




 本文深入解析HBase的数据存储逻辑,包括rowkey的作用、Region和Store的设计;阐述物理存储结构,如StoreFile、MemStore和WAL的角色;讲解写流程、读流程、StoreFileCompaction和RegionSplit策略,以及RowKey设计的重要性。还讨论了预分区、数据倾斜及其解决方案。
本文深入解析HBase的数据存储逻辑,包括rowkey的作用、Region和Store的设计;阐述物理存储结构,如StoreFile、MemStore和WAL的角色;讲解写流程、读流程、StoreFileCompaction和RegionSplit策略,以及RowKey设计的重要性。还讨论了预分区、数据倾斜及其解决方案。
1 HBase逻辑结构
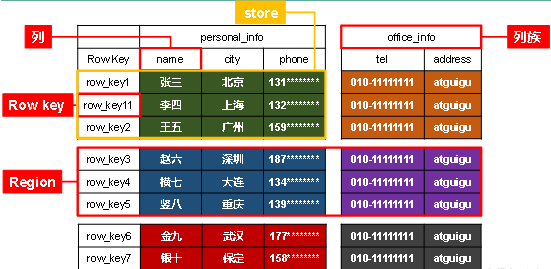
1)数据存储在一张表中,有行有列,rowkey作用类似主键,按字典序排序
2)rowkey确定一行,列族+列确定一列
3)存储在HDFS上的形式:先按rowkey范围切分为Region,一个Region对应HDFS的一个文件夹,再按列族切分为两个文件夹,一个文件夹对应一个store,再往下数据就以文件的形式存储在store文件夹里面
2 HBase物理存储结构
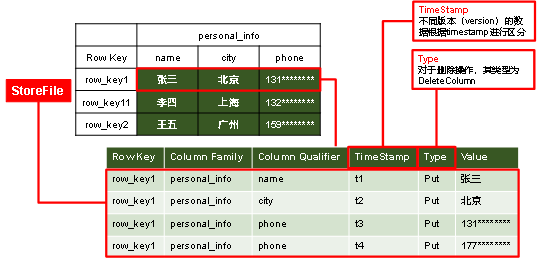
1)StoreFile中除了Value字段,剩余的所有限定能唯一地表示一行数据,因此多个限定联合为key与Value形成k-v结构
2)增改一条数据通过时间戳区分不同版本,而删除操作在HDFS上表现为插入一条Type为DeleteColumn地数据
3 数据模型
| 模型 | 说明 |
|---|---|
| Name Space | 命名空间,其下有多个表,HBase自带hbase和default,前者存放HBase内置的表,后者是用户默认使用的 |
