



在大模型快速演进的时代,多模态能力已成为衡量下一代智能系统的重要指标。Meta在Llama3.1之后推出的Llama3.2系列中,Vision版本(Llama3.2-Vision大幅增强了图像理解能力,并保持了较高的推理效率,为边缘设备推理与轻量级多模态应用提供了坚实基础。
Llama3.2-Vision提供vision11B与90B两种模型尺寸,最大支持128K tokens上下文窗口,并可处理最高1120×1120的高分辨率图像,为复杂视觉场景提供充足的细粒度信息。
一、总体架构
Llama3.2-Vision 继承了Llama系列一贯的Decoder-only Transformer 架构,并在此基础上引入视觉模块,使模型具备统一的图文理解能力。从整体上看,它依然保持了Llama 3.x的核心设计理念:在保持语言模型能力不受影响的前提下,引入高效而稳定的视觉分支。
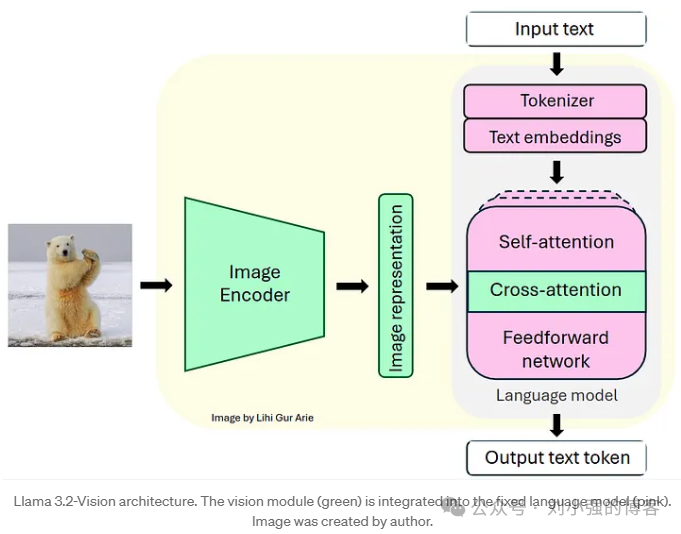
- 大语言模型:基于Llama 3.1的冻结语言模型
Llama3.2-Vision的语言部分完全基于预训练好的Llama 3.1文本模型,在整个多模态扩展中,语言模型参数保持冻结。
- 视觉编码器:ViT-H/14
Llama 3.2 Vision对视觉分辨率进行了工程化优化(如Tile机制、全局/局部特征融合),但核心承担图像编码任务的依旧是 ViT-H/14。
- 视觉适配器(Cross-attention)
视觉编码器生成的图像特征不会直接输入语言模型,而是通过Cross-attention完成跨模态对齐。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
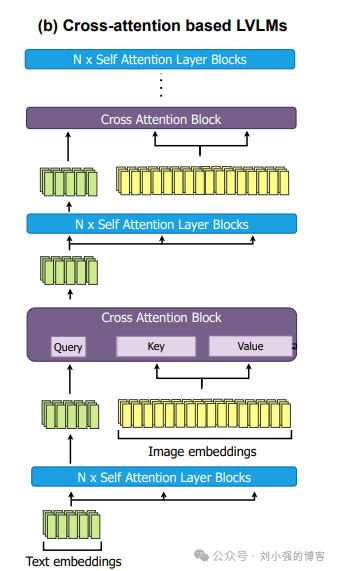
其架构上和Flamingo之类的模型是类似的,都是基于一个视觉适配器将图像特征和文本特征进行深度融合。
二、图像分块与预处理机制
Llama3.2-Vision模型在图像输入阶段进行了系统化的预处理与分辨率适配设计,使其能够在固定的Tile结构下高效处理任意比例的图像。本章将从图像分辨率适配、Tile划分、Patch映射、位置编码机制到局部/全局特征融合等方面,对其视觉编码器的核心流程进行完整解析。
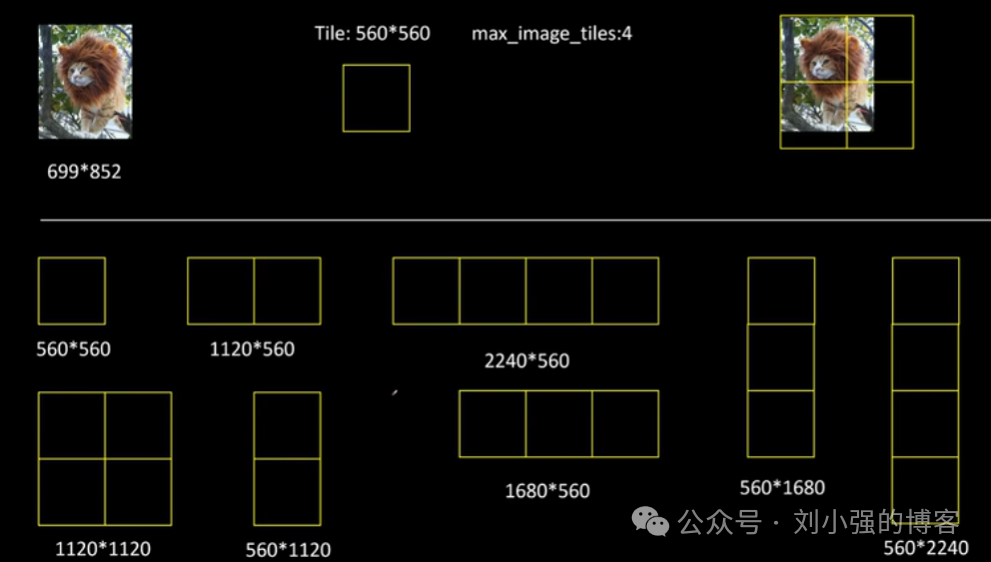
- Tile适配(Tile-Based Adaptation)
Llama3.2-Vision的视觉编码器定义了一个固定的Tile大小为560×560像素。单张输入图片(例如 699×852像素)最多可占据四个Tile,通过八种不同的Tile组合方式,对应不同的有效图像分辨率。
- 适配原则: 模型会根据不改变宽高比的缩放策略,找到能将图片完全放入且缩放比例最小的Tilt组合。这确保了输入信息最少的损失。
