




 本文介绍了如何将RepViT,一种轻量级的视觉变换器,应用于RT-DETR的目标检测任务中,以提高模型性能。通过结构重组、扩展比率调整等优化,实现参数量减少且精度提升。详细教程涵盖了RepViT的基本原理、核心代码以及在RT-DETR中的具体修改步骤,包括对网络结构、计算量打印问题的解决等关键修改。
本文介绍了如何将RepViT,一种轻量级的视觉变换器,应用于RT-DETR的目标检测任务中,以提高模型性能。通过结构重组、扩展比率调整等优化,实现参数量减少且精度提升。详细教程涵盖了RepViT的基本原理、核心代码以及在RT-DETR中的具体修改步骤,包括对网络结构、计算量打印问题的解决等关键修改。
👑欢迎大家订阅本专栏,一起学习RT-DETR👑
一、本文介绍
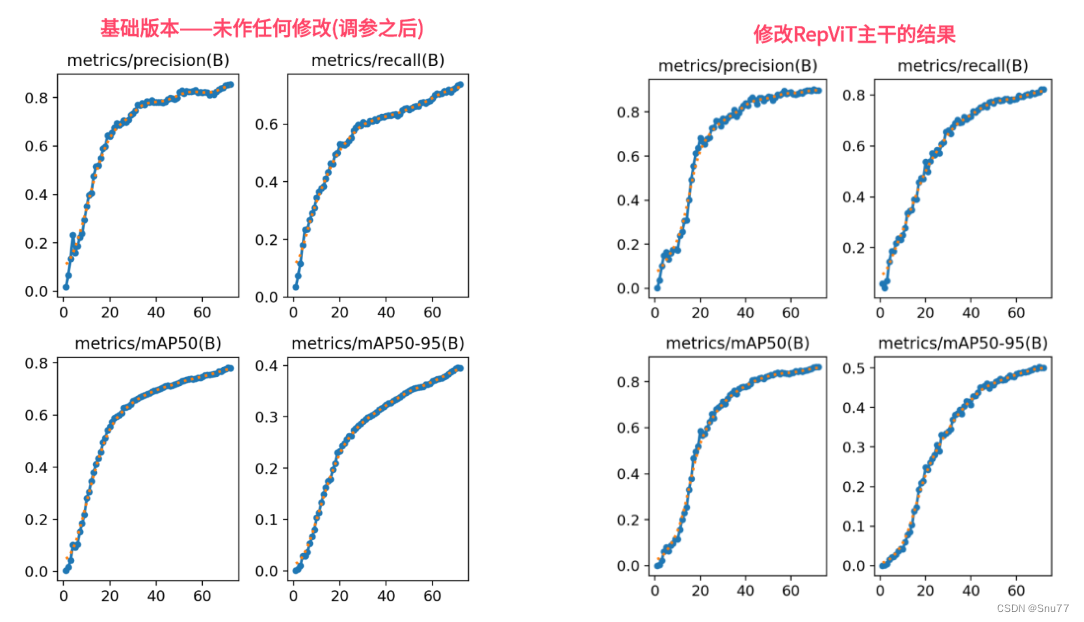
本位给大家带来的改进机制是RepViT。它是一种最新发布的网络结构,把轻量级的视觉变换器(就是ViT)的设计理念融入到了我们常用的轻量级卷积神经网络(CNN)里。我尝试把它用在RT-DETR的主干网络上,效果还不错,mAP有一定的提高。我用的是这个网络中最轻量级的版本。 我将其用于在我的数据上实验(包含多个类别其中包含大中小多个目标类别),无论哪种目标,精度均有所提升。接下来,我会展示一下原始版本和我改进后版本在训练上的对比图。之后会在文章中介绍该网络结构,然后教大家如何修改该网络结构,同时修改该主干参数量下降四分之一相对于ResNet18。
目录
二、RepViT基本原理

官方论文地址: 官方论文地址点击即可跳转
官方代码地址: 官方代码地址点击即可跳转

RepViT: Revisiting Mobile CNN F

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 620
620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











