



 本文分享了一张Redis问题画像图,帮助快速定位问题及其对应的技术点。介绍了中科院计算所副研究员蒋德钧的专栏《Redis核心技术与实战》,内容涵盖Redis原理与实战技巧,包括分布式锁、缓存问题解决、持久化及集群方案选择等。
本文分享了一张Redis问题画像图,帮助快速定位问题及其对应的技术点。介绍了中科院计算所副研究员蒋德钧的专栏《Redis核心技术与实战》,内容涵盖Redis原理与实战技巧,包括分布式锁、缓存问题解决、持久化及集群方案选择等。
如果你是一位后端工程师,面试时八成会被问到 Redis,特别是那些大型互联网公司,不仅要求面试者能简单使用 Redis,还要深入理解其底层实现原理,具备解决常见问题的能力。可以说,熟练使用 Redis 是后端工程师的必备技能。
但我发现,在工作或面试时,大家还是会有这样那样的疑问,比如:如何用 Redis 实现分布式锁?Redis 怎样处理过期键?缓存雪崩、穿透、热点问题怎么解决?持久化、集群方案怎么选择?如何优雅地给 Redis 做键值分析?等等。
这里,分享给你一张 Redis 问题画像图,帮你快速定位问题对应的 Redis 主线模块,及相关技术点。举个例子,如果 Redis 响应变慢,对照下图你就会发现,这个问题与 Redis 性能主线相关,而性能主线又和数据结构、异步机制、RDB、AOF 重写相关,找到了影响因素,解决起来就容易多了。

在学习和使用过程中,你还可以结合自己的实践经验不断完善它。这样一来,积累越多,画像就越丰富。
这张图出自蒋德钧,他是中科院计算所副研究员,长期致力于 Redis 研究,与阿里、蚂蚁金服、百度、华为、中兴等公司开展了多种项目合作,具有丰富的 Redis 实战经验,申请了 NVM(非易失内存)相关专利二十多项。
去年,订阅了他的专栏《Redis 核心技术与实战》,追着更新看了一遍,今年抽空又二刷了,不仅原理讲得透彻,实战性也强。很多问题之前没有深入思考过,跟着专栏敲代码测试和分析了源码细节,让我对 Redis 有了更深入的理解。发文前看了下,订阅已经20,000+ 了。
在专栏中,他总结了一条系统高效的 Redis 学习路径,帮你透彻理解 Redis 核心原理,并通过上手实战,掌握高并发场景下的缓存解决方案。同时,还有不少 Redis 高频面试题讲解,都是工作、面试中用得上的、实打实的硬货。
新人首单 ¥69.9 ,仅限「前 50 人」
原价 ¥199,相当于 3 折
其实,大多数人都是带着具体问题学 Redis 的,我自己也不例外。但后来我才发现,这些问题虽然重要,但如果只关注零散技术点,没有建立起完整的知识框架,你的使用能力很难得到质的提升。
所以,蒋老师总结了“两大维度,三大主线”:前者指系统维度和应用维度,后者就是高性能、高可靠和高可扩展。

从系统维度说,要了解 Redis 各项关键技术的设计原理,并掌握一些系统设计规范,比如 run-to-complete 模型、epoll 网络模型,以便应用到后续的系统开发中。但 Redis 的知识点很零碎,所以,可以按照“三大主线”为它们分类:
高性能主线,包括线程模型、数据结构、持久化、网络框架;
高可靠主线,包括主从复制、哨兵机制;
高可扩展主线,包括数据分片、负载均衡。
在应用维度上,可以按 “应用场景驱动”和“典型案例驱动”两种方式学习,一个是“面”的梳理,一个是“点”的掌握。
我们都知道,缓存和集群是 Redis 最广泛的两大应用场景。在这些场景中,本身就有一条显式技术链。比如,提到缓存就会想到缓存机制、缓存替换、缓存异常等一连串问题。
但并不是所有都适合这种方式,比如 Redis 丰富的数据模型,以及一些隐藏得比较深、在特定业务场景下才会出现的问题,就可以采用“典型案例驱动”的方式,深入拆解一些对 Redis “三高”特性影响较大的案例,例如,各个大厂在万亿级访问量、数据量的情况下,对 Redis 的深度优化实践,等等。
这样,才能透彻理解 Redis,建立起结构化的知识体系,快速找到引发问题的关键因素,甚至整理成 Checklist,作为遇到问题时信手拈来的“锦囊妙计”。这也是蒋老师在开篇词里提到的,设计这个专栏的出发点。类似的干货有很多,具体可以看看目录:

