







 本文介绍了OpenLineage项目,一个旨在提供数据血缘追踪的开源标准,以解决大数据环境下数据来源复杂、数据依赖关系难以追溯的问题。OpenLineage通过统一的数据模型,连接各种数据处理工具,如Airflow、Spark等,提供数据血缘的可见性和一致性。此外,还提到了Marquez作为OpenLineage的推荐实现,并讨论了其选择不实现列级别血缘的原因。尽管OpenLineage有成为行业标准的潜力,但目前其他类似项目如Databub、Amundsen并未明显受其影响。
本文介绍了OpenLineage项目,一个旨在提供数据血缘追踪的开源标准,以解决大数据环境下数据来源复杂、数据依赖关系难以追溯的问题。OpenLineage通过统一的数据模型,连接各种数据处理工具,如Airflow、Spark等,提供数据血缘的可见性和一致性。此外,还提到了Marquez作为OpenLineage的推荐实现,并讨论了其选择不实现列级别血缘的原因。尽管OpenLineage有成为行业标准的潜力,但目前其他类似项目如Databub、Amundsen并未明显受其影响。
背景
“大数据”这个概念逐渐深入人心,很多公司都面临的着:
-
工具和平台的数量爆炸式增长
-
越来越多的人开始使用数据、应用数据
-
对于一个大企业而言,每个子公司/部门可能都有着属于自己的数据团队
总的来说,就是“大数据”中的“大”不仅仅是数据量大,也指的是数据种类多、数据来源复杂,不同的数据被各式各样的人使用。如何发现数据,确定数据的来龙去脉就成了一个急迫的问题。
OpenLineage 应运而生。
介绍 OpenLineage
OpenLineage 可以翻译成开源血缘。按照这个项目的发起者 Julien Le Dem 的说法,“数据血缘需要遵循开源社区贡献者商定的标准,以保证其各自解决方案生成的元数据的兼容性和一致性。”
Data lineage needs to follow a standard agreed upon by contributors to the open source community to guarantee the compatibility and consistency of the metadata produced by their respective solutions.
它回答的问题是:“谁生产数据?它是如何转变的?谁在使用它?数据血缘是 DataOps 的支柱,它提供了对组织内数据旅程中系统和数据集交互的可见性。”
Data lineage is the backbone of DataOps, providing visibility into the interaction of systems and datasets across the journey of data within an organization.
也给出了一个可用的数据血缘应该满足什么样的要求。
-
它不仅需要捕获正在生成的数据集之间的依赖关系,还需要捕获生成和转换它们的业务逻辑
-
这些数据集和程序中的每一个都需要有一种统一命名的形式,以便可以轻松识别并跨不同域统一访问
-
这些数据集和程序中的所有变化都需要以细粒度和自动方式进行跟踪和版本控制,以更好地了解整个生态系统随时间的演变
-
考虑到它需要支持的各种用例,描述这些数据集和程序的元数据需要灵活且可扩展
现在的 OpenLineage 的参与者包括了下面的一些开源项目:
-
Airflow
-
Amundsen
-
Datahub
-
dbt
-
Egeria
-
Great Expectations
-
Iceberg
-
Marquez
-
Pandas
-
Parquet
-
Prefect
-
Spark
-
Superset
OpenLineage 概览
正如上面列举的参与 OpenLineage 的项目,它们都有着独特的设计理念和实现思路,让数据发现平台去和这些计算引擎一对一对接的话,就会变成复杂的网状的的链路。
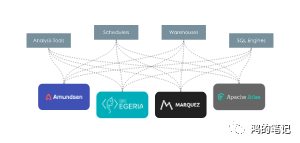