| Table | 表,定义时只需声明列族,写入数据时字段可以动态、按需指定,因此可以实现字段变更 |
| Row | HBase表中每行数据都由一个RowKey和多个Column组成,数据按照RowKey字典序存储,查询只能根据RowKey检索。 |
| Column | 列由Column Family(列族)和Column Qualifier(列限定符)进行限定 |
| Time Stamp | 用于标识数据的不同版本(version),每条数据写入时,系统会自动为其加上该字段,其值为写入HBase的时间 |
| Cell | 由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元。 可以理解为物理模型中的StoreFile中的一行(不包含Type),而不是逻辑模型中的Store中的一格. |
4 基本架构
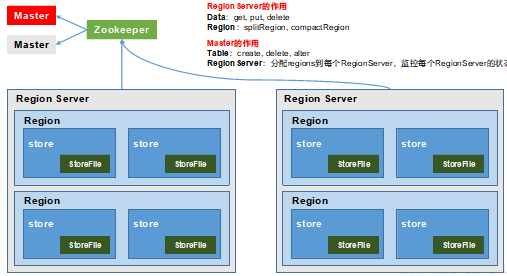
| 角色 | 作用 |
|---|---|
| Region Server | Region的管理者,功能仅限于Region,实现表数据的增删改查DML,而无法实现DDL |
| Master | Region Server的管理者,操作表DDL,分配regions到每个RegionServer,监控每个RegionServer的状态,负载均衡和故障转移。 |
| Zookeeper | 实现master的高可用、RegionServer的监控、元数据的入口以及集群配置的维护等工作。注意:RS的分布式依赖ZK,而master是单独的进程,ZK只负责master的高可用,master通过zk管理RS的信息以监控 |
| HDFS | 为Hbase提供最终的底层数据存储服务,同时为HBase提供高容错的支持,这里的高容错是HDFS自身的. |
5 RegionServer架构
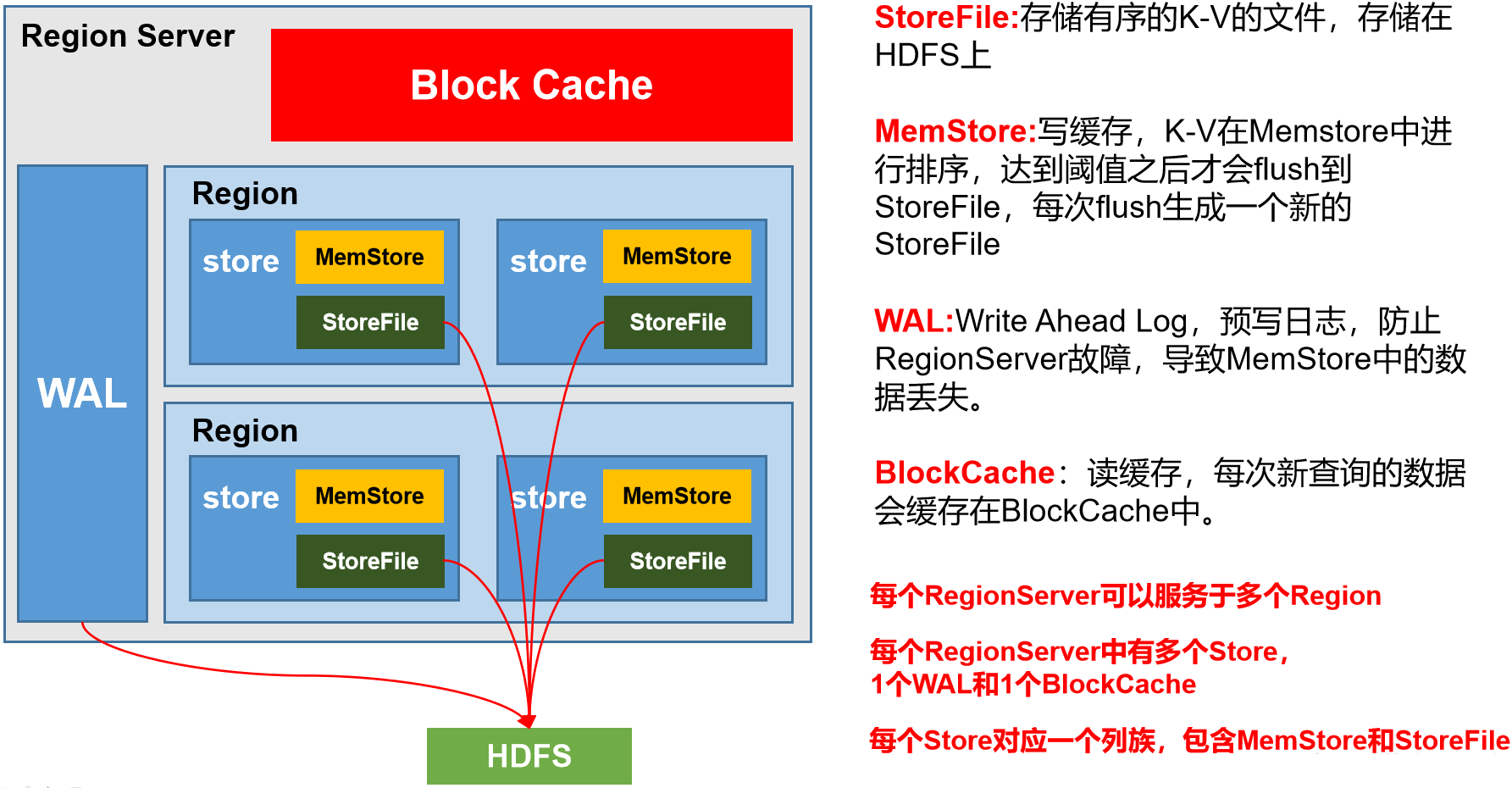
