




 本文分享了SpringBoot中JPA Query的实用技巧,包括参数使用、解决In查询排序问题及日期处理方法,帮助开发者避免常见陷阱,提升查询效率。
本文分享了SpringBoot中JPA Query的实用技巧,包括参数使用、解决In查询排序问题及日期处理方法,帮助开发者避免常见陷阱,提升查询效率。
springboot 关于用query查询
很多初学springboot 的小伙伴,不太熟悉sringboot jpa query的一系列操作,今天就来讲一下
1.参数的使用
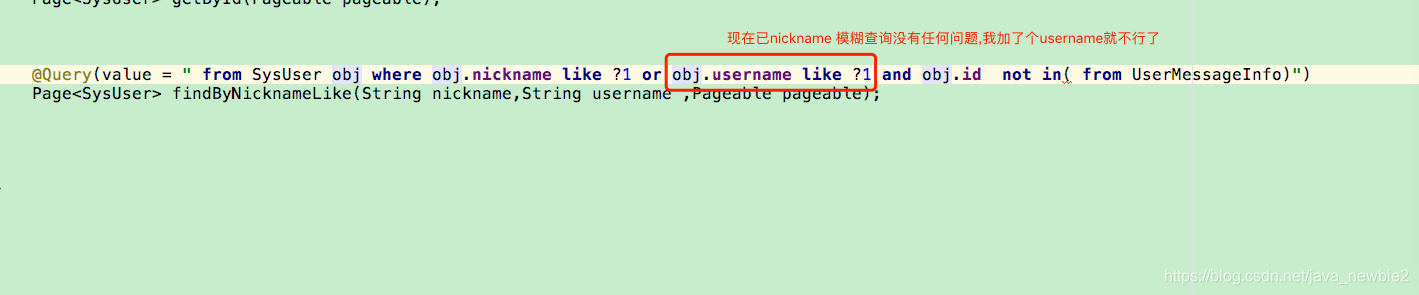
这个地方是来自 一个小伙伴写的错误的示例。这个地方参数是作为查询条件的,那么?1代表的就是第一个参数,如果要用到第二个参数 username, 我们要用?2来代替这个这个参数作为查询的条件。
2、之前项目上遇到遇到一个坑爹的东西,我也一并写出来。关于jpa 的in查询 例如:
List findbyIdIn( ids[] names );
查出来是没问题的,但是,在In里面直接排序了。而我数据库另一张表例如参加活动记录表,是从客户端传过来的数据 记录的User的id 是 1,2,3,4,5 另一个字段 money则记录的是 获得的钱。记录成300,500,600,700,900这样子
这样为了保证数据的一致性,就必须让In 不准排序。
我是这样处理的:@Query(value = "select * from user where id in ?1 order by INSTR(',{?1},',CONCAT(id))",nativeQuery = true)
3、日期的处理。比如我要查询最近七天的记录,然而,数据库里面的字段类型是varchar.传入的字是类似于20181115这样的值,我们怎么用jpa去查询呢
@Query(value = "SELECT * FROM roomlog where DATE_SUB(CURDATE(), INTERVAL 7 DAY) <= date(str_to_date(_tcreate,'%Y%m%d %H%i%s'))",nativeQuery = true)

用str_to_date() 这个方法,去转换. 前面是这个值的字段 后面是格式。

















 8261
8261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









