




 本文介绍了Kafka的主题、分区和日志概念,以及如何创建和管理分区。Kafka通过分布式存储解决海量数据问题,每个分区包含有序的消息序列,消费者维护自己的消费进度。同时,文章探讨了为何对主题数据进行分区存储的原因以及消费顺序的保证。此外,还展示了实际操作Kafka命令行工具进行主题管理的例子。
本文介绍了Kafka的主题、分区和日志概念,以及如何创建和管理分区。Kafka通过分布式存储解决海量数据问题,每个分区包含有序的消息序列,消费者维护自己的消费进度。同时,文章探讨了为何对主题数据进行分区存储的原因以及消费顺序的保证。此外,还展示了实际操作Kafka命令行工具进行主题管理的例子。
我是🌟廖志伟🌟,一名🌕Java开发工程师🌕、📝Java领域优质创作者📝、🎉优快云博客专家🎉、🌹幕后大佬社区创始人🌹。拥有多年一线研发经验,研究过各种常见框架及中间件的底层源码,对于大型分布式、微服务、三高架构(高性能、高并发、高可用)有过实践架构经验。
🍊博主:java_wxid
🍊博主:Java廖志伟
🍊社区:幕后大佬
文章目录
本文内容:
Kafka主题/分区/日志
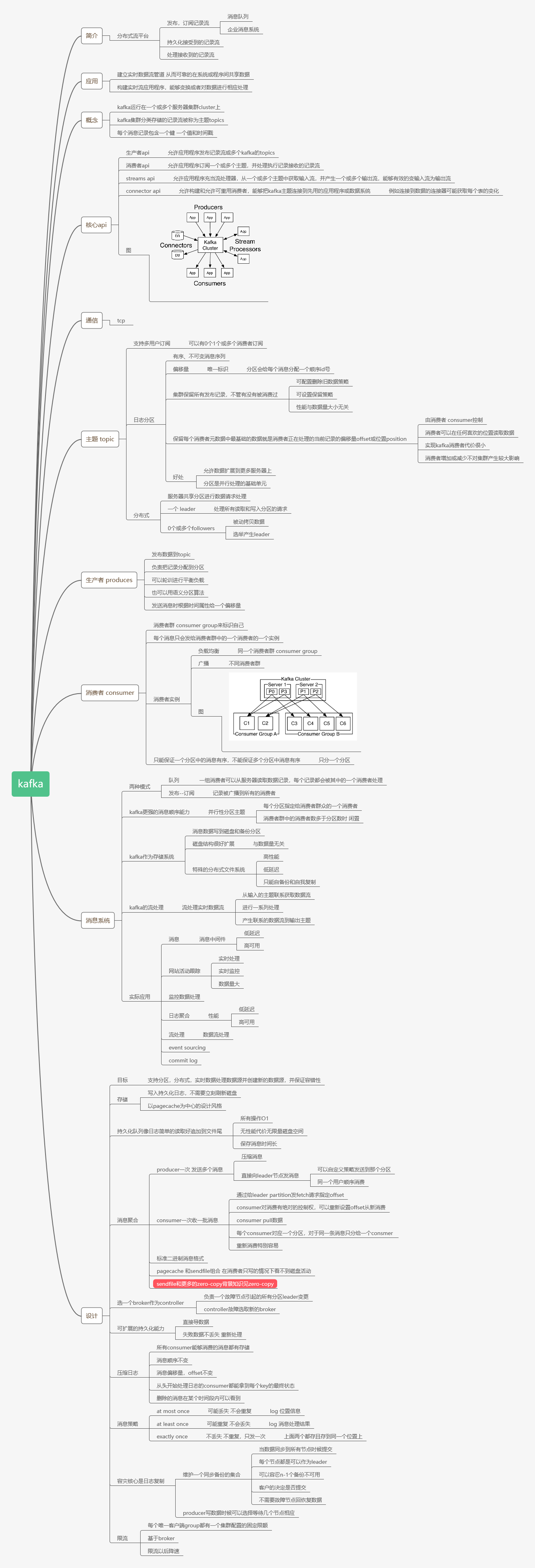
主题/分区/日志的概念
Topic是一个类别的名称,同类消息发送到同一个Topic下面。对于每一个Topic,下面可以有多个分区(Partition)日志文件。Topic是一个逻辑概念,真正落实的数据都在分区上面,一般每个主题至少有一个分区。这样可以通过多个分区,放在在不同的服务器上面去,达到分布式存储的功能,海量数据通过分区存储,切片存储解决单台机器无法存储海量数据的问题。
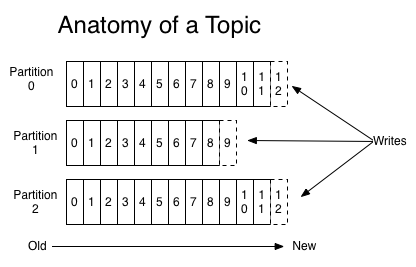
分区是一个有序的消息序列,这些消息按顺序添加到一个叫做commit log的文件中。每个分区中的消息都有一个唯一的编号,称之为offset,用来唯一标示某个分区中的消息。 每个分区,都对应一个commit log文件。一个分区中的消息的offset都是唯一的,但是不同的分区中的消息的offset可能是相同的。
kafka一般不会删除消息,不管这些消息有没有被消费。只会根据配置的日志保留时间(log.retention.hours)确认消息多久被删除,默认保留最近一周的日志消息。kafka的性能与保留的消息数据量大小没有关系,因此保存大量的数据消息日志信息不会有什么影响。
每个消费者是基于自己在commit log中的消费进度(offset)来进行工作的。在kafka中,消费offset由消费者自己来维护;一般情况下我们按照顺序逐条消费commit log中的消息,当然我可以通过指定offset来重复消费某些消息,或者跳过某些消息。这意味kafka中的消费者对集群的影响是非常小的,添加一个或者减少一个消费者,对于集群或者其他消费者来说,都是没有影响的,因为每个消费者维护各自的消费offset。
Topic/Partition/Broker的初体验
创建多个分区的主题
/opt/kafka_2.13-2.7.1/bin/kafka-topics.sh --create --zookeeper 106.14.132.94:2181 --replication-factor 1 --partitions 2 --topic test1
查看下topic的情况
/opt/kafka_2.13-2.7.1/bin/kafka-topics.sh --describe --zookeeper 106.14.132.94:2181 --topic test1

