



一、研究背景与挑战
想象一下,如果我们想训练一个能够自主浏览网页、完成购物任务的AI助手,传统方法需要让它在真实网站上进行成千上万次的尝试和犯错。这不仅成本高昂,而且可能造成安全隐患。这正是当前大模型(LLM)智能体在强化学习训练中面临的核心困境。
具体来说,传统的LLM智能体强化学习面临以下三大挑战:
- \1. 高昂的交互成本:需要与真实环境进行大量昂贵的交互,导致样本效率低下
- \2. 任务与奖励问题:真实世界环境中缺乏多样化的可扩展任务,奖励信号往往不可靠且稀疏
- \3. 基础设施复杂性:设置和管理强化学习环境复杂,存在安全隐患,缺乏可靠的重置机制
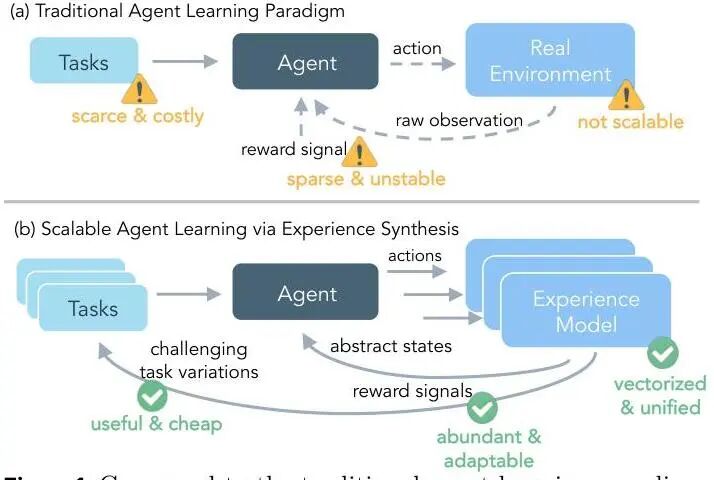 传统方法与DreamGym对比
传统方法与DreamGym对比
图1:传统代理学习范式(上)面临任务稀缺且成本高昂、奖励信号稀疏且不稳定以及真实环境不可扩展等问题。DreamGym 的经验合成方法(下)通过丰富且适应性强的合成经验、向量化和统一的经验模型以及有用且廉价的任务生成来解决这些挑战。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
二、DreamGym:革命性的解决方案
DreamGym是首个专门为自主智能体设计的统一经验合成框架。它的核心思想是:不再依赖昂贵的真实环境试错,而是通过合成高质量的经验数据来训练智能体。
这种方法的关键创新在于,它不是简单地复制环境,而是将环境动态提炼成一个基于推理的经验模型。这个模型能够通过逐步推理,生成一致的状态转移和反馈信号。
核心优势
- • 在非强化学习友好环境中实现训练:在WebArena等传统强化学习难以应对的环境中,性能提升超过30%
- • 极大降低真实交互需求:仅使用合成交互即可达到传统方法80,000次真实交互的效果
- • 模拟到真实的完美迁移:在使用不到10%真实数据的情况下,性能提升超过40%
三、技术架构详解
DreamGym由三个相互协作的核心组件构成:
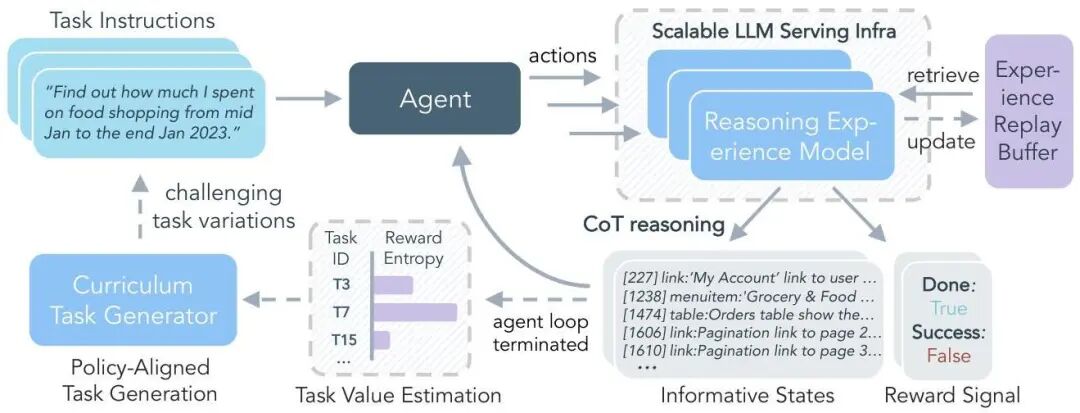 DreamGym框架概览
DreamGym框架概览
图2:DreamGym框架集成了推理经验模型、经验回放缓冲区和课程任务生成器。系统通过CoT推理生成信息丰富的状态和奖励信号,同时根据策略对齐的任务生成调整任务难度。
1. 推理经验模型 (Mexp)
这是DreamGym的"大脑"。与传统方法不同,它不处理复杂的原始数据(如HTML代码或像素),而是在一个抽象的文本状态空间中运行。
举个例子:在网页购物任务中,传统方法需要处理整个网页的HTML代码,而DreamGym只需要一个清晰的可点击元素列表,比如:
- • 按钮1:添加到购物车
- • 按钮2:查看详情
- • 按钮3:返回首页
更重要的是,模型通过思维链(Chain-of-Thought, CoT)推理来预测状态转换。当智能体执行一个动作时,模型会生成一段推理过程,解释为什么会发生特定的状态变化以及应该给予什么奖励。
模型在推理时会利用三种上下文信息:
- • 交互历史:保持多轮交互的一致性
- • 任务指令:根据目标解释动作
- • 检索到的经验:从历史中寻找相似经验作为参考
训练目标结合了推理生成和状态预测:

