 Spark集群安装、部署与验证
Spark集群安装、部署与验证




实验目的
-
掌握Spark集群的分布式安装与部署方法
-
理解Spark集群的基本架构和工作原理
-
熟悉Spark集群的配置文件和关键参数设置
实验环境
-
操作系统:CentOS Stream 9(三台虚拟机)
-
主机名配置:
-
hadoop1(主节点)
-
hadoop2(工作节点)
-
hadoop3(工作节点)
-
-
Java环境:JDK 1.8.0_241
-
Spark版本:3.5.2
-
Hadoop版本:3.3.0(可选)
实验步骤
1. 系统准备
-
配置三台虚拟机的主机名分别为hadoop1、hadoop2、hadoop3
-
设置hosts文件,确保三台机器可以相互解析
-
在所有机器上安装JDK8并配置环境变量
-
配置hadoop1到其他节点的SSH免密登录
-
创建必要的目录结构:
mkdir -p /export/servers mkdir -p /export/software mkdir -p /export/data
2. Spark安装包下载与上传
-
从Apache Spark存档网站下载稳定版本:
wget https://archive.apache.org/dist/spark/spark-3.5.2/spark-3.5.2-bin-hadoop3.tgz -
将安装包上传到hadoop1节点的
/export/software目录
cd /export/software/
然后用rz命令上传或Xftp上传
rz3. Spark安装与配置
-
解压安装包:
tar -zvxf spark-3.5.2-bin-hadoop3.tgz -C /export/servers/ mv /export/servers/spark-3.5.2-bin-hadoop3 /export/servers/spark-3.5.2 -
配置环境变量(所有节点):
echo 'export SPARK_HOME=/export/servers/spark-3.5.2' >> /etc/profile echo 'export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin' >> /etc/profile source /etc/profile或者
vi /etc/profile
source /etc/profile
4. Spark集群配置
-
配置spark-env.sh:
cd /export/servers/spark-3.5.2/conf cp spark-env.sh.template spark-env.sh添加以下内容:
export JAVA_HOME=/export/servers/jdk1.8.0_241 export SPARK_MASTER_HOST=hadoop1 export SPARK_MASTER_PORT=7077 export HADOOP_HOME=/export/servers/hadoop-3.3.0 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop -
配置workers文件:
cp workers.template workers修改为:
hadoop2 hadoop3
5. 配置文件分发
-
将Spark安装目录分发到其他节点:
scp -r /export/servers/spark-3.5.2 hadoop2:/export/servers/ scp -r /export/servers/spark-3.5.2 hadoop3:/export/servers/ -
分发环境变量配置:
scp /etc/profile hadoop2:/etc/ scp /etc/profile hadoop3:/etc/ -
在其他节点上使环境变量生效:
source /etc/profile
6. 启动Spark集群
在主节点hadoop1上执行:
/export/servers/spark-3.5.2/sbin/start-all.sh7. 验证集群状态
-
使用jps命令查看进程:
-
hadoop1上应有Master进程
-
hadoop2和hadoop3上应有Worker进程
-



