




 博客介绍了借助Java的HTML解析框架Jsoup进行网页爬取的方法。给出了爬虫代码文件,如WebBookCrawler.java、WebBookHelper.java、App.java等,只需传入小说URL及相关CSS选择器即可进行爬取,还提到可借助浏览器解决CSS选择器编写问题,并展示了爬取结果。
博客介绍了借助Java的HTML解析框架Jsoup进行网页爬取的方法。给出了爬虫代码文件,如WebBookCrawler.java、WebBookHelper.java、App.java等,只需传入小说URL及相关CSS选择器即可进行爬取,还提到可借助浏览器解决CSS选择器编写问题,并展示了爬取结果。
借助java的html解析框架Jsoup,可以方便爬取网页,该框架用法见Java html解析器之Jsoup。
代码
该爬虫只有一个文件
WebBookCrawler.java
package top.sidian123;
import org.jsoup.HttpStatusException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.nodes.TextNode;
import javax.print.Doc;
import java.io.*;
import java.nio.charset.Charset;
import java.util.List;
/**
* 爬取网路小说的爬虫
* @author sidian
* @date 2019/5/29 15:21
*/
public class WebBookCrawler {
/**
* 起始页
*/
private String url;
/**
* 每一章标题的选择器
*/
private String titleSelector;
/**
* 每一章正文的选择器
*/
private String contentSelector;
/**
* 下一章链接的css选择器
*/
private String nextChapterSelector;
/**
* 爬取后文件保存位置和命名,默认当前位置
*/
private String filename="./小说.txt";
/**
* 是否以添加的方式写入文件,默认false
*/
private boolean append=false;
/**
* 用于存储到文件中
*/
private BufferedWriter write;
public WebBookCrawler(String url,String titleSelector,String contentSelector,String nextChapterSelector){
this.url=url;
this.titleSelector=titleSelector;
this.contentSelector=contentSelector;
this.nextChapterSelector=nextChapterSelector;
}
public WebBookCrawler(String url,String titleSelector,String contentSelector,String nextChapterSelector,String filename){
this.url=url;
this.titleSelector=titleSelector;
this.contentSelector=contentSelector;
this.nextChapterSelector=nextChapterSelector;
this.filename=filename;
}
/**
* 爬取数据,默认延迟200ms
* @throws IOException
* @throws InterruptedException
*/
public void crawl() throws IOException, InterruptedException {
crawl(200);
}
/**
* 爬取数据,异常时重试10次
* @param delay
* @throws IOException
* @throws InterruptedException
*/
public void crawl(int delay) throws IOException, InterruptedException {
int count=10;//重试次数
boolean flag=true;
while (flag){
try{
_crawl(delay);
flag=false;
}catch (Exception e){
if(--count!=0){
System.out.println("莫名错误,原因:"+e.getMessage());
System.out.println("开始第"+(10-count)+"次重试");
flag=true;
Thread.sleep(1000);
//设置为添加模式,防止文件被覆盖
this.append=true;
}else{
throw e;
}
}
}
}
/**
* 设置append属性
* @param append
*/
public void setAppend(Boolean append){
this.append=append;
}
/**
* 开始爬出数据
* @param delay 每次读取网页的延迟时间,单位ms,用于反爬虫
* @throws IOException 获取网页和保存文件时错误,抛出该异常
*/
private void _crawl(int delay) throws IOException, InterruptedException {
try{
//初始化
write=new BufferedWriter(new FileWriter(filename, Charset.forName("utf-8"),append));
int count=10;//文件写入的刷新间隔
//遍历所有网页
while(true){
//获取文档
Document document=getDocument(url);
//获取小说内容
getChapter(document);
//判断html是否有“下一页”的链接