第一行是所有分区的概要信息,之后的每一行表示每一个partition的信息。
- leader节点负责给定partition的所有读写请求。
- replicas表示某个partition在哪几个broker上存在备份。不管这个几点是不是”leader“,甚至这个节点挂了,也会列出。
- isr是replicas的一个子集,它只列出当前还存活着的,并且已同步备份了该partition的节点。
创建的名称为"test"的topic
/opt/kafka_2.13-2.7.1/bin/kafka-topics.sh --describe --zookeeper 106.14.132.94:2181 --topic test

之前设置了topic的partition数量为1,备份因子为1,因此显示就如上所示了。
查询kafka的数据文件存储目录
cat /opt/kafka_2.13-2.7.1/config/server.properties
找到log.dirs配置的路径

进入kafka的数据文件存储目录查看test和test1主题的消息日志文件

消息日志文件主要存放在分区文件夹里的以log结尾的日志文件里

增加topic的分区数量(目前kafka不支持减少分区)
/opt/kafka_2.13-2.7.1/bin/kafka-topics.sh -alter --partitions 3 --zookeeper 106.14.132.94:2181 --topic test
查看分区
/opt/kafka_2.13-2.7.1/bin/kafka-topics.sh --describe --zookeeper 106.14.132.94:2181 --topic test