而 OpenLineage 起到了中间件的作用,负责沟通上下游。
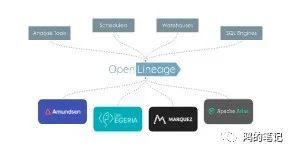
作为一个中间件,就是抛去所有花里胡哨的特性,直击本质。也就是上面提到的三个问题:
-
谁生产数据?
-
它是如何转变的?
-
谁在使用它?
OpenLineage 的回答就是它的核心数据模型
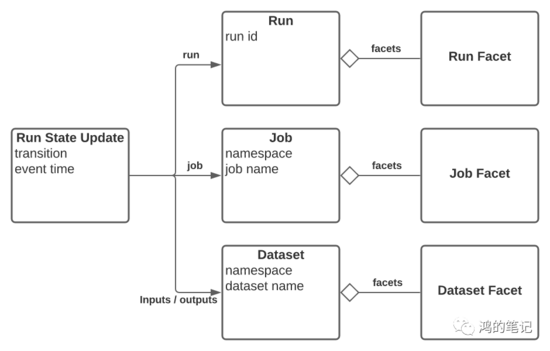
Run 和 Job 回答的是“它是如何转变的?”,Inputs/Outputs 回答的是“谁生产数据”/“谁在使用它”。在 OpenLineage 的核心数据模型设计中,它没有选择实现更细节,也更麻烦的列级别血缘,而是只做到了表级别的血缘。在我看来,这个选择是非常棒的,因为要选择实现列级别的血缘,每一种特定类型的 SQL 势必要绑定对应的 SQL 解释器,这就让 OpenLineage 变得复杂,就谈不上通用的标准了。
OpenLineage 的表达方式选择了 Json 格式,具体细节可以参考:https://github.com/OpenLineage/OpenLineage/blob/main/spec/OpenLineage.md
{
"eventType": "START",
"eventTime": "2020-12-09T23:37:31.081Z",
"run": {
"runId": "3b452093-782c-4ef2-9c0c-aafe2aa6f34d",
},
"job": {
"namespace": "my-scheduler-namespace",
"name": "myjob.mytask",
},
"inputs": [
{
"namespace": "my-datasource-namespace",
"name": "instance.schema.table",
}
],
"outputs": [
{
"namespace": "my-datasource-namespace",
"name": "instance.schema.output_table",
}
],
"producer": "https://github.com/OpenLineage/OpenLineage/blob/v1-0-0/client",
"schemaURL": "https://openlineage.io/spec/1-0-0/OpenLineage.json#/definitions/RunEvent"
}
介绍 Marquez
空有标准,没有实现是没有意义的,OpenLineage 官方推荐的实现是 Marquez。它和 Databub、Amundsen 类似,长得像下面这样。
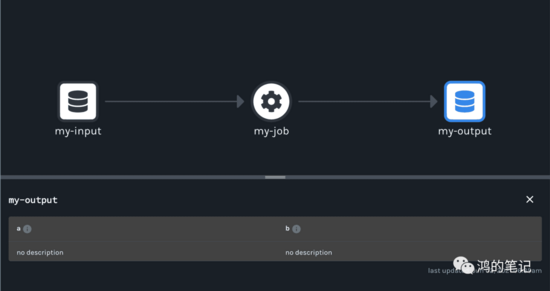
总结
OpenLineage 是一个有野心的项目,它想和 HDFS 变成了分布式文件系统通用标准一样,变成数据血缘的通用标准。但是 OpenLineage 从 2020 年发布到现在,Databub、Amundsen 并没有受到 OpenLineage 的影响,依旧在按照项目自身的发展路径前进。
从个人实践来看,我很喜欢这个项目。国内很多谈数据治理的文章,都是在讲规章制度和规范这些,至于具体的落实,基本上很少会涉及,特别是像把数据血缘做成标准,可以让各种各样的数据计算引擎以同一套标准接入,就几乎上没有了。毕竟光讲理念、规章和制度,不去谈实现,略有“好高骛远”的嫌疑。
参考链接
-
https://datakin.com/introducing-openlineage/
-
https://github.com/OpenLineage/OpenLineage
-
https://openlineage.io/

















 1318
1318

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









