



引言
在大数据体系中,HDFS(Hadoop Distributed File System) 是最核心的存储组件之一。它通过分布式架构解决了传统文件系统在大规模数据场景下的存储与容灾难题。
然而,很多初学者在第一次接触 HDFS 时,常常会困惑于以下问题:
-
数据到底是如何被切分并写入到集群中的?
-
客户端读取文件时,为什么可以支持高并发?
-
如果 NameNode 挂掉了,集群还能正常运行吗?
-
面对海量数据时,NameNode 的内存瓶颈如何解决?
本文将围绕 HDFS 的写操作、读操作、高可用机制以及联邦架构 展开讲解,并结合示意图帮助大家快速理解 HDFS 的底层原理。希望通过这篇文章,能够让你对 HDFS 的运行机制有一个清晰、系统的认识。
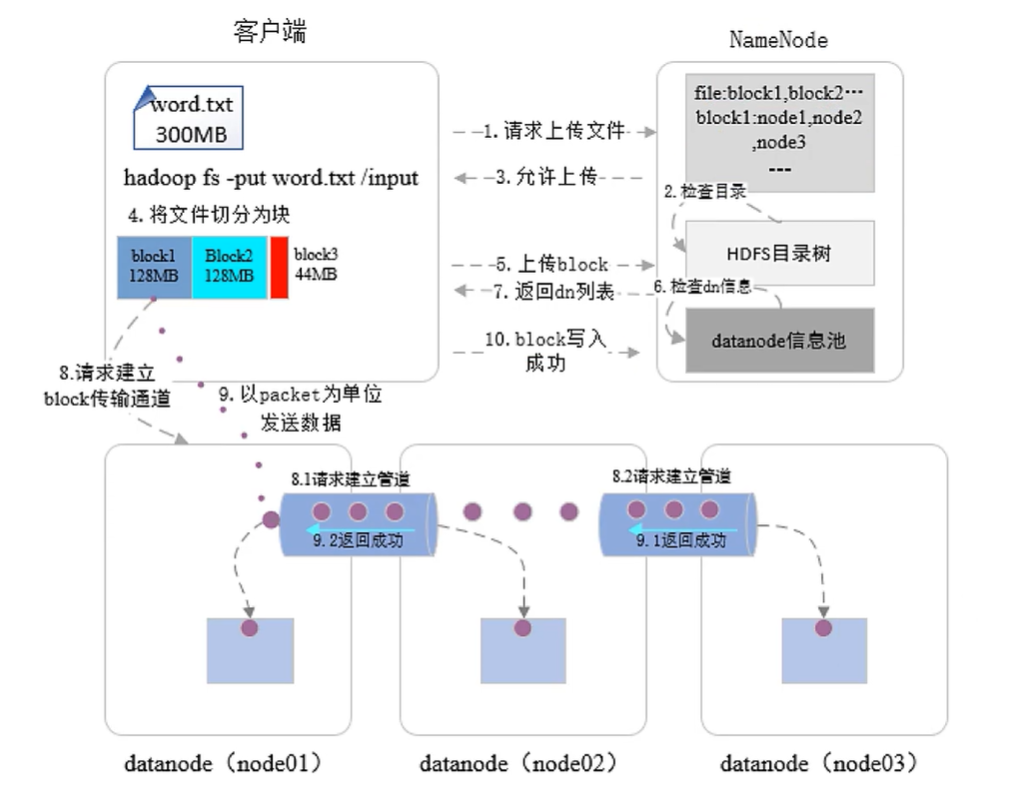
一、写操作(不支持并发写)
-
客户端向 NameNode 发起写请求。
-
NameNode 进行权限校验。若校验通过,则允许上传文件。
-
