



 本文详细介绍Scrapy爬虫框架的安装、配置及核心组件使用方法,包括项目创建、目录结构解析、数据提取与处理流程,以及如何通过pipelines进行数据持久化。
本文详细介绍Scrapy爬虫框架的安装、配置及核心组件使用方法,包括项目创建、目录结构解析、数据提取与处理流程,以及如何通过pipelines进行数据持久化。
SCRAPY使用
第一篇笔记是一份scrapy中的格式的简单整理。大部分都是伪代码,用来快速回忆每个部分的作用。具体代码会在第二篇里编写。自学可能有些错误,欢迎补充。
内容列表
scrapy安装
pip install scrapy
cmd命令
项目创建
scrapy startproject hellospider
项目启动
scrapy crawl hellospider -o items.json
-o items.json为输出items到一个json文件。可删除。
目录结构
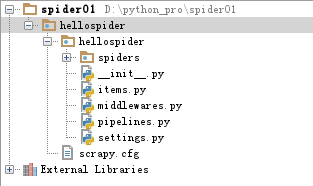
hellospider/items.py:需要提取的数据结构定义文件。
hellospider/middlewares.py: 是和Scrapy的请求/响应处理相关联的框架。
hellospider/pipelines.py: 用来对items里面提取的数据做进一步处理,如保存等。
hellospider/settings.py: 项目的配置文件。
hellospider/spiders/: 放置spider代码的目录。
代码编辑
1. item.py中定义爬取数据
item可以看成是个字典,我们在这里声明键(KEY),之后在spider里面用item[键]传入
class DetailItem(scrapy.Item):
title = scrapy.Field() #item里一个键为title的栏位
......
2. spiders目录下添加myspider.py文件
在MySpider这个物件中,有以下常用变量:
- name: scrapy唯一定位实例的属性,必须唯一
- allowed_domains:允许爬取的域名列表,不设置表示允许爬取所有
- start_urls:起始爬取列表
- header: HTTP Request的Header信息。如果直接和后端通信的话,大部分情况要构建’User-Agent’ , ‘Referer’ , ‘token’ 来骗过后端以为爬虫是前端。常用于爬angluar之类的API。
我们常常重写或编写这些方法:
start_requests:它就是从start_urls中读取链接,然后使用make_requests_from_url生成Request。我们可以重写它,加入header之类的东西。parse:主回调函数,处理response并返回处理后的数据和需要跟进的url其他parse:这是我们自己写的其他的parse,与parse()作用一样。比如我们想从宫吧爬出每一个贴子里的图文,那么我们用parse()去宫吧主页面拉出所有帖子的超链接,之后用scrapy.Request()的方法跳进每一个帖子里,再parsepost()处理帖子所有的图片。
这里我们常用的工具:
- XPATH查找路径
- RE正则表达
import scrapy
from hellospider.items import DetailItem
class MySpider(scrapy.Spider):
name = "spider名"
allowed_domains = ["在这个域名下爬"]
start_urls = ["初始爬的网页"]
# 循环读取首页列表,分别跳转详情页
def parse(self, response):
for line in response.xpath('...'):
hh = line.xpath('a/@href').extract()
yield scrapy.Request(url=hh , callback=self.parsePost, dont_filter=False)
# 进入详情页,爬资料
def parsePost(self, response):
item = DetailItem()
item['title'] = line.xpath('...').extract()
yield item
3. pipelines.py的编写
当Item在Spider中被收集之后,它将会被传递到Item Pipeline。我们可以选择是否对item进行处理。常用的处理包括:
- 保存item为txt之类的文件
- 根据item的参数(url),去下载文件
- 把item存进SQL里
- 查重,清洗,筛选数据等
scrapy官方有 存为json,保存图片,保存文件 等pipline可直接使用。要是觉得他们不好用,我们可以继承这些方法,并改写他们。
例如我在这里重写爬图pipline,增加分类文件夹的功能:
class SharkImagePipeline(ImagesPipeline):
# 下载图片时遍历此item的zimg
def get_media_requests(self, item, info):
for image_url in item['zimg']:
# 这里把item传过去,因为file_path需要用item里面文件名
yield Request(image_url, meta={'item': item})
# 修改文件的命名和路径
def file_path(self, request, response=None, info=None):
item = request.meta['item']
folder_name = item['fisherno'][0]
image_guid = request.url.split('/')[-1]
file_name = './{}/{}'.format(folder_name, image_guid)
# print("图片叫啥:", file_name)
return file_name
4. setting.py里修改参数
这里可以声明一些参数:
- 要使用的pipline
- 根据item里的哪一项爬文件
- 爬文件保存的位置
- 是否使用中间件
ITEM_PIPELINES = {
#主要的pipline,后面数字是优先级
'hellospider.pipelines.hellospiderPipeline': 300,
#爬文件专用的pipline
'scrapy.pipelines.files.FilesPipeline': 1,}
FILES_STORE = 'Download' #文件保存位置
IMAGES_URLS_FIELD = 'zimg' # pipline根据item[zimg]抓文件
(END) © Kiyoshimo

















 2234
2234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









