






1. 流程简介
-
初始化隐藏状态:RNN的隐藏状态(通常称为
h)在开始时是一个零向量,或者是通过学习得到的初始化值。 -
输入当前字符:比如第一次输入是
B,这个字符会作为输入传入RNN。 -
计算当前隐藏状态:当前输入与上一次的隐藏状态(或者在第一次迭代时的初始隐藏状态)一起计算,RNN会计算一个新的隐藏状态。
计算公式如下:
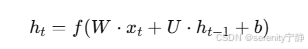
其中:
- xt 是当前输入(比如B、l、a、n、c等字符的向量表示)
- ht−1 是上一时刻的隐藏状态
- W,U,b 是网络的权重和偏置
- f是激活函数(比如tanh或者ReLU)
-
输出与下一步:新的隐藏状态
h_t会被传递到下一时刻,成为下一次迭代的输入。接着,第二次字符l会进入,并结合上次的隐藏状态继续计算,依此类推,直到整个单词(如“Blanc”)都处理完。
关键点:
-
记住上一次的隐藏状态:RNN的一个重要特性是它的 “记忆”,即它能通过隐藏状态传递信息,记住之前时间步的信息。这样,在处理每个新单词时,RNN不仅依赖当前的输入,还会结合之前的隐藏状态来做计算,从而实现时间步之间的信息传递和关联。
-
逐步计算:RNN模型是 逐步计算的,每次只处理一个字符或时间步的数据,并根据之前的隐藏状态调整当前的输出和隐藏状态。
2. 神经元内部结构图
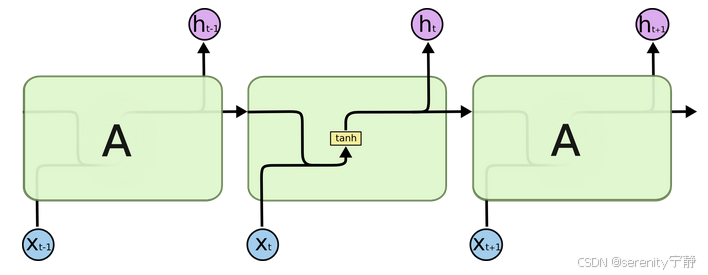
上一次神经元记忆的隐藏状态值加上这一次的输入,乘以权重再加偏置,最后使用tanh激活就得到了这一次的隐藏状态值,并顶替掉上一次记忆中的隐藏状态值。
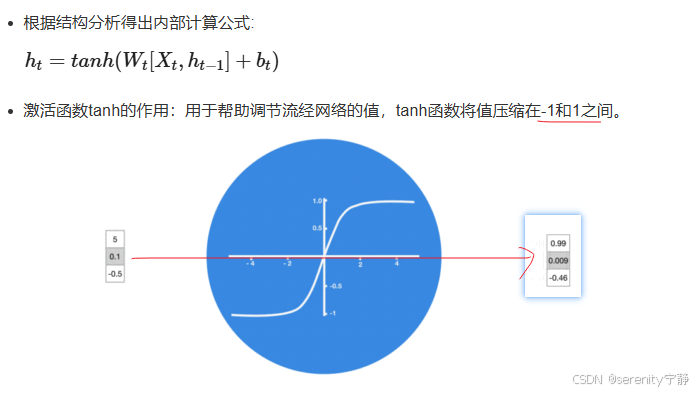
缺点:
-
梯度消失或爆炸介绍
-
根据反向传播算法和链式法则, 梯度的计算可以简化为以下公式:
-
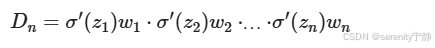
-
其中sigmoid的导数值域是固定的,在[0,0.25]之间。而一旦公式中的w也小于1,那么通过这样的公式连乘后,最终的梯度就会变得非常非常小,这种现象称作梯度消失。反之,如果我们人为的增大w的值,使其大于1,那么连乘够就可能造成梯度过大,称作梯度爆炸。
-
梯度消失或爆炸的危害:
如果在训练过程中发生了梯度消失,权重无法被更新,最终导致训练失败;梯度爆炸所带来的梯度过大,大幅度更新网络参数,在极端情况下,结果会溢出(NaN值)。
-
-
难以捕捉长期依赖:
- 由于梯度消失问题,传统RNN很难学习长距离的依赖关系,即难以记住输入序列中较早的信息,并将其用于影响后面的输出。
- 这意味着在处理文本、语音等长序列时,传统RNN很难理解上下文的含义。
- 无法并行计算:
- 由于RNN的循环结构,每个时间步的计算都依赖于前一个时间步的隐藏状态,因此无法进行并行计算,训练速度受到限制。
总结如下:
相比传统的全连接神经网络,RNN循环网络会记忆住上一次传入整个网络所造成每个神经元计算的结果,称之为隐藏状态。但是这种方案非常依赖上一层的记录,对于上上层的无法记录。可能导致前后上下文依赖关系不够强。于是映入了LSTM



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











