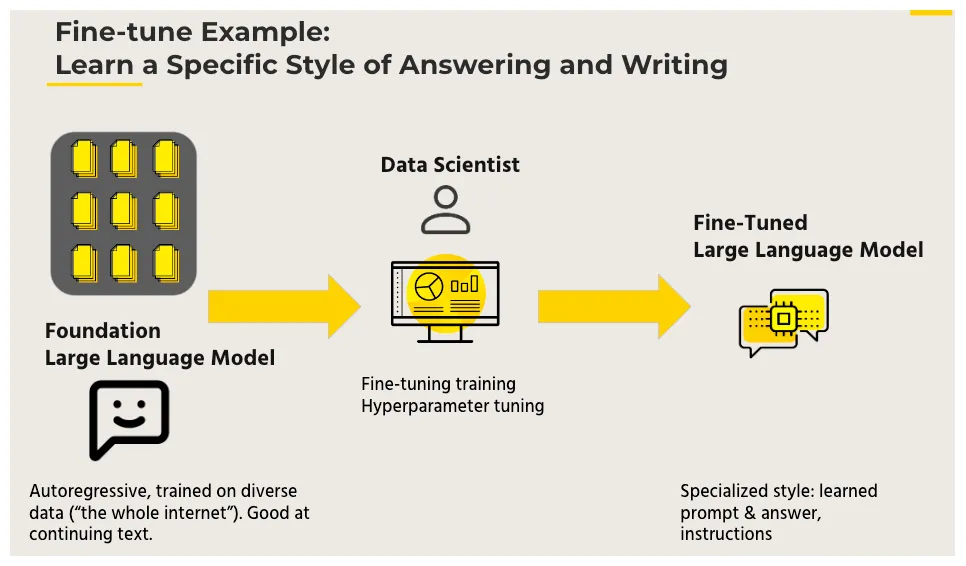
微调的价值
下面给大家分享一份2025最新版的大模型学习路线,帮助新人小白更系统、更快速的学习大模型! 有需要完整版学习路线,可以微信扫描下方二维码,立即免费领取!

二、微调的原理
微调的原理:利用已知的网络结构和已知的网络参数,修改output层为我们自己的层,微调最后一层前的若干层的参数。
这样可以有效利用深度神经网络强大的泛化能力,又免去了设计复杂的模型以及耗时良久的训练。因此,Fine-tuning是当数据量不足时的一个比较合适的选择。
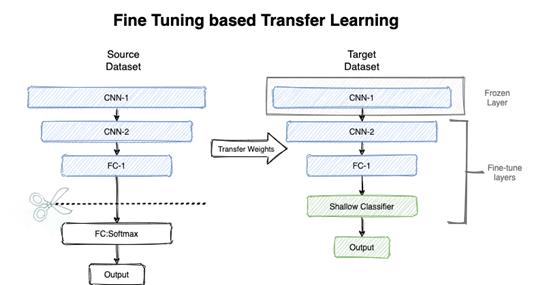
微调的原理
参数高效微调PEFT:Parameter-Efficient Fine-Tuning是一种高效的迁移学习技术,它旨在通过最小化微调过程中需要更新的参数数量来降低计算复杂度和提高训练效率。
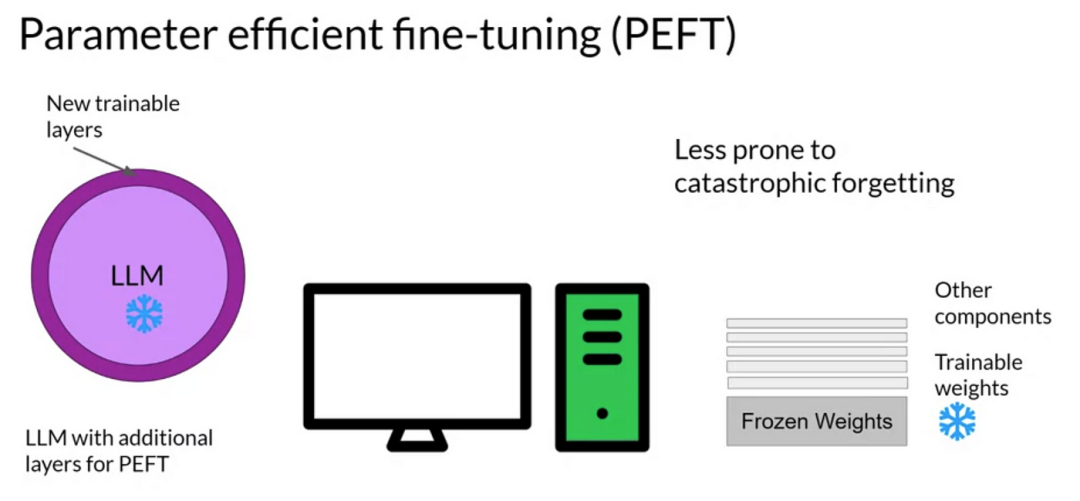
参数高效微调PEFT
PEFT仅针对部分参数进行微调,从而显著减少了训练时间和成本,尤其适用于数据量有限或计算资源受限的场景。
PEFT包含了多种不同的技术,例如Prefix Tuning、Prompt Tuning、Adapter Tuning和LoRA等,每种技术都有其独特的方法和特点,可以根据具体的任务和模型需求灵活选择。