客户端将文件切分为 Block(默认每块 128 MB)。
-
按顺序依次上传 Block(Block1 → Block2 → Block3)。
-
NameNode 根据副本放置策略选择存储节点:
-
第一份:优先选择与客户端最近的机架中最空闲的节点;
-
第二份:选择不同机架中的空闲节点;
-
第三份:选择第二个机架内的其他空闲节点。
-
-
客户端与选定的 3 个 DataNode 建立传输通道。数据以 数据包(Packet) 形式发送:
-
Block1 → DataNode1 → DataNode2 → DataNode3
-
写入完成后,DataNode3 依次向上返回“写入成功”信号,最终反馈给客户端。
-
-
客户端收到成功响应后继续写入下一个 Block,直到文件全部写入完成。
-
文件写入结束后,客户端向 NameNode 发送报告,NameNode 在内存中更新文件的元数据信息(文件分块情况、存储位置等)。
-
DataNode 定期向 NameNode 发送心跳,若发现存在不一致数据,NameNode 会下发删除或复制指令,实现数据容灾。
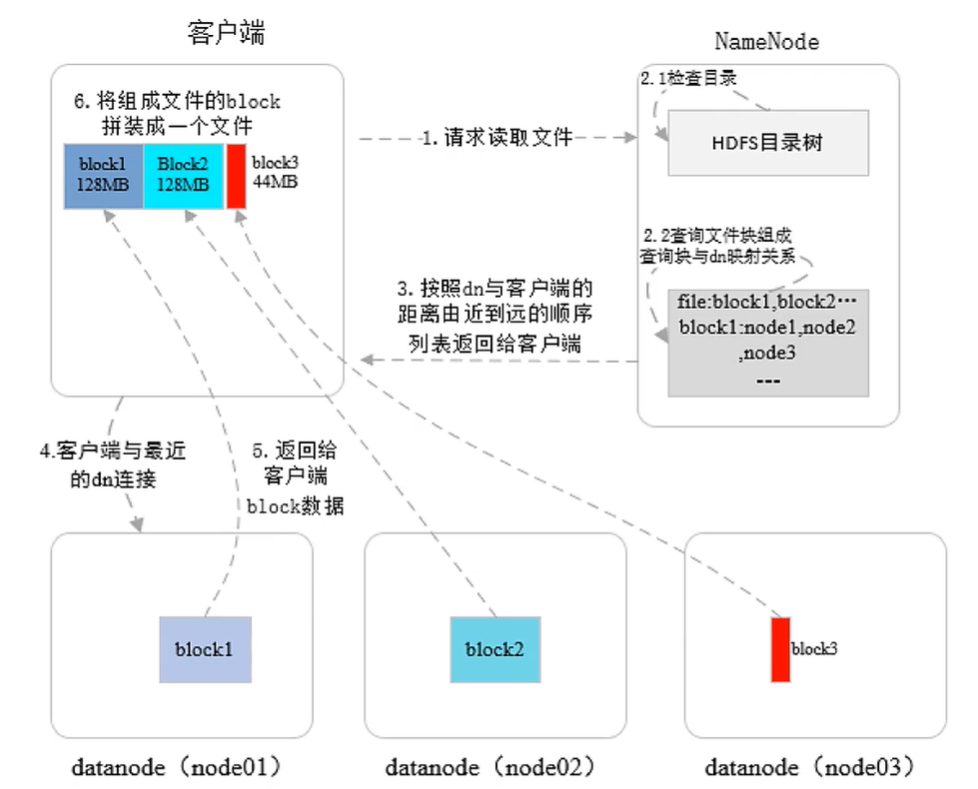
二、读操作(支持并发读)
-
客户端向 NameNode 发起读请求。
-
NameNode 进行权限校验,返回文件的元数据信息(包含各 Block 的存储位置,并按距离由近到远排序)。
-
客户端根据返回信息从多个 DataNode 并发获取各 Block 数据,并在本地拼装成完整文件。
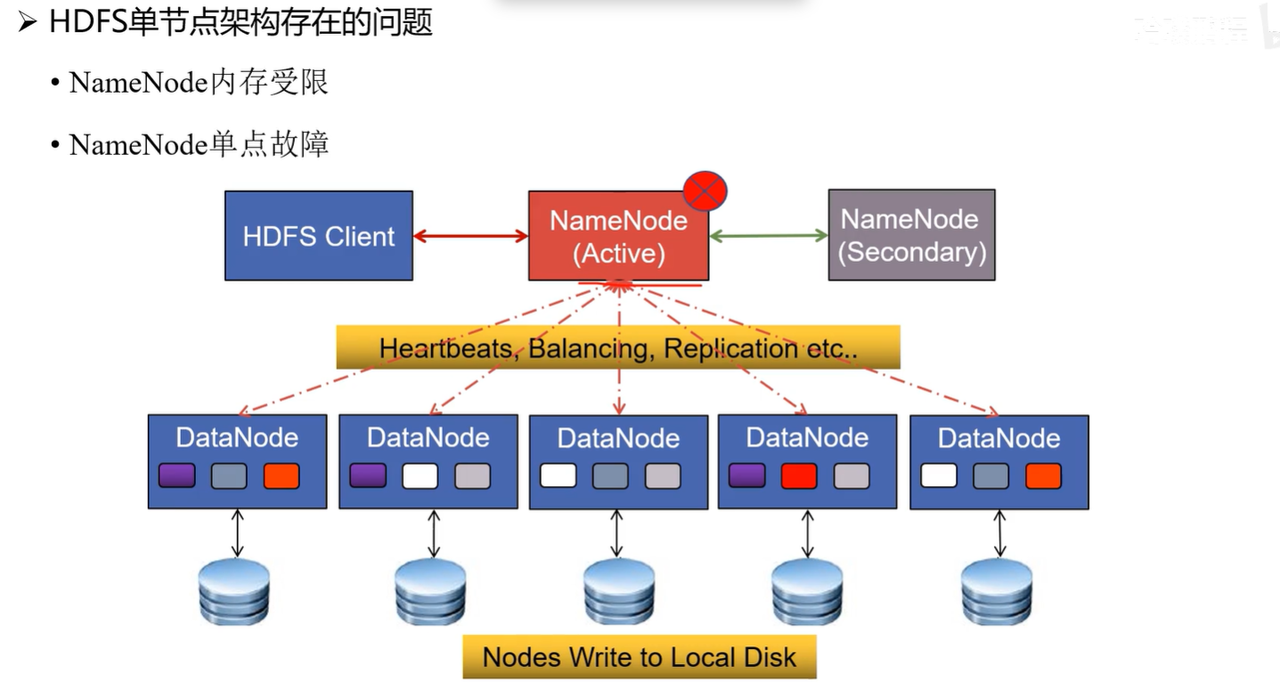
三、高可用机制(HA)
-
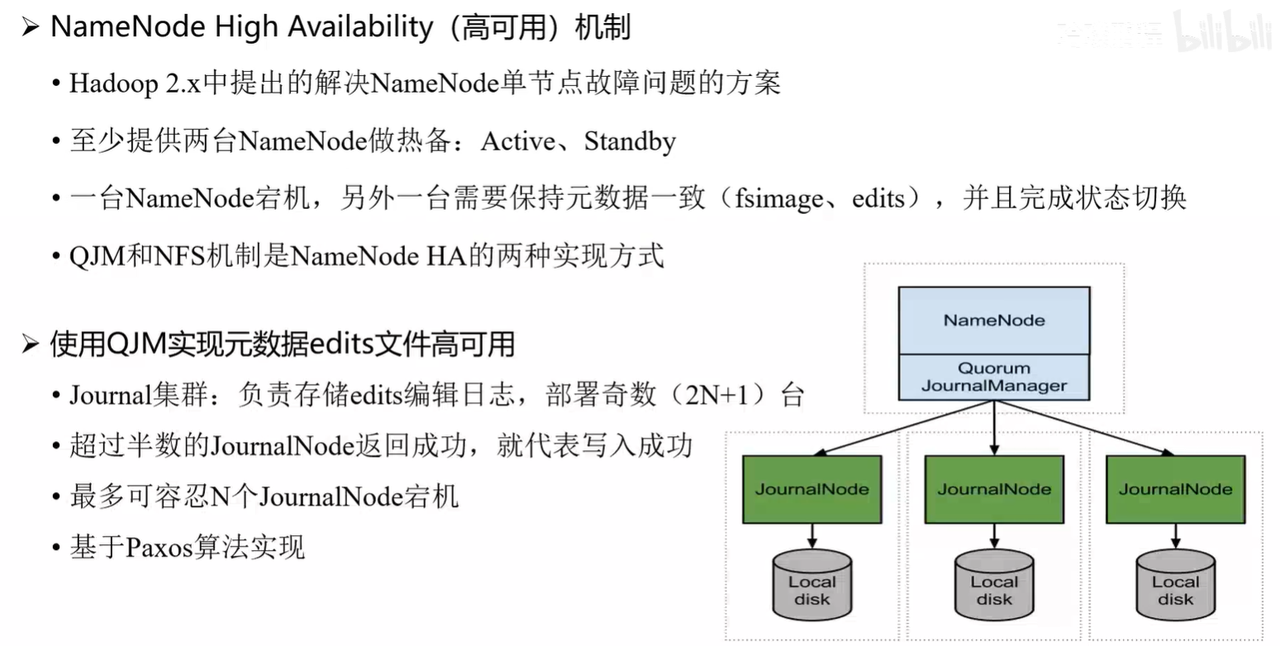
为避免单点故障,HDFS 引入 NameNode 高可用(HA) 机制。
-
至少部署两台 NameNode:一台为 Active,一台为 Standby。
-
当 Active 节点故障时,Standby 会自动切换为 Active,保证服务连续性。
-