| 组件 | 说明 |
|---|---|
| StoreFile | 物理文件,以Hfile的形式存储在HDFS上。每个Store会有一个或多个StoreFile(HFile),数据在每个StoreFile中都是有序的。文件内有序,但文件间无序 |
| MemStore | 写缓存,由于HFile中的数据要求有序,所以数据先存储在MemStore中,排好序后,等到达刷写时机才会刷写到HFile,每次刷写都会形成一个新的HFile。一个store只有一个写缓存,刷写出的HFile对应存放在HDFS上的同一个文件夹下,避免混乱 |
| WAL | 数据经MemStore排序后刷写到HFile,内存中很可能数据会丢失,因此,数据会先写在Write-Ahead logfile的文件中(记录写命令),然后再写入MemStore中。若系统故障,数据可通过这个日志文件重建。 |
| BlockCache | 读缓存,每次查询出的数据会缓存在BlockCache中,方便下次查询。 |
注意:一个RegionServer只有一个WAL,一个Block Cache,多个MemStore
6 写流程
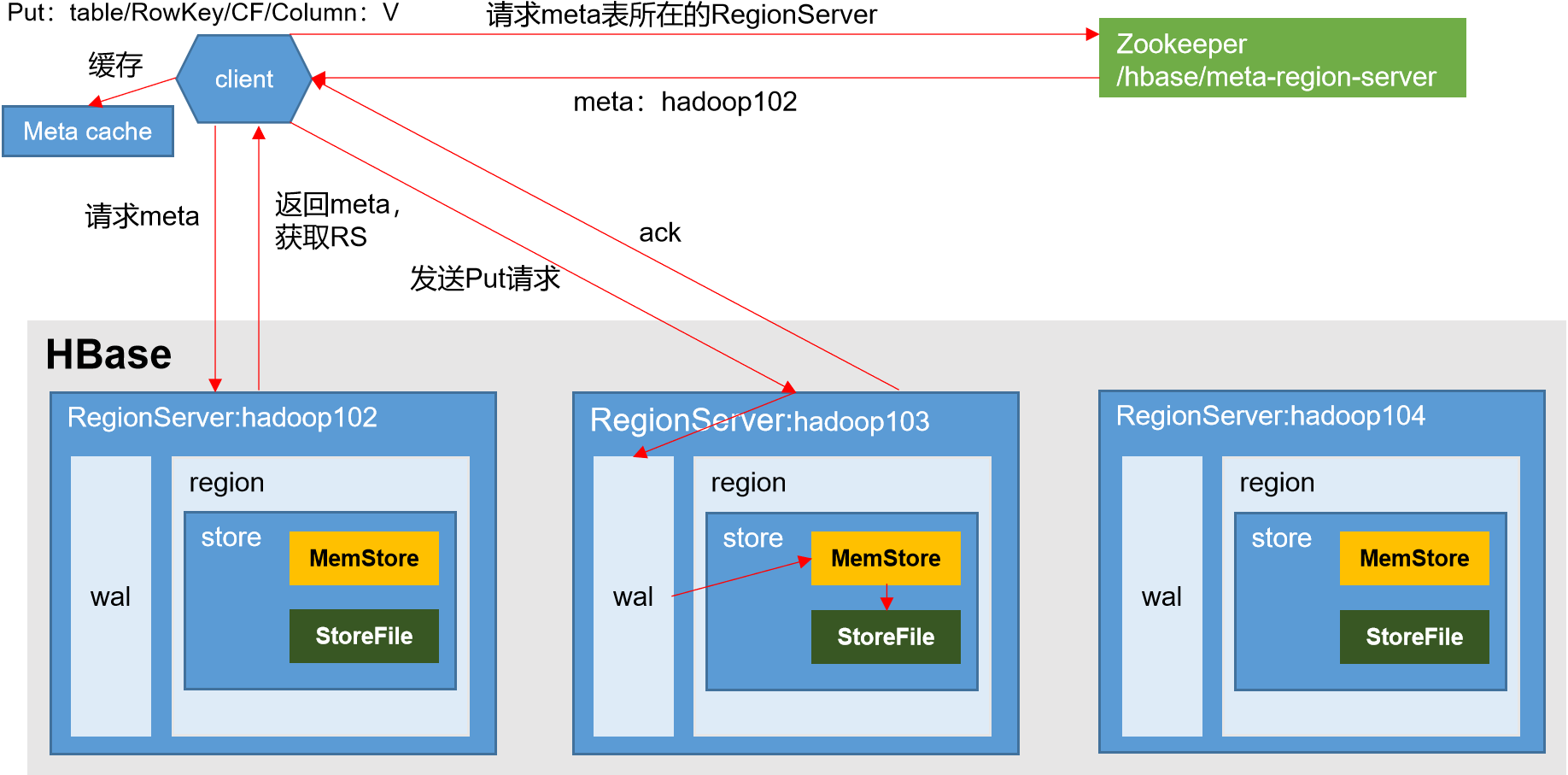
1)Client先访问zookeeper,获取hbase:meta表位于哪个Region Server。
2)访问对应的Region Server,获取hbase:meta表,根据写请求的namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。
3)与目标Region Server进行通讯;
4)将数据顺序写入(追加)到WAL;
5)将数据写入对应的MemStore,数据会在MemStore进行排序;
6)向客户端发送ack;
7)等达到MemStore的刷写时机后,将数据刷写到HFile。
问1:如果Region挂了,meta cache中的信息出错,怎么办?
