










系列文章目录
- MySQL分表分库基础
- 分库分表-ShardingSphere基础
- 分库分表ShardingSphere-ShardingJDBC数据分片实战1
- 分库分表ShardingSphere-ShardingJDBC数据分片实战2
- 分库分表ShardingSphere-ShardingJDBC源码解析
文章目录
前言
上一篇文章结合一个示例讲解ShardingJDBC的使用,通过ShardingJDBC框架实现了分表分库的应用场景,本文将深入ShardingJDBC进行源码解析
一、下载源码以及编译
1 下载源码
进入SharingSphere 官网下载界面,默认为最新版本源码下载,点击全部版本请到 Archive repository 查看可查看其它版本源码
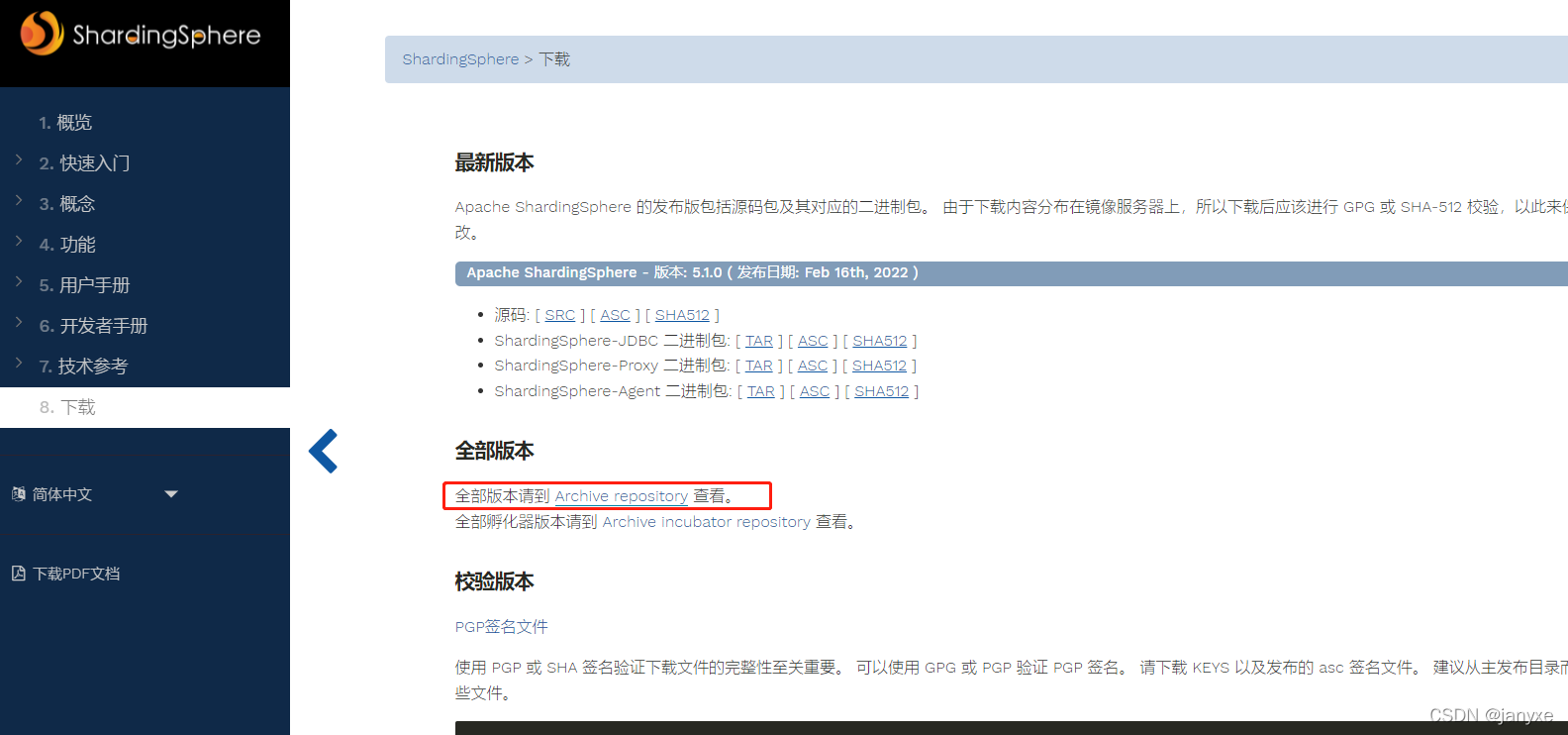
ShardingSphere多个版本源码,本文使用ShardingSphere 4.1.1版本进行讲解,源码下载地址
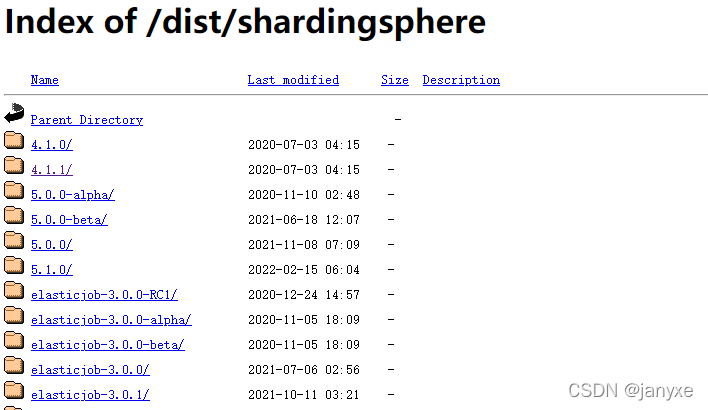
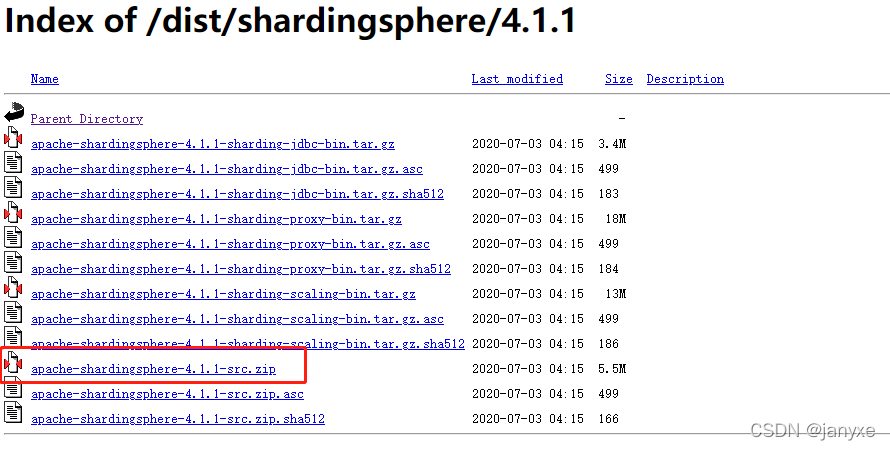
2 导入并编译源码
将下载的zip源码包导入IDEA,并执行maven命令mvn clean install -Dmaven.test.skip=true -Dmaven.javadoc.skip=true进行编译
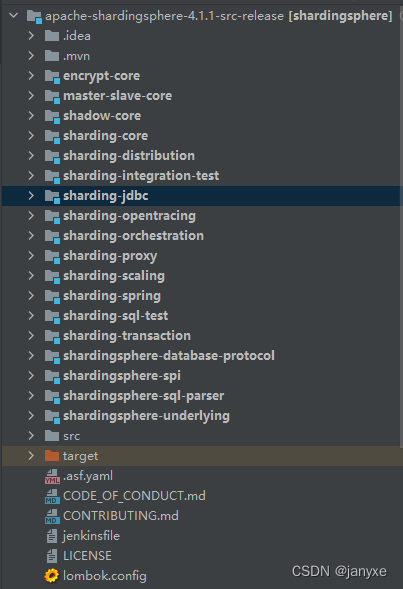
编译之后的源码目录
二、深入源码解析
1.根据JavaAPI分析源码入口
参考JavaAPI实现的ShardingJDBC
// 配置数据库
Map<String, DataSource> dataSourceMap = new HashMap<>(2);//为两个数据库的datasource
// 配置数据源
HikariDataSource dataSource0 = new HikariDataSource();
dataSource0.setDriverClassName("com.mysql.jdbc.Driver");
dataSource0.setJdbcUrl("jdbc:mysql://localhost:3306/db1");
dataSource0.setUsername("root");
dataSource0.setPassword("root");
dataSourceMap.put("db1", dataSource0);
// 配置分库分表策略
ShardingRuleConfiguration configurations = new ShardingRuleConfiguration();
// 真实表分布
TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration("order",
"db1.order");
PreciseShardingAlgorithm orderPreciseShardingAlgorithm = new orderPreciseShardingAlgorithm();
// 设置分库策略以及算法
orderTableRuleConfig.setDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration("column",orderPreciseShardingAlgorithm));
configurations.getTableRuleConfigs().add(orderTableRuleConfig);
// 配置属性值
Properties properties = new Properties();
// 打开日志输出
properties.setProperty("sql.show", "true");
// 创建数据源 (ShardingDataSource实现)
DataSource dataSource = ShardingSphereDataSourceFactory.