-
最终输入尺寸: 图片最终会适配到选定的组合中,最大可1120×1120像素(例如四个560×560Tile的组合)。Tile内超出图片部分的区域,会使用零填充 (Zero Padding)。
-
最终数据结构: 预处理后的图像像素值被整理成4×3×560×560的结构(最多4个Tile,3个RGB通道,每个Tile 560×560)。
-
掩码机制 (Masking): 模型通过mask机制来标记当前图片实际占用了多少个Tile(1个、2个或4个),实现对不同长宽比和分辨率图片的灵活处理。

2.Patch划分与嵌入(embedding)
适配后的图像被送入视觉编码器前,需要进一步划分为更细粒度的 Patch。
- Patch划分: 每个560×560的Tile被划分为40×40个Patch,总计1600个Patch。每个Patch的像素大小为14×14。
- 特征映射: 每个Patch的3×14×14像素数据(RGB 三通道)被展平,并通过线性映射转换为1280维的特征向量(类似于 ViT 的 Hidden Size)。
- 张量形状调整: 最终的特征张量形状变为 4×1600×1280(4 个Tile,每个Tile 1600 个 Patch,维度 1280)。
3.位置编码
为赋予模型对图像空间结构的理解,Llama3.2-Vision引入了两种关键的位置编码:
- Tile位置编码:针对8种不同的Tile组合方式,模型学习了8组可学习的Tile位置编码。这使得模型能感知不同Tile之间的相对空间关系。
- 分类 Token (Class Token): 每个Tile都会被额外增加一个特殊的分类Token。
- Patch位置编码:针对每个Tile内部的Patch,模型使用1601个(1600 个 Patch + 1 个 Class Token)长度为1280的可学习Patch位置编码。
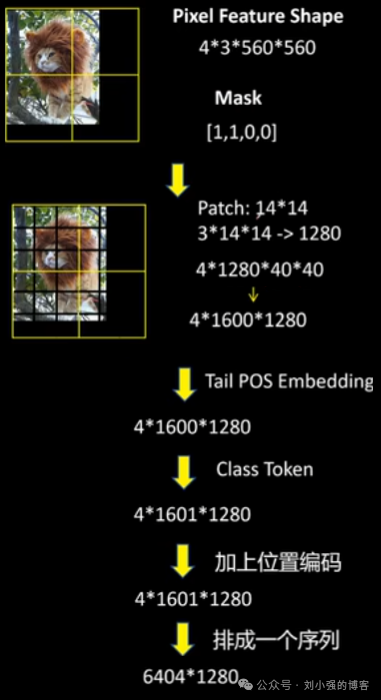
4.视觉编码器输入
最终,所有Tile的Patch序列(共 4×1601个元素)被展平成一个单一的张量,形状为6404×1280,作为视觉编码器的输入。与LLaVA等模型不同,Llama3.2-Vision 在视觉编码器中允许不同Tile间的Patch相互可见,促进了更全面的图像理解。
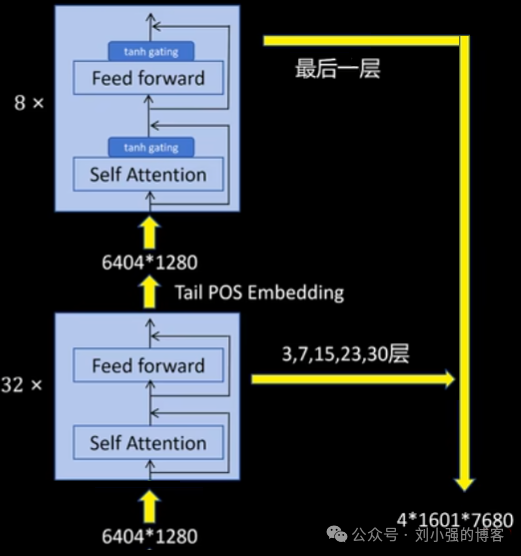
三、视觉编码器的分层与特征融合
\1. 局部特征提取
- 第一阶段: 输入张量首先经过32层视觉编码器模块。这些层主要负责提取局部和低层级的细节特征。
- 第二次Tile位置编码: 在32层输出后,会再次加上一次Tile位置编码。
2.全局特征提取
- 第二阶段 (Global Transformer): 接着,特征进入额外的8层视觉编码器。这8层采用了Tanh门控自注意力 (Tanh Gating Self-Attention)和前馈网络模块。