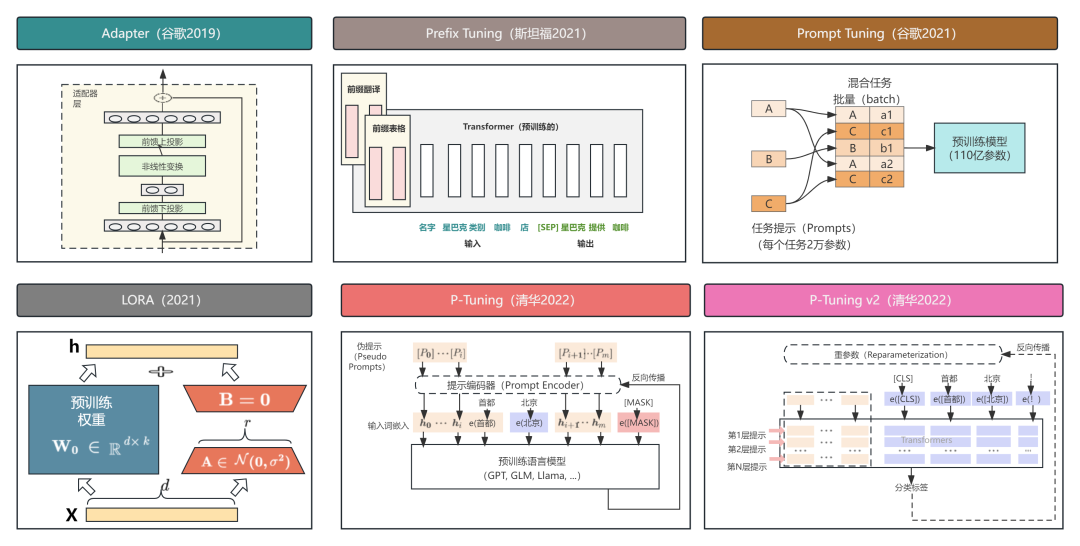
PEFT的分类
- Prefix Tuning: 通过在模型的输入前添加可学习的虚拟令牌(virtual tokens)作为前缀来实现微调。**在训练过程中,仅更新这些前缀参数,而模型的其余部分保持不变。**这种方法减少了需要更新的参数数量,从而提高了训练效率。
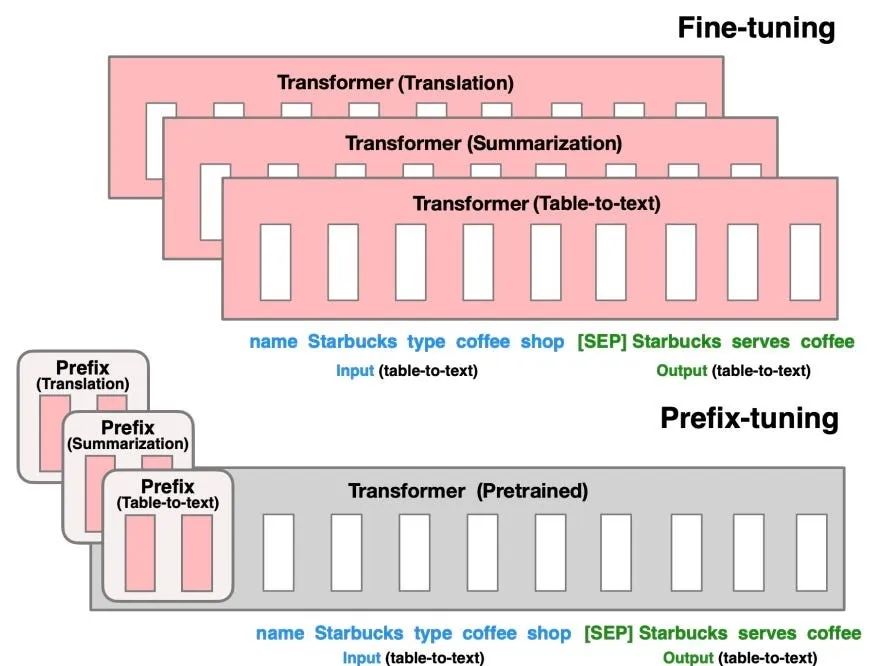
Prefix Tuning
- Prompt Tuning: 在输入层加入prompt tokens,可以看作是Prefix Tuning的简化版,它不需要额外的多层感知机(MLP)调整。随着模型规模的增大,Prompt Tuning的效果逐渐接近全量微调。
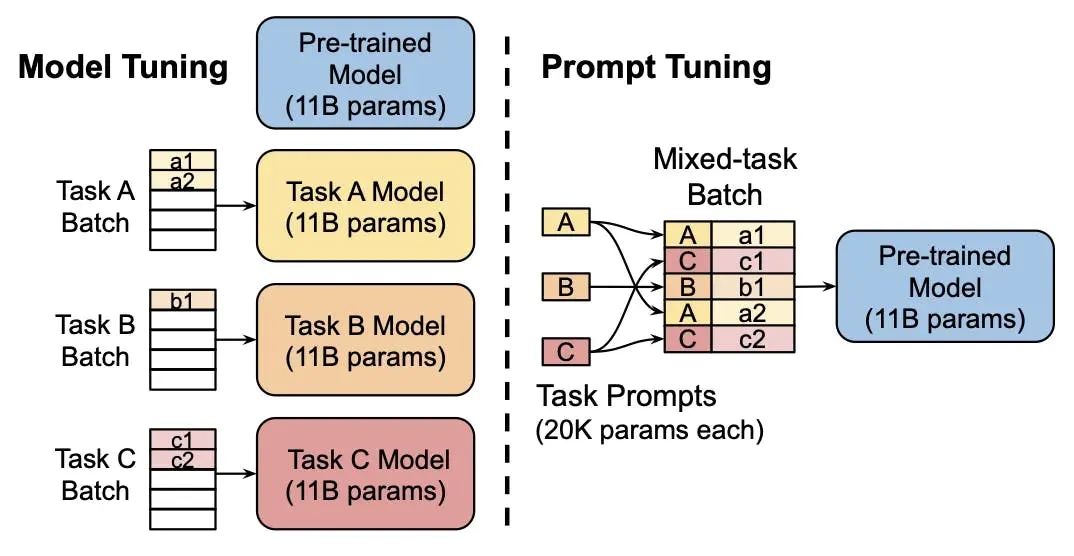
Prompt Tuning
- Adapter Tuning: 则是通过在模型中设计并嵌入Adapter结构来进行微调。这些Adapter结构通常是小型网络模块,可以添加到模型的特定层中。在训练过程中,仅对这些新增的Adapter结构进行微调,而原模型的参数保持不变。这种方法保持了模型的高效性,同时引入的额外参数数量相对较少。