Element link=document.selectFirst(nextChapterSelector);
if(link==null){//没有“下一页”
//爬取完毕,跳出循环
break;
}
//获取下一页链接
url=link.attr("abs:href");
//每十章刷新一次
if(--count==0){
write.flush();
count=10;
}
//延迟
if(delay>0){
Thread.sleep(delay);
}
}
}finally {
write.close();
}
}
/**
* 获取该章节的标题、正文,并保存在文件中
* @param document
* @throws IOException
*/
private void getChapter(Document document) throws IOException {
//获取标题
Element titleEle=document.selectFirst(titleSelector);
String title=getContent(titleEle).trim();
write.write(title+"\n\n");
System.out.println("已获取章节:"+title);
//获取正文
Element contentEle=document.selectFirst(contentSelector);
String content=getContent(contentEle).trim();
write.write(content+"\n\n");
}
/**
* 获取该元素中的文本内容。
* 会遍历子元素
* @param element
* @return
*/
private String getContent(Element element) {
List<TextNode> textNodes=element.textNodes();
StringBuilder stringBuilder=new StringBuilder();
textNodes.forEach((node)->{
if(!node.text().trim().isEmpty()){
stringBuilder.append(node.text().trim()+"\n\n");
}
});
return stringBuilder.toString();
}
/**
* 从url上获取文档,为了防止反爬虫,这是一些头字段
* 如果失败,会重试10次
* @param url
* @return
*/
private Document getDocument(String url) throws IOException {
int count=10;//重试次数
boolean flag=true;
Document document=null;
while (flag){
try{
document = Jsoup.connect(url)
.userAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36")
.get();
flag=false;
}catch (IOException e){
if(count--!=0){
System.out.println("网页获取失败,原因:"+e.getMessage());
System.out.println("开始第"+(10-count)+"次重试");
}else{
throw e;
}
}
}
return document;
}
}
用法很简单,传入小说url、标题css选择器、内容css选择器、下一章链接css选择器,即可。下面给出一个helper类:
WebBookHelper.java
package top.sidian123;
import java.io.IOException;
/**
* @author sidian
* @date 2019/5/29 16:49
*/
public class WebBookHelper {
public static void 斗破苍穹() throws IOException, InterruptedException {
WebBookCrawler crawler=new WebBookCrawler("https://www.biqukan.com/3_3037/1349252.html",
"#wrapper > div.book.reader > div.content > h1",
"#content",
"#wrapper > div.book.reader > div.content > div.page_chapter > ul > li:nth-child(3) > a",
"斗破苍穹.txt");
crawler.crawl();
}
public static void 姐妹花的最强兵王() throws IOException, InterruptedException {
WebBookCrawler crawler=new WebBookCrawler("https://www.81xzw.com/book/148528/0.html",
"body > div.novel > h1",
"#content",
"body > div.novel > div:nth-child(5) > a:nth-child(3)",
"姐妹花的最强兵王.txt");
crawler.crawl();
}
}
下面爬取一本小说:
App.java
package top.sidian123;
import java.io.IOException;
/**
* Hello world!
*
*/
public class App
{
public static void main( String[] args ) throws IOException, InterruptedException {
WebBookHelper.姐妹花的最强兵王();
//WebBookHelper.斗破苍穹();
}
}
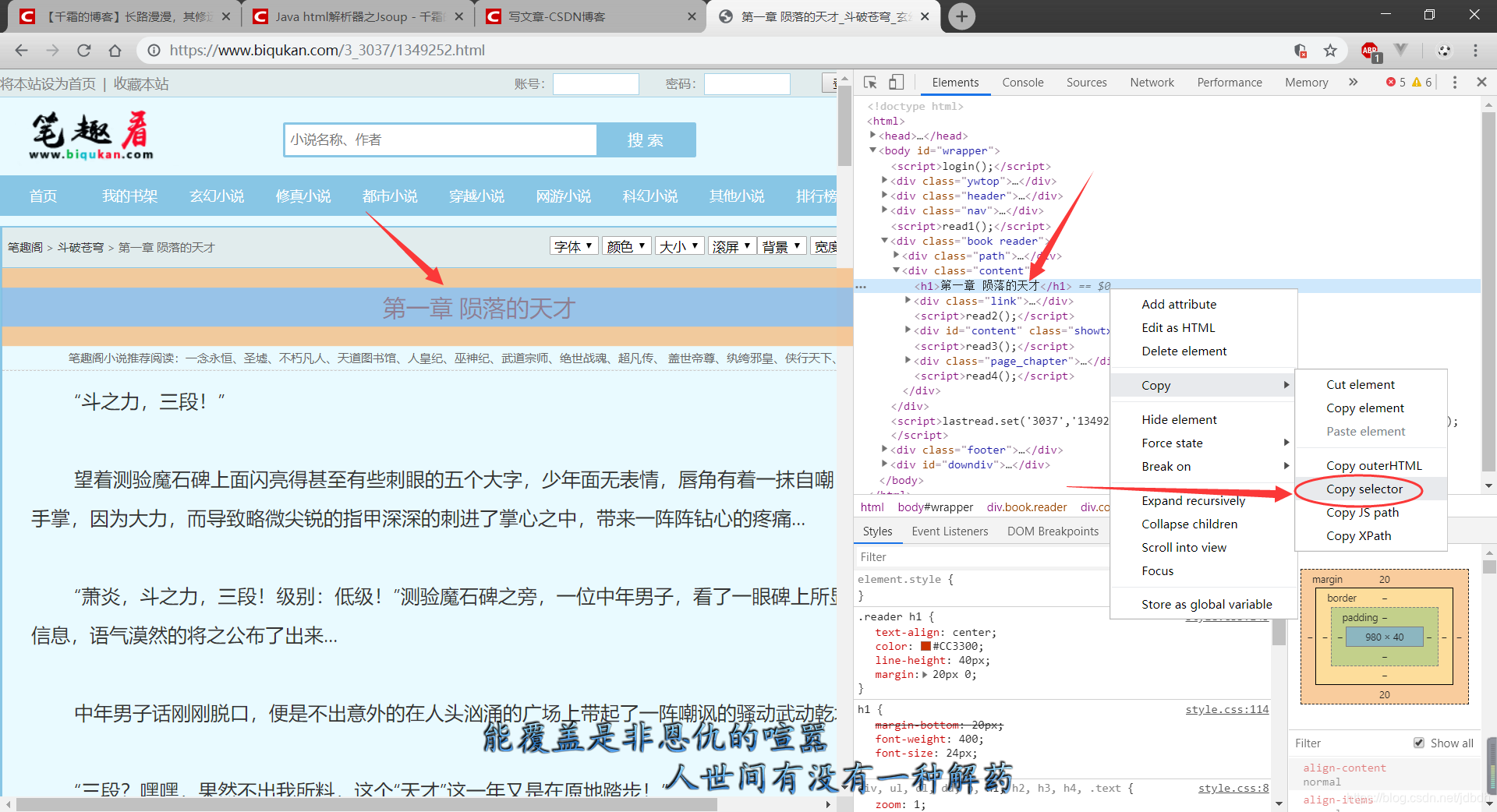
css选择器不会写???没关系!!借助浏览器一步到位!!!