一个主题,代表逻辑上的一个业务数据集,比如按数据库里不同表的数据操作消息区分放入不同主题,订单相关操作消息放入订单主题,用户相关操作消息放入用户主题,对于大型网站来说,后端数据都是海量的,订单消息很可能是非常巨量的,比如有几百个G甚至达到TB级别,如果把这么多数据都放在一台机器上可定会有容量限制问题,那么就可以在主题内部划分多个分区来分片存储数据,不同的分区可以位于不同的机器上,每台机器上都运行一个Kafka的进程Broker。
为什么要对主题下数据进行分区存储?
- commit log文件会受到所在机器的文件系统大小的限制,分区之后可以将不同的分区放在不同的机器上,相当于对数据做了分布式存储,理论上一个主题可以处理任意数量的数据。
- 为了提高并行度。
消费顺序
一个分区同一个时刻在一个消费组中只能有一个消费者实例在消费,从而保证消费顺序。消费组中的消费者实例的数量不能比一个主题中的分区的数量多,否则,多出来的消费者消费不到消息。Kafka只在分区的范围内保证消息消费的局部顺序性,不能在同一个主题中的多个分区中保证总的消费顺序性。如果有在总体上保证消费顺序的需求,那么我们可以通过将主题的分区数量设置为1,将消费组中的消费者实例数量也设置为1,但是这样会影响性能,所以kafka的顺序消费很少用。
总结
以上就是今天要讲的内容,还希望各位读者大大能够在评论区积极参与讨论,给文章提出一些宝贵的意见或者建议📝,合理的内容,我会采纳更新博文,重新分享给大家。
🙏四连 关注🔎点赞👍收藏⭐️留言📝
感谢大家的支持,用心写博文分享给大家,你的支持(🔎点赞👍收藏⭐️留言📝)是对我创作的最大帮助。
🍊微信公众号:南北踏尘
🍊主页地址:java_wxid
🍊社区地址:幕后大佬
给读者大大的话
我本身是一个很普通的程序员,放在人堆里,除了与生俱来的🌹盛世美颜🌹、所剩不多的发量,就剩下180的大高个了。就是我这样的一个人,默默坚持写博文也有好多年了,有句老话说的好,🌕牛逼之前都是傻逼式的坚持🌕。希望自己可以通过大量的作品,时间的积累,个人魅力、运气和时机,可以打造属于自己的🌟技术影响力🌟。同时也希望自己可以成为一个🎄懂技术🎄,🎄懂业务🎄,🎄懂管理🎄的综合型人才,作为项目架构路线的总设计师,掌控全局的🌕团队大脑🌕,技术团队中的🍊绝对核心🍊是我未来几年不断前进的目标。
提示:以下都是资源分享,求个一键三连。
面试资料
福利大放送,🎉欢迎关注🔎点赞👍收藏⭐️留言📝,拜托了🙏,这对我真的很重要。
点击:面试资料
提取码:2021
200套PPT模板
福利大放送,🎉欢迎关注🔎点赞👍收藏⭐️留言📝,拜托了🙏,这对我真的很重要。
点击:200套PPT模板
提取码:2021
提问的智慧
福利大放送,🎉欢迎关注🔎点赞👍收藏⭐️留言📝,拜托了🙏,这对我真的很重要。
点击:提问的智慧
提取码:2021
Java开发学习路线
| 名称 | 链接 |
|---|---|
| JavaSE | 点击: JavaSE |
| MySQL专栏 | 点击: MySQL专栏 |
| JDBC专栏 | 点击: JDBC专栏 |
| MyBatis专栏 | 点击: MyBatis专栏 |
| Web专栏 | 点击: Web专栏 |
| Spring专栏 | 点击: Spring专栏 |
| SpringMVC专栏 | 点击: SpringMVC专栏 |
| SpringBoot专栏 | 点击: SpringBoot专栏 |
| SpringCould专栏 | 点击: SpringCould专栏 |
| Redis专栏 | 点击: Redis专栏 |
| Linux专栏 | 点击: Linux专栏 |
| Maven3专栏 | 点击: Maven3专栏 |
| Spring Security5专栏 | 点击: Spring Security5专栏 |
| 更多专栏 | 更多专栏,请到 java_wxid主页 查看 |
P5学习路线图
 P6学习路线图
P6学习路线图
 P7学习路线图
P7学习路线图
 P8学习路线图
P8学习路线图

以上四张图详细介绍了作为Java开发工作者所需要具备的知识技能,同学们学废了嘛,有想法系统学习的同学可以私聊我,🎉欢迎关注🔎点赞👍收藏⭐️留言📝。
🍊博主:java_wxid
🍊博主:Java廖志伟
🍊社区:幕后大佬


















 1708
1708






 到【灌水乐园】发言
到【灌水乐园】发言