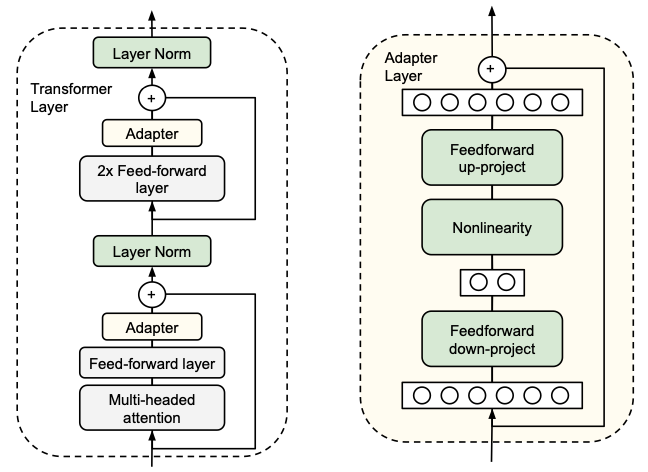
Adapter Tuning
- LoRA(Low-Rank Adaptation): 通过在模型的矩阵相乘模块中引入低秩矩阵来模拟全量微调的效果。它主要更新语言模型中的关键低秩维度,从而实现高效的参数调整并降低计算复杂度。
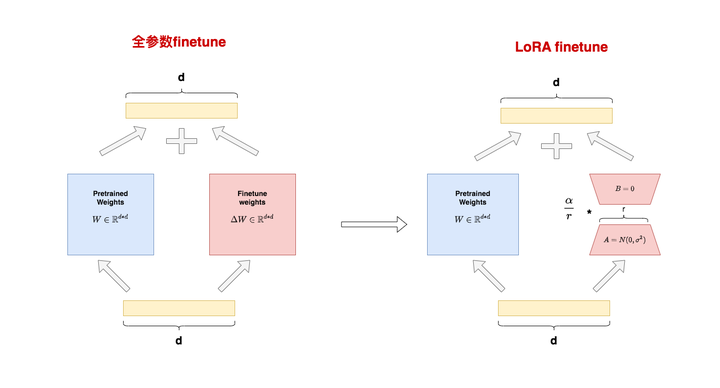
LoRA
三、微调的应用
CNN的微调:微调的方法包括仅修改最后一层、修改最后几层以及微调整个模型,同时可结合冻结部分层的策略来优化性能。
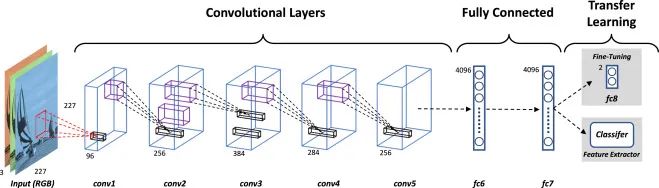
CNN的微调
几种微调CNN模型的方法:
方法一:仅修改最后一层(全连接层)
- 策略:保持预训练CNN模型中除最后一层外的所有层不变,仅替换或修改最后的全连接层以适应新任务的类别数。根据需要,可以选择是否冻结靠近输入的层。
- 效果:快速适应新任务的分类需求,同时保留预训练模型学到的有用特征。
方法二:修改最后几层
- 策略:除了最后一层外,还修改倒数第二层或更前面的几层,以适应新任务的特征需求。在修改过程中,可以根据需要选择是否冻结部分层。
- 效果:使模型学习更多与新任务相关的特征表示,提高在新任务上的性能。但需要注意过拟合的风险。
方法三:微调整个模型