2. 经验重放缓冲区
这是一个动态的"记忆库"。它最初用离线的真实数据进行初始化,然后随着智能体与经验模型的交互,不断丰富新的合成轨迹。
这种设计确保了:
- • 合成经验始终与智能体的当前能力相关
- • 为经验模型提供可靠的参考,减少"幻觉"
- • 智能体策略与经验模型共同进化
3. 课程任务生成器
这个组件负责自适应地生成训练任务。它的聪明之处在于使用奖励熵来判断任务难度是否合适。
任务组的奖励熵计算公式:

其中 代表不同奖励类别(成功/失败)的比例。
简单理解:
- • 高奖励熵 → 任务产生大致平衡的成功和失败 → 难度刚好合适
- • 低奖励熵 → 任务过于简单或过于困难 → 学习效率低
系统会持续生成高熵任务的变体,创建一个逐步提升难度的自然课程。
四、工作流程
 经验模型推理示例
经验模型推理示例
图5:示例交互展示了推理经验模型如何通过显式CoT推理处理代理动作,以生成一致的状态转换和适当的奖励信号。
DreamGym的完整训练循环包括以下步骤:
- \1. 智能体与经验模型交互:生成合成的训练轨迹
- \2. 策略更新:使用PPO或GRPO等标准强化学习算法更新策略
- \3. 任务自适应生成:根据奖励熵不断引入新的挑战性任务
- \4. 经验缓冲区更新:将新轨迹加入记忆库
该框架还支持模拟到真实迁移:先在DreamGym中进行广泛训练,然后用少量真实数据进行微调,即可部署到真实环境。
五、实验结果与性能分析
5.1 在"不友好"环境中的突破
在WebArena这样缺乏可靠重置机制和一致奖励信号的环境中,传统强化学习几乎无法使用。而DreamGym首次实现了有效训练,在所有测试的模型(Llama-3.2-3B、Llama-3.1-8B、Qwen-2.5-7B)上都取得了超过30%的成功率提升。
5.2 媲美传统强化学习
在WebShop和ALFWorld等强化学习友好环境中,仅使用合成数据训练的智能体,性能与使用80,000次真实交互训练的传统方法相当。这证明了合成经验的质量足以支持有效的策略学习。
5.3 模拟到真实迁移的惊人效果
最令人印象深刻的结果来自DreamGym-S2R(Sim-to-Real)方法:
- • 性能提升:相比基线超过40%
- • 数据需求:**不到10%**的真实世界数据
- • 训练成本:降低到传统方法的1/3到1/5