答:master完成故障转移后,Region移动后meta表重新校准,读流程失败重试
问2:这里在与目标Region的RegionServer通讯之前是否需要和master通讯?
master负责Region的分配,通过master找到Region所在的节点
问3:如何保证写到HDFS上的数据不丢不重?
写到MemStore中就返回Ack,并不需要落盘.因为有预写日志,可以保证数据不丢.那么数据重复吗?也不会重复,因为hbase天然具有幂等性.往hbase中写数据时,需要表名/row key/列族/列/时间/类型,时间戳就保证了不可能有相同的一条数据.因此也不会重复.(这也是为什么写比读快?因为无需落盘就返回ack)
7 写缓存刷写时机
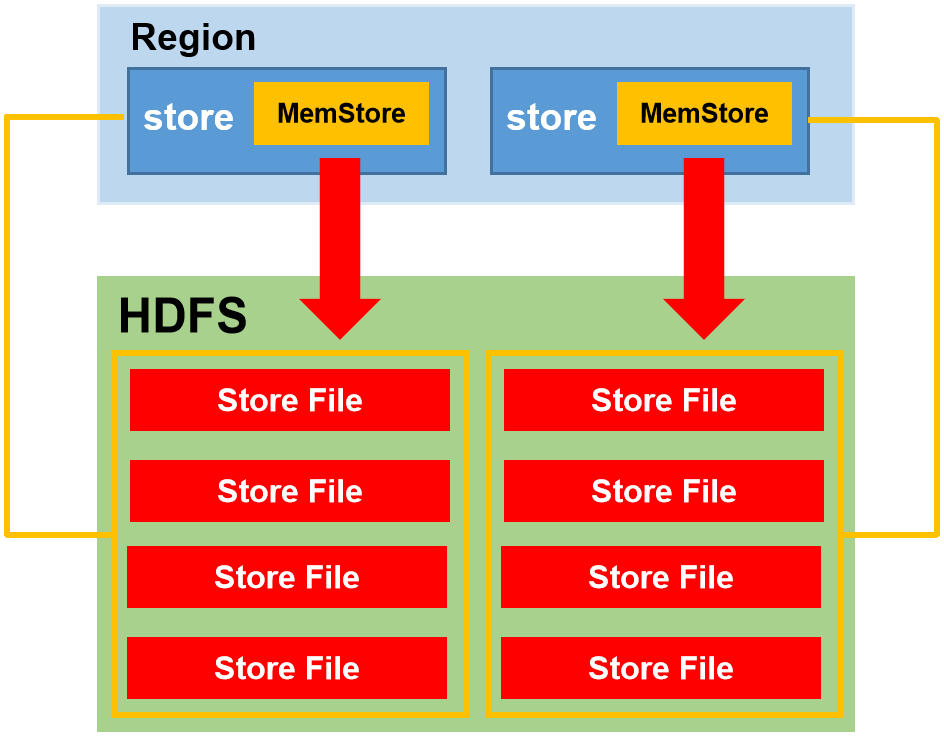
1)一个region中的某个store的memstore的大小达到了hbase.hregion.memstore.flush.size(默认值128M),其所在region的所有memstore都会刷写。
问:这里为什么会同时刷写一个region的所有store? 为了均衡一行的数据
2)一个region的某个store的memstore的大小达到了hbase.hregion.memstore.flush.size(默认值128M)* hbase.hregion.memstore.block.multiplier(默认值4)时,会阻止继续往该memstore写数据。
问:既然(1)中memstore达到128M,就落盘.为什么还会出现memstore达到128M * 4呢?
