




Pre-Training
1.什么是 Pre-Training?
Pre-Training(预训练)是一种深度学习技术,指的是在大型数据集上对模型进行初步训练,使其学习通用的特征和知识,为下游任务(如分类、生成、翻译等)提供一个良好的初始状态。
预训练的模型往往是一个通用的模型,能够提取各种通用模式和特征,为后续的Fine-Tuning(微调)提供进一步优化。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
2.为什么要进行 Pre-Training?
节约数据和计算资源效率
预训练可以在大规模通用数据上训练出一个通用的基础模型,而在下游任务时只需在较小的数据集上微调,降低了对每个任务的大数据需求。
更快的收敛和泛化能力
预训练使得模型在下游任务中可以更快地收敛因为模型已经学习到了很多通用的表示(如语言结构、视觉特征),减少了随机初始化带来的不稳定性。从而提高了模型在不同领域上的表现。
3.Pre-Training 的流程
1.数据准备: 收集大量无标注的通用数据(如文本、图像、音频)并进行数据清洗和预处理。
2.模型架构设计
3.目标函数设计
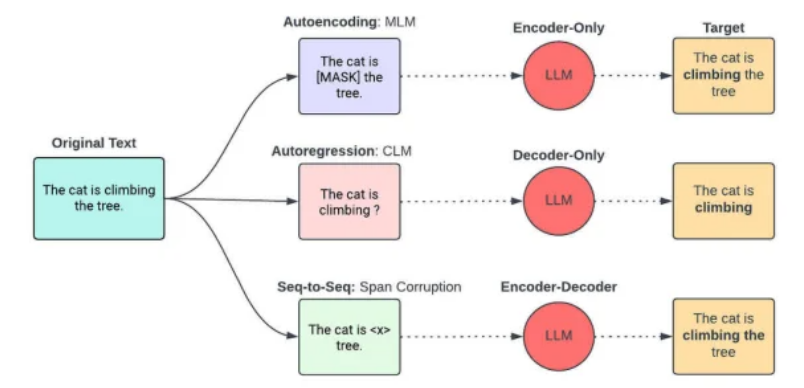
语言建模任务:
自回归语言建模(如 GPT)
自编码语言建模(如 BERT)
图像任务:
对比学习(Contrastive Learning)
多模态任务:
对齐不同模态的表示(CLIP)
4.训练过程
使用高效分布式训练技术在大规模数据集上进行训练。
优化器: 通常采用 Adam 或其变种。
学习率调度: 使用warm-up和 decay 策略。
5.检查点保存与评估
定期保存模型检查点,确保模型训练过程可恢复。
通过评估(如 perplexity、BLEU、精度等)监控模型性能。
6.微调(Fine-Tuning)接口设计
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 592
592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