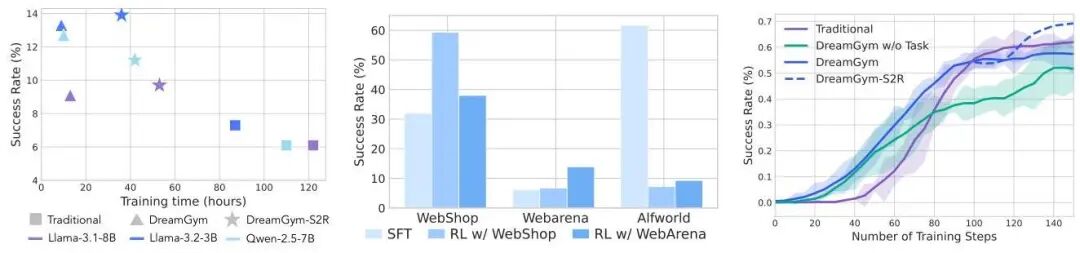 性能对比
性能对比
图3:左图展示训练效率,DreamGym以更少时间达到更好性能;中图显示跨领域泛化能力;右图展示训练曲线的有效性。
六、深入分析:为什么有效?
6.1 组件重要性验证
通过消融实验(逐个移除组件测试)发现:
任务生成器的影响:
- • 移除后成功率下降6.0-6.6%
- • 证明了多样化、循序渐进任务的重要性
经验模型关键组件:
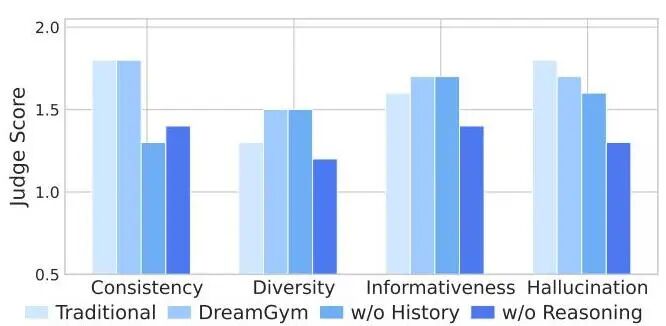 组件分析
组件分析
图4:组件分析显示不同设计选择对一致性、多样性、信息量和幻觉控制的影响。完整的DreamGym模型在所有维度达到最佳平衡。
关键发现:
- • 移除交互历史 → 因果一致性大幅下降
- • 移除CoT推理 → 信息量降低,幻觉增加
- • 完整模型 → 所有指标达到最优平衡
6.2 数据效率
经验模型展现出惊人的数据效率:仅需2,000-10,000个离线样本就能达到具有竞争力的性能,使其在资源受限环境中也具有实用性。
七、结语
DreamGym 通过使强化学习在大语言模型(LLM)代理的先前难以处理的领域中实现有效训练,同时大幅减少可行领域的数据和计算需求,从而解决了强化学习中的基本可伸缩性挑战。该方法表明,关注与学习相关的信号而非环境保真度可以带来更高效、更有效的代理训练。
该框架能够在“非强化学习就绪”环境中实现强化学习,同时在传统强化学习设置中提供显著的效率提升,这使其成为扩展自主代理开发的实用解决方案。模拟到现实的迁移能力为开发基础代理模型提供了清晰的路径,这些模型可以在多样化的合成经验上进行预训练,然后以最少的额外数据收集适应现实世界任务。
论文中提供的理论基础支持了在足够准确的合成环境中训练的策略可以证明地改善真实环境中的性能的直觉,将 DreamGym 确立为一种实用的工具和一种理论上可靠的可扩展代理学习方法。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

















 72
72

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