2.访问Web UI界面:
http://hadoop1:8080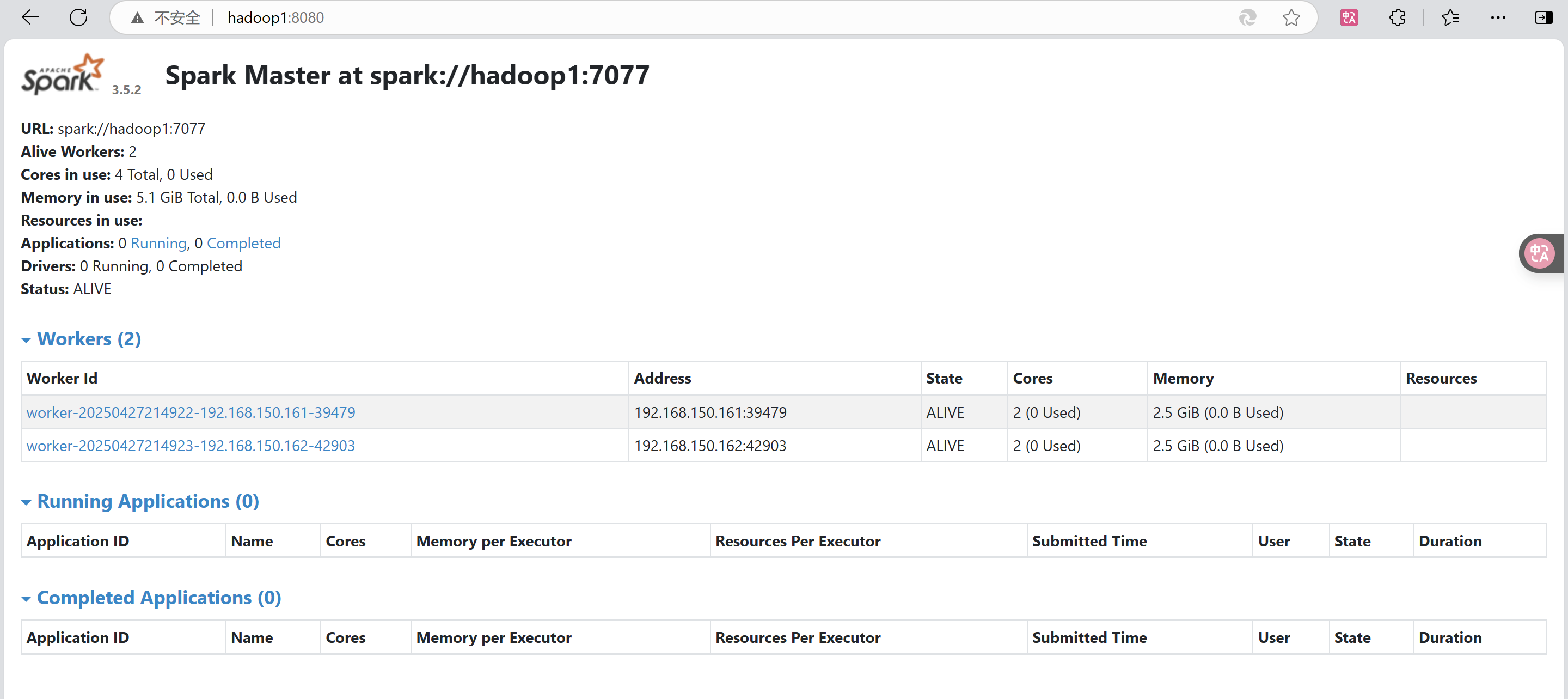
实验验证
1. 集群状态检查
# 在主节点执行
/export/servers/spark-3.5.2/bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master spark://hadoop1:7077 \
/export/servers/spark-3.5.2/examples/jars/spark-examples_2.12-3.5.2.jar 1002. Web UI验证
在浏览器中访问http://hadoop1:8080,应能看到:
-
1个活跃的Master节点
-
2个活跃的Worker节点
-
集群资源使用情况

常见问题及解决方案
1. 端口冲突问题
-
现象:启动失败,端口被占用
-
解决方案:
netstat -tunlp | grep 7077 # 查看端口占用情况 kill -9 <PID> # 结束占用进程
2. SSH连接问题
-
现象:节点间无法通信
-
解决方案:
-
检查
/etc/hosts文件配置 -
验证SSH免密登录是否设置正确
-
检查防火墙状态:
systemctl stop firewalld systemctl disable firewalld
-
3. 环境变量不生效
-
现象:命令找不到
-
解决方案:
-
检查
/etc/profile文件配置 -
执行
source /etc/profile -
确认PATH变量包含Spark路径
-
实验总结
通过本次实验,我们成功完成了:
-
Spark集群的分布式安装与部署
-
多节点环境下的配置文件管理
-
Spark集群的启动与验证
关键点:
-
主机名和hosts文件配置必须正确
-
环境变量配置要完整且同步到所有节点
-
workers文件中只需包含工作节点
-
注意避免与Hadoop的
start-all.sh命令冲突
附录
1. 常用Spark管理命令
| 命令 | 功能 |
|---|---|
start-all.sh | 启动整个集群 |
stop-all.sh | 停止整个集群 |
start-master.sh | 仅启动Master |
start-workers.sh | 仅启动Workers |
2. 重要配置文件说明
| 文件 | 作用 |
|---|---|
| spark-env.sh | 集群环境变量配置 |
| workers | 工作节点列表 |
| spark-defaults.conf | 默认运行参数配置 |
3. 参考资源
-
Spark官方文档:Overview - Spark 3.5.5 Documentation
-
Spark集群部署指南:Cluster Mode Overview - Spark 3.5.5 Documentation

















 3728
3728



 到【灌水乐园】发言
到【灌水乐园】发言








