






这是小米大模型组的一个面试,从这些题目可以看到,这个组很重视候选人的基础,全程都是基本功的拷问。

这篇笔记我们就来看看,面试中把这位候选人拷打麻了的一个 Transformer 面试连环炮,到底应该如何作答?

01面试题解析
第一轮拷问:transformer 的结构?
这个相信大部分同学都能回答上,Transformer 是由编码端和解码端组成,而编码端和解码端又由多个网络结构相同的 Block 堆叠组成。
每个 Block 由多头注意力层和前馈神经网络层组成。解码端跟编码部分类似,不同的是注意力机制采用的是 masked self-attention。
第二轮拷问:Transformer 输入向量的维度?
问这个问题,面试官其实主要是想考察你对 Transformer 的网络结构参数了不了解。
这里要答出两点:
- 输入 token 序列的维度:【batch, seqlen】
- 经过 embedding 之后的维度:【batch,seqlen,D】
其中 seqlen 是序列长度,D 是隐藏层的维度。后面多头注意力机制的变换,都是在 tensor 之间加权组合,不会改变这个输入的 shape。
举个例子:假如输入的原始句子是"我爱机器学习",我们按最简单的基于字的分词,这个样本的单词长度是 6,也就是 ‘我’ ‘爱’ ‘机’ ‘器’ ‘学’ ‘习’,这六个字。
经过 embedding 之后,每个词的 embedding 向量是 4096。那"我爱机器学习"这个句子 embedding 之后的维度就是【4096 】,如果是批量输入,那么 embedding 后的维度就是【batch, 4, 4096】
第三轮拷问:为什么在注意力机制这里要除以根号d?
这是一个老牌经典面试题了,对于这种题目,要注意的点就是,不要背八股答案,要用自己的话全程讲述出来。
我们对照公式来看:

**这里主要有两点原因:**首先,softmax 是一个 S 形的非线性函数,当输入很大时,输出趋近于 1,梯度会趋近于 0。
不过这只是直观上的,那为什么要除以根号 d,而不是其他数呢?
所以更深层的原因是,选择根号 d,可以让输入 softmax 的分布,也就是 Q*K^T 更加趋近一个标准的正态分布,也就是均值为 0,方差为 1 的正态分布。
方差为 1,会使得训练过程,变的更加稳定,每一层的激活,不会产生较大的数据漂移。
到这里,我们的回答又更进一步了。不过我们还可以再继续往前延伸,跟其他面试候选人拉开差距。
其实 Transformer 在实际实现中,在获取输入词向量之后,也需要对 embedding 矩阵乘以根号 d。
原理是类似的,embedding 矩阵的初始化方式是 xavier,方差是 1/根号 d,因此乘以根号 d,可以让 embedding 矩阵的方差是 1,从而加速模型的收敛。
第四轮拷问:layernorm 是对哪一个维度进行的?
这个问题面试官想看看,你对 layernorm 的公式了不了解。
我们先给出公式:
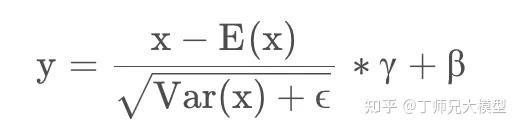
前面说过,layernorm 的输入维度是 [batch,seqlen,D],它是在一句话的序列内做归一化。
这跟 batch norm 是有区别的,batch norm 是在多句话之间做归一化。
其次 LayerNorm 是每个样本自己算均值和方差,不需要存全局的均值和方差,不管样本长还是短,均值和方差都是在每个样本内计算。
次 LayerNorm 是每个样本自己算均值和方差,不需要存全局的均值和方差,不管样本长还是短,均值和方差都是在每个样本内计算。
所以 layernorm 的归一化的维度是第二个维度 seqlen,也就是对每个单词 embedding 进行标准化。所以 layernorm 层里面的两个可学习参数的维度也是 D。
大模型岗位需求
大模型时代,企业对人才的需求变了,AIGC相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
零基础入门AI大模型
今天贴心为大家准备好了一系列AI大模型资源,包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
1.学习路线图




如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取

👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,**有需要的小伙伴,可以点击下方链接免费领取【保证100%免费】
**或扫描下方二维码领取 **



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