答:这是防止在128M的判断间隔,还没开始刷写,写缓存就已经过大导致内存溢出了,128M是刷写的判断条件,后者是写入写缓存的判断条件,两者并行判断,不在同一判断条件中
3)当region server中memstore的总大小达到(一个region server中有多个region,一个region中有多个store.每个store中有一个memstore.出现这种情况是该表列族过多导致,即过多的写缓存都未满128M).这个刷写是紧急避险措施):java_heapsize(jvm堆内存) * hbase.regionserver.global.memstore.size(默认值0.4)
*hbase.regionserver.global.memstore.size.lower.limit(默认值0.95),
region会按照其所有memstore的大小顺序(由大到小)依次进行刷写。直到region server中所有memstore的总大小减小到上述值以下。
4)当region server中memstore的总大小达到
java_heapsize
*hbase.regionserver.global.memstore.size(默认值0.4)
时,会阻止继续往所有的memstore写数据。
5)到达自动刷写的时间,也会触发memstore flush。配置hbase.regionserver.optionalcacheflushinterval(默认1小时)
6)当WAL文件的数量超过hbase.regionserver.max.logs,region会按照时间顺序依次进行刷写,直到WAL文件数量减小到hbase.regionserver.max.log以下
8 读流程
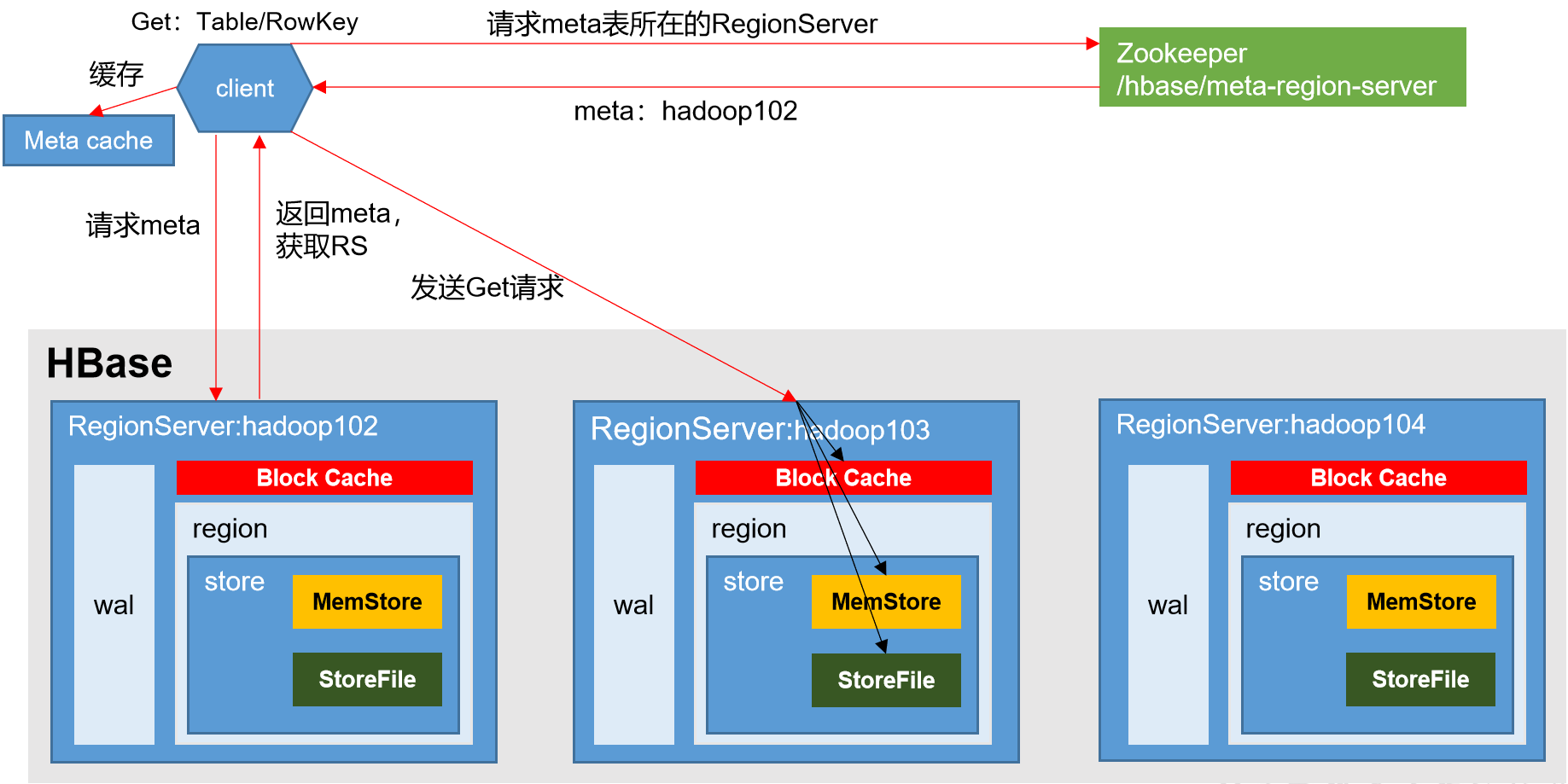
1)Client先访问zookeeper,获取hbase:meta表位于哪个Region Server。
2)访问对应的Region Server,获取hbase:meta表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个Region Server中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。
3)与目标Region Server进行通讯;
4)分别在MemStore和Store File(HFile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不同的类型(Put/Delete)。
5)将查询到的新的数据块(Block,HFile数据存储单元,默认大小为64KB)缓存到Block Cache。
6)将合并后的最终结果返回给客户端。
问1:读取的数据到底来自哪里?