元数据写入时通过 JournalNode 集群 进行日志同步,需超过半数节点确认后才算写入成功(通常为奇数个节点)。
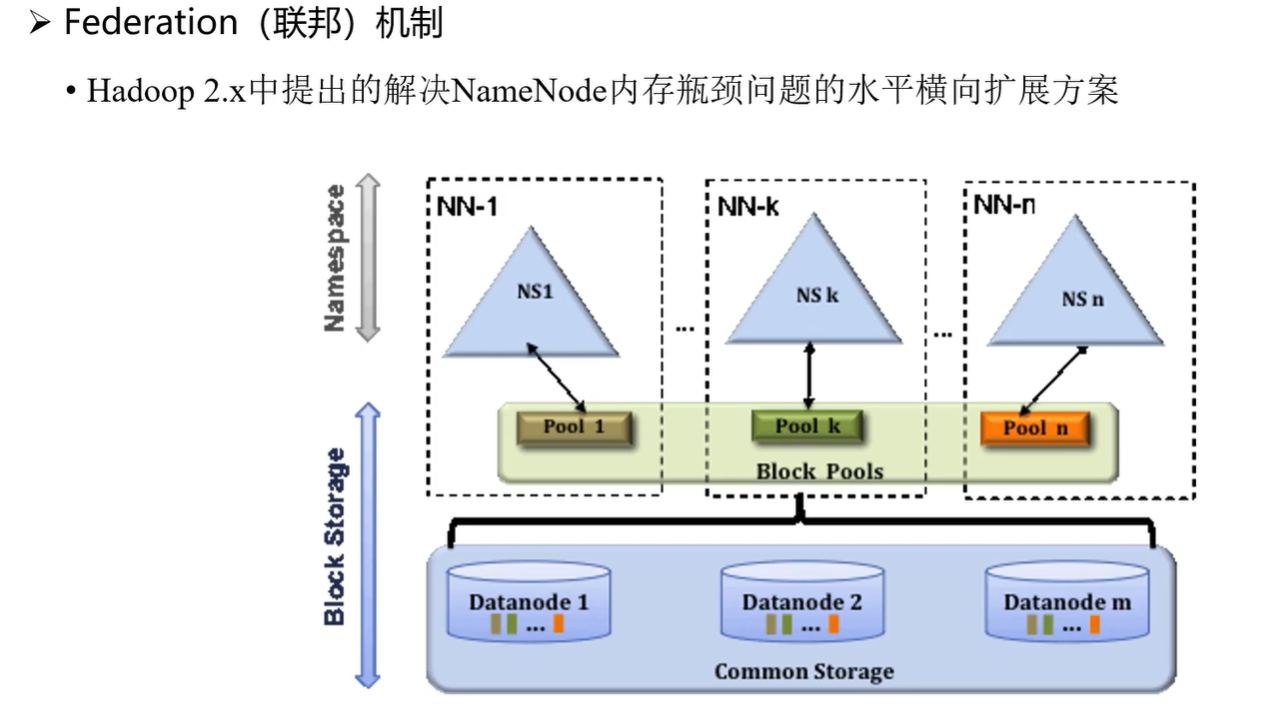
四、内存受限的解决方案:联邦机制
-
单个 NameNode 的内存存在瓶颈,难以支撑超大规模集群。
-
HDFS 提供 联邦机制(Federation),允许多个 NameNode 并存。
-
集群中的命名空间和数据块管理可由不同的 NameNode 分担,从而扩展整体内存与处理能力。
五、总结
HDFS 通过 副本机制、心跳机制、高可用架构与联邦机制,在保障数据安全性和可靠性的同时,也提升了集群的可扩展性与容灾能力。
对于日常开发者而言,理解 HDFS 的读写流程和高可用方案,有助于在大数据项目中更高效地设计与排查问题。

















 748
748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