专栏更新完,蒋老师还写了好几篇加餐,不仅分享了一些好用的运维工具,还讲解了定制化客户端的开发方法,分享了一些经典学习资料。
而且,连专栏里的留言质量都很高,不仅蒋老师会解答大家的问题,读者自己也会相互切磋,光看评论区都能学到不少,口碑自然不错,截了一些供你参考:
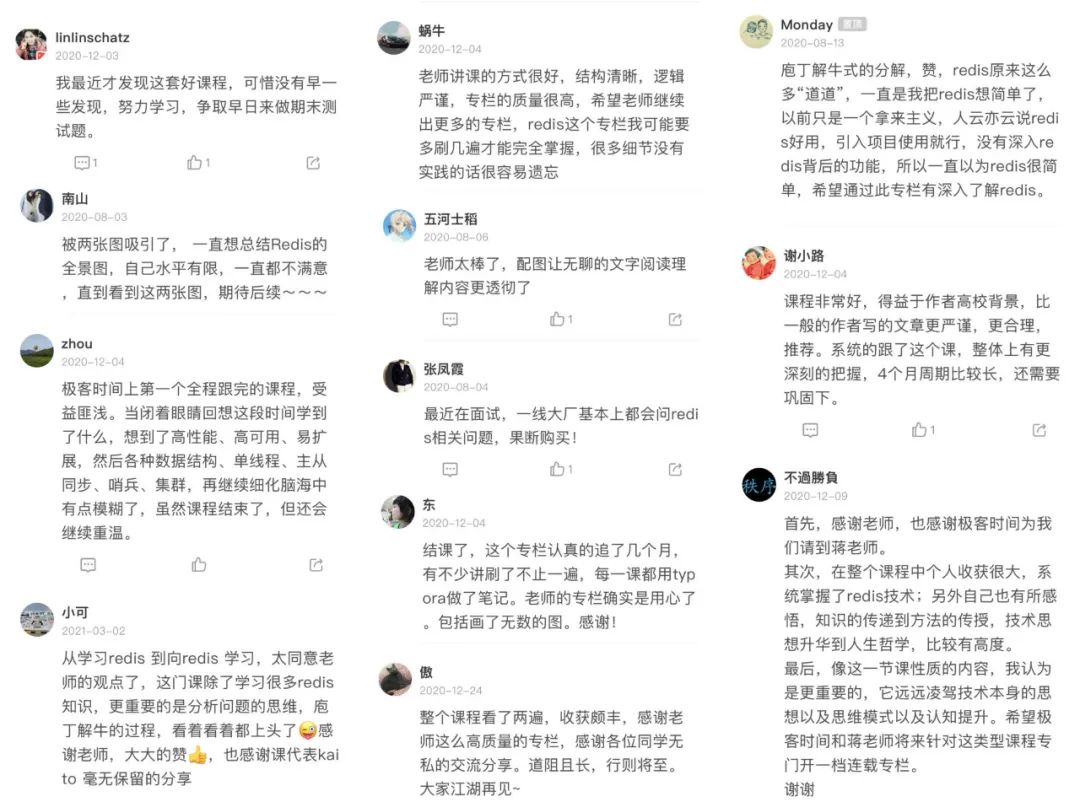
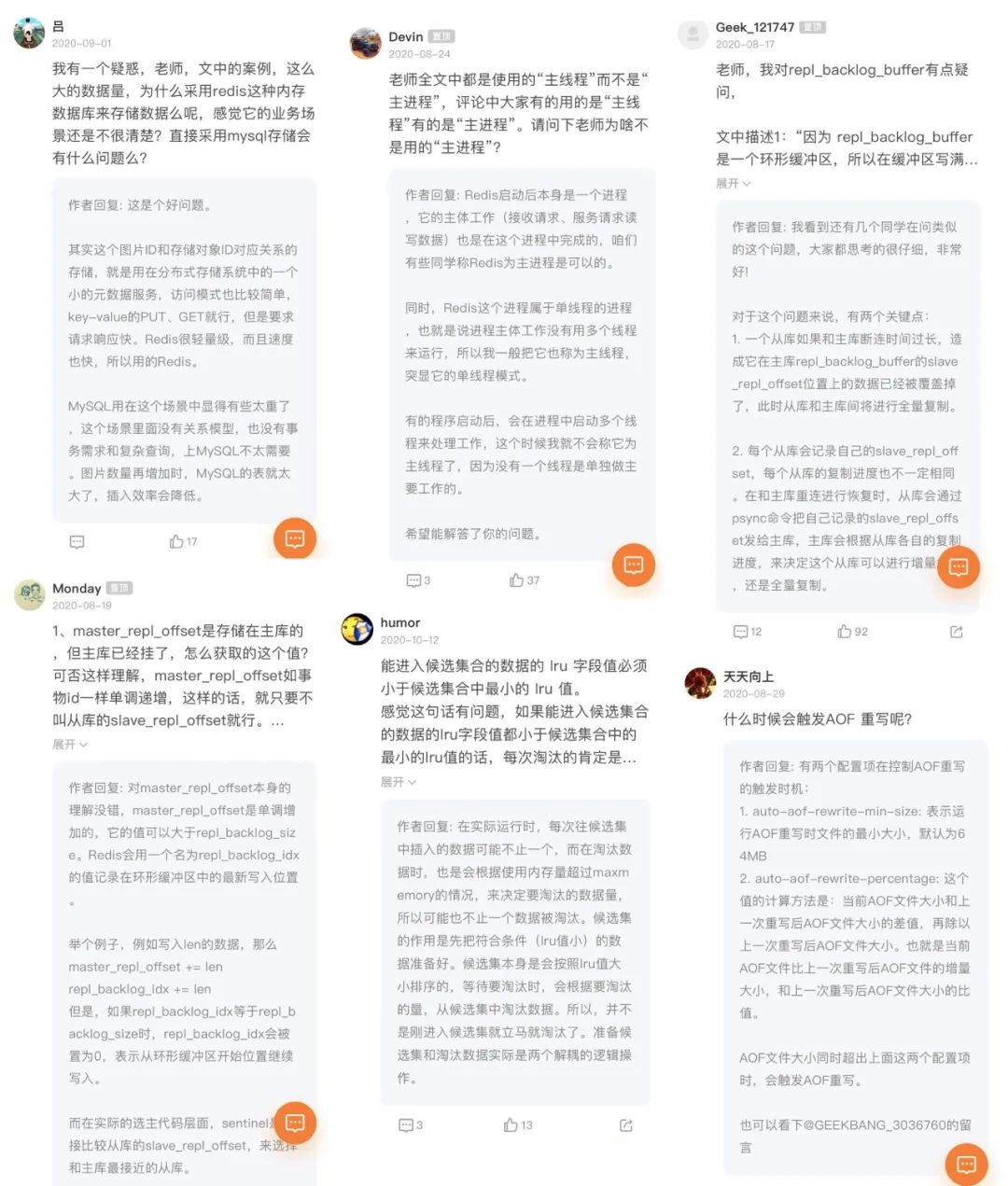
在结束语中,老师写了这么一段话,我特别认同:
我们常说“不积跬步,无以至千里”,这句话中的“跬步”,我把它定义为:做成一件事。我们总会做很多事,但大多数时候,能真正得到提升的是“把事做成”。
成事的目标不分大小。它可以很小,比如学完两节课;也可以很大,比如用 3 个月时间把 Redis 源码读完。最重要的是,一旦定好目标,就要竭尽全力把事做成。随着做成的事越来越多,也就能真正体会到“会当凌绝顶,一览众山小”。
老规矩,申请了粉丝专属优惠:
新人首单 ¥69.9 ,仅限「前 50 人」
原价 ¥199,相当于 3 折
点击「阅读原文」
享受特惠,新人首单 ¥69.9
3 折入手,仅限「前 50 人」!

















 5244
5244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