答:HBase读取到三个地方数据合并,最终返回相同rowkey最新的版本,而不是只读取内存中的数据
问2:我怎么知道读缓存中的数据表示那些HFile已读过?
答:索引,HFile读到的Block有结构,为一块有序数据+索引(记录块的位置及rowkey范围)通过索引判断所读数据的rowkey是否属于该块,即是否缓存该块数据及整个HFile的索引.
问3:读缓存存在的意义?
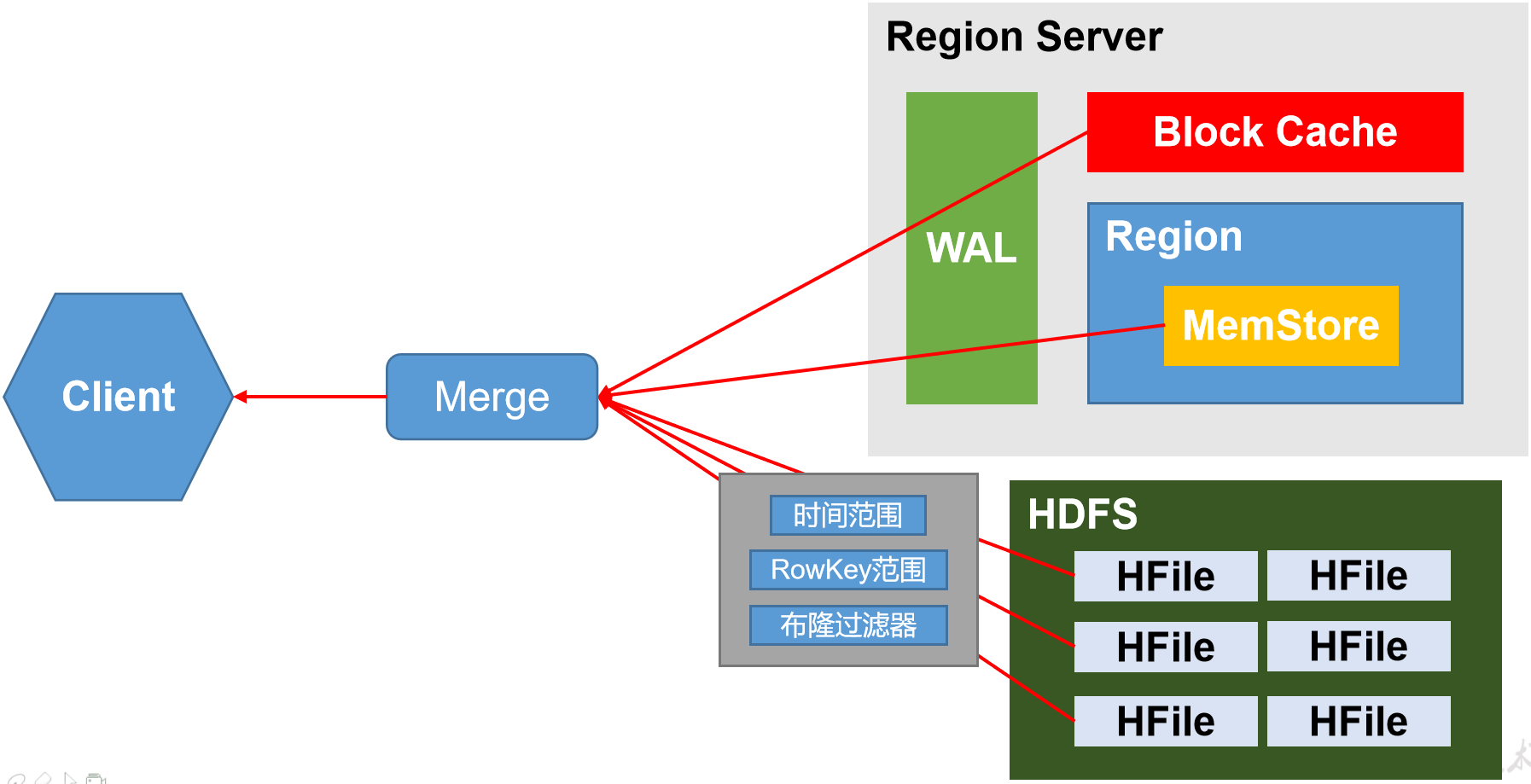
考虑到每次都从磁盘读效率低,所以从磁盘读的所需rowkey的数据放到读缓存,然后与写缓存的数据合并,这并不意味着读缓存有符合条件的数据就可以不扫描磁盘了,下次依旧会同时读磁盘和缓存,只是读过的文件不再扫描.因此当客户端向RegionServer发送get请求,读磁盘得到的数据放到读缓存和MemStore合并,Merge就是为了比较得到时间戳大的返回
问4:为什么HBase读比写慢?因为大量的数据在磁盘上,每次读会对该Region下所有HFile扫描
问5:每次读一定走磁盘吗?未必,数据量小且全表扫的数据已在读缓存中,同时又没有新的文件刷写到磁盘上,就不走磁盘了
问6:读HFile太费时间了,有优化吗?