- 目标: 该阶段被称为 Global Transformer,旨在鼓励模型提取更高层级的全局上下文特征。
\3. 特征融合与输出
模型的关键创新在于局部与全局特征的融合:
-
全局特征: Global Transformer最后一层的输出作为全局特征。
-
局部特征:从前面32层中选取出5个特定层的输出(第 3、7、15、23、30 层)作为局部特征。
-
融合维度:将5个局部特征和1个全局特征进行拼接,特征维度达到6×1280=7680
-
最终输出: 视觉编码器输出的张量形状为4×1601×7680其中4是Tile数量,1601是每个Tile的Patch数量,7680维的特征则包含了最终的高层全局特征和前面提取的局部细节信息。
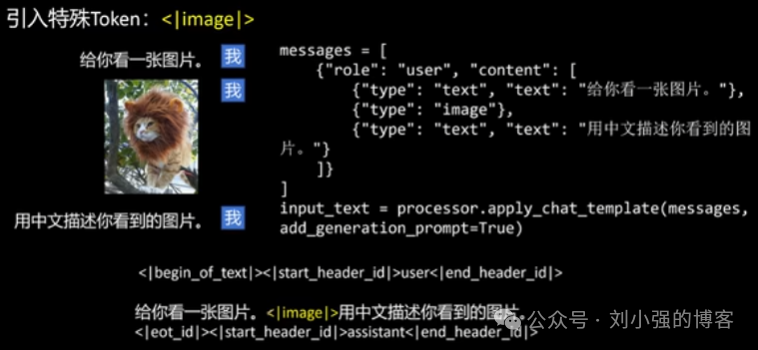
最后,Llama3.2-Vision 在原模型输入的词典中引入了 <|image|> 这个特殊的 Token 来表示输入序列中的图像,将视觉特征与语言序列无缝衔接,送入Llama3.1 LLM进行推理。
四、两阶段训练
在多模态大模型的设计中,如何在引入视觉能力的同时不损害原有语言模型的性能,是一个关键挑战。Llama 3.2 Vision 采用了一种分阶段、轻量对齐的训练机制,在不更新语言模型参数的前提下,实现了视觉语义与语言语义的高质量融合。
1.Adapter预训练—构建视觉到语言的语义映射
第一阶段的核心目标是:将视觉特征映射至语言嵌入空间,使图像信息能够被语言模型自然理解,训练策略: 冻结Llama 3.1全部参数,仅训练Vision Encoder与Cross-Attention Adapter。
训练数据:使用跨领域多任务数据,包括图像描述、区域定位、文档理解、OCR、视觉问答等,覆盖多种视觉子模态,确保模型具备泛化性视觉编码能力。
2.多模态指令微调—注入视觉推理与交互能力
第二阶段的目标是:赋予模型基于视觉的复杂推理与指令跟随能力,通过使用高难度视觉问答、多轮对话、思维链推理、文档解析、代码/UI分析等任务,推动模型从“识别”走向“推理”。
训练方法:继续冻结 LLM,仅微调 Adapter 或 LoRA 层。通过优化视觉-语言交互路径,引导语言模型基于视觉信息生成逻辑连贯的推理链。
通过冻结语言模型、分阶段训练视觉接入层,实现了语言能力的完整保留、视觉语义的精准映射、复杂推理能力的逐步构建,该方案不仅降低了训练成本,也为多模态模型的稳定部署提供了可复用的技术路径。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

















 1921
1921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