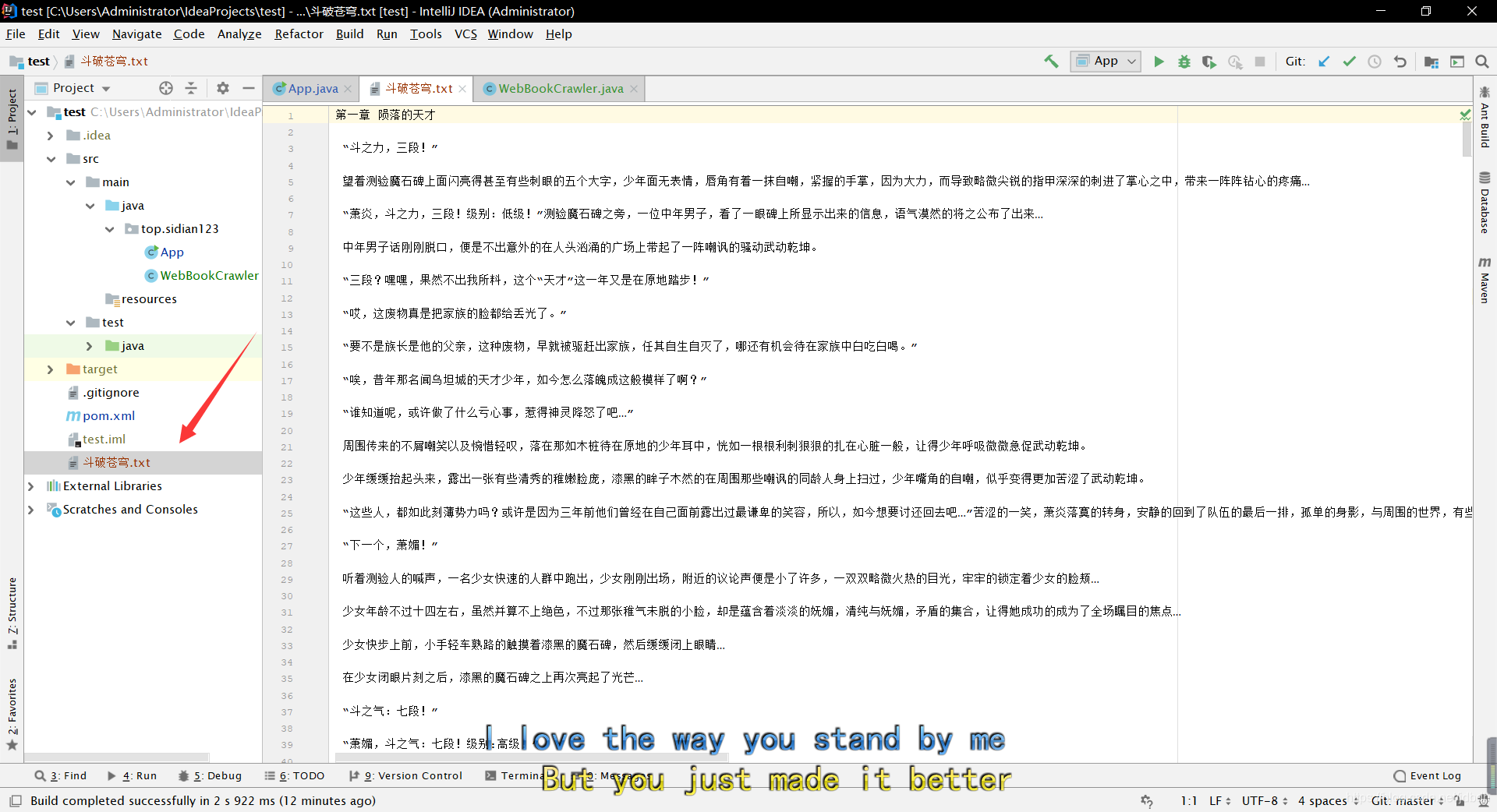
爬取结果

















 1311
1311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