有,三种过滤:1时间范围 2 HFile有RowKey范围,排过序,只需查看所需rowKey是否在范围里,缺点是不准确,文件中rowkey只有两个1001和9999,每次都要扫该文件,3 布隆,写到HFile时,根据rowkey标记,读时根据标记判断rowkey是否在文件中,底层使用了算法,标记可能产生哈希碰撞,不会影响结果,大不了判断失误多读个文件,可以减少但不能避免.布隆也可以用于统计日活,对登录用户去重
9 StoreFile Compaction
由于memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)和不同类型(Put/Delete)有可能会分布在不同的HFile中,因此查询时需要遍历所有的HFile。为了减少HFile的个数(解决HDFS小文件问题),以及清理掉过期和删除的数据,会进行StoreFile Compaction。
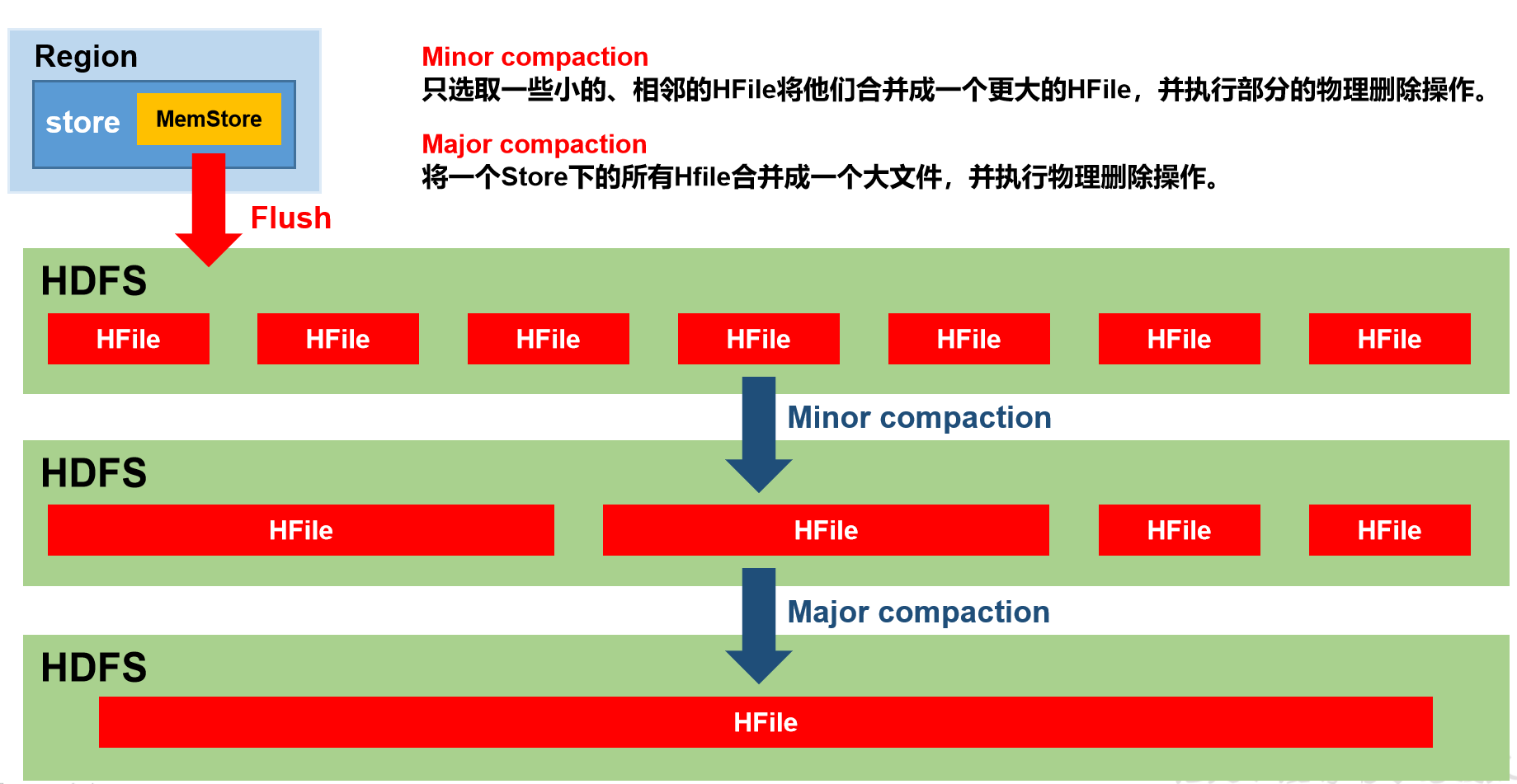
Minor Compaction(自动进行)和Major Compaction(默认7天,生产环境需要我们手动关闭.设置为0,手动关闭)。Minor Compaction会将临近的若干个较小的HFile合并成一个较大的HFile,并清理掉部分过期和删除的数据。Major Compaction会将一个Store下的所有的HFile合并成一个大HFile,并且会清理掉所有过期和删除的数据。
合并原理:归并排序,将多个有序小文件合并为一个有序大文件,先开辟合计大小的空间排序写入处理后的数据,写完再删除其他小文件
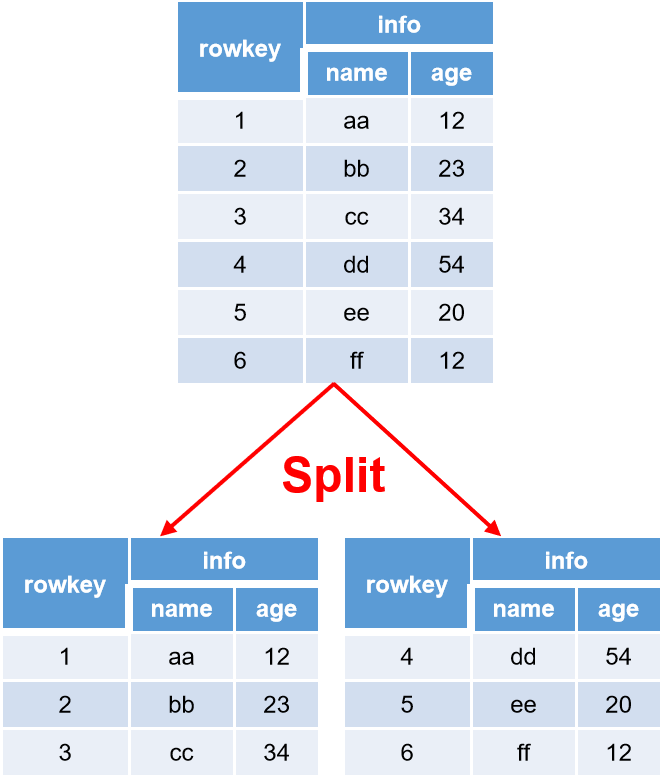
10 Region Split
问:拆分Region的意义?
开始时每个Table只有一个Region,随数据不断写入,Region自动拆分。刚拆分时,两个子Region都位于当前的Region Server,但处于负载均衡的考虑,HMaster有可能会将某个Region转移给其他的Region Server。此方式将一个表下多个Region交于多个RegionServer管理,即多个节点对同一表中数据达成分布式操作,提高了效率.