- 策略:对预训练模型的所有层进行参数更新,以适应新任务的需求。在微调过程中,可以根据需要选择是否冻结部分层,以平衡新特征学习和保留有用特征的需求。
- 效果:使模型在新任务上达到更好的性能,但需要更多的计算资源和时间,并容易过拟合。
Transformer的微调:经过预先训练的 Transformer 可以针对众多下游任务快速进行微调,并且通常开箱即用,性能非常好。
这主要是因为 Transformer 已经理解了语言,这使得训练可以集中于学习如何进行问答、语言生成、命名实体识别或人们为其模型设定的任何其他目标。
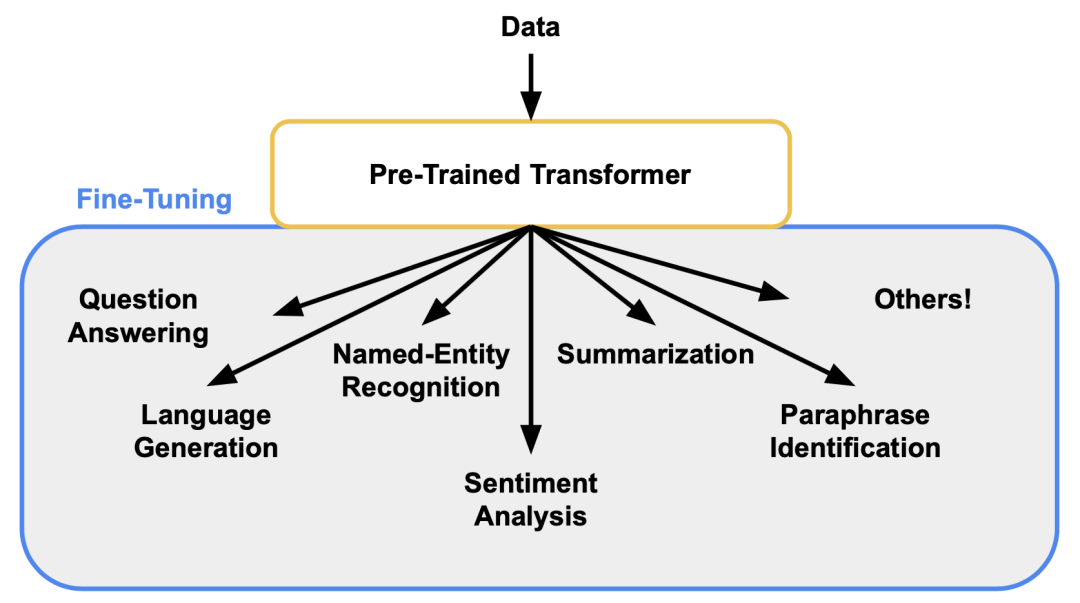
Transformer的微调
Transformer block with adapters:一种有效的参数高效微调技术,它通过在预训练的 Transformer 模型的主干网络中添加额外的适配器(adapters)或残差块**,来实现对特定任务的微调。**这些适配器通常是可训练的参数,而模型的其他部分则保持固定。
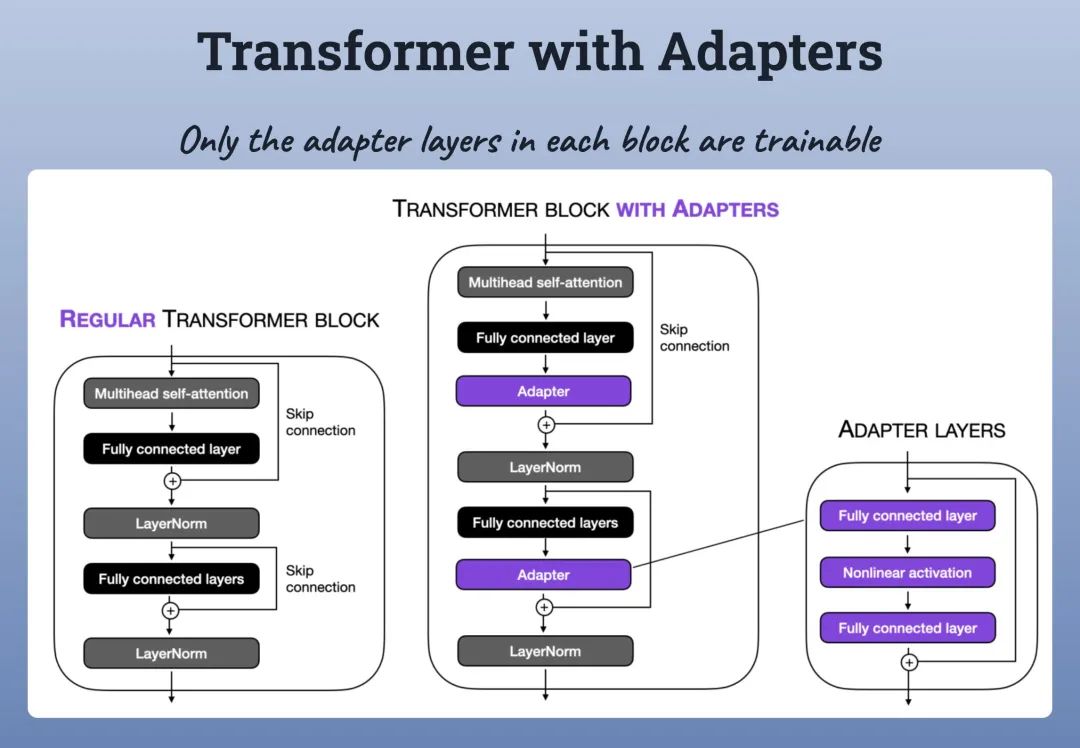
Transformer block with adapters 的微调方法通常包括以下步骤:
- 加载预训练模型:首先,加载已经在大规模语料库上预训练好的 Transformer 模型。
- 添加适配器:**在模型的主干网络中,为每个 Transformer 层添加适配器。**这些适配器可以是简单的线性层或更复杂的结构,具体取决于任务的需求。
- 初始化适配器参数:为添加的适配器设置初始参数。这些参数通常是随机初始化的,也可以采用其他初始化策略。
- 进行微调:使用特定任务的数据集对模型进行微调。在微调过程中,仅更新适配器的参数,而保持模型的其他部分不变。
- 评估性能:在微调完成后,使用验证集评估模型的性能。根据评估结果,可以进一步调整适配器的结构或参数,以优化模型的性能。
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图




如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取

👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,**有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
**或扫描下方二维码领取 **


















 7306
7306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