拆分时机:
Hbase 2.0引入了新的split策略:如果当前RegionServer上该表只有一个Region,按照2 * hbase.hregion.memstore.flush.size(256M)分裂,否则按照hbase.hregion.max.filesize(10G)分裂。
11 预分区
1)手动设定预分区
create 'staff1','info', SPLITS => ['1000','2000','3000','4000']
2)生成16进制序列预分区
create 'staff2','info',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
问:由于rowkey是字典序导致非数字和大写字母开头的rowkey集中在某个region导致数据倾斜?
解决:将rowkey的字符数组转为ascII码再转换为16进制数字即可均衡数据
3)按照文件中设置的规则预分区
文件中每一个字符串为一个rowkey切割线,并且会按字典序自动排序
create 'staff3', 'info',SPLITS_FILE => 'filepath'
4)使用JavaAPI创建预分区
12 RowKey设计
设计rowkey的主要目的 ,就是让数据均匀的分布于所有的region中,在一定程度上防止数据倾斜。
1)生成随机数.hash,散列值
2)字符串反转,以日期字符串作为rowkey为例,如果日期rowkey没有反转则同年同月的数据在一个分区,10/11月电商数据量大,易数据倾斜,反转后,毫秒在前不可控可以打散
3)字符串拼接

















 972
972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