createDataSource(dataSourceMap, configurations, properties);
Connection connection = null;
try {
// 获取连接 (ShardingConnection实现)
connection = dataSource.getConnection();
// 创建 Statement (ShardingStatement 实现)
Statement statement = connection.createStatement();
String sql = "SELECT id,name from table1";
// 获取结果 (ShardingResultSet实现)
ResultSet result = statement.executeQuery(sql);
while (result.next()) {
System.out.println("result:" + result.getInt("id"));
logger.info("id={},name={}", result.getInt("id")), rs.getString("name"));
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
if (null != connection) {
// 关闭连接
connection.close();
}
}
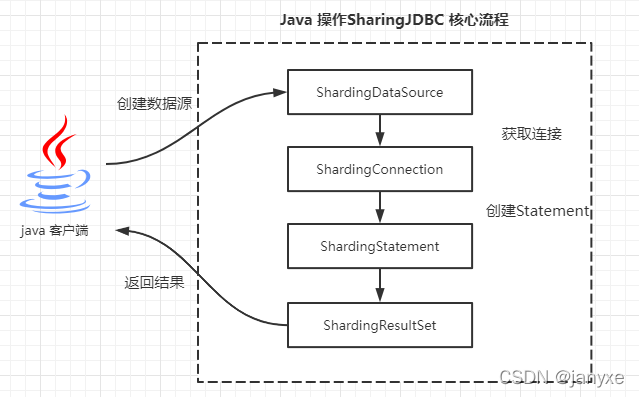
分析JavaAPI得知,ShardingJDBC需要经常创建数据源,获取连接,创建Statement以及返回结果四个阶段,接下来会对这四个阶段进行源码解析
2.创建数据源源码解析
2.1 源码入口
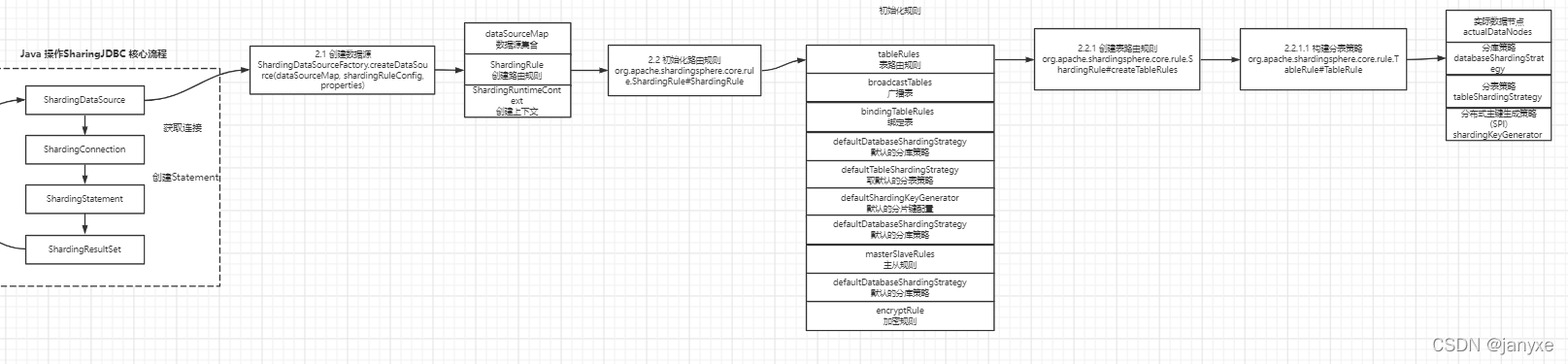
源码流程图
// 创建数据源 ShardingDataSource
DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, properties);
创建ShardingDataSource
org.apache.shardingsphere.shardingjdbc.api.ShardingDataSourceFactory#createDataSource
public static DataSource createDataSource(
final Map<String, DataSource> dataSourceMap, final ShardingRuleConfiguration shardingRuleConfig, final Properties props) throws SQLException {
// 创建ShardingDataSource 以及ShardingRule分片规则
return new ShardingDataSource(dataSourceMap, new ShardingRule(shardingRuleConfig, dataSourceMap.keySet()), props);
}
2.2 初始化路由规则
解析shardingRuleConfig,构建ShardingRule
org.apache.shardingsphere.core.rule.ShardingRule#ShardingRule
//解析ShardingConfig,构建ShardingRule
public ShardingRule(final ShardingRuleConfiguration shardingRuleConfig, final Collection<String> dataSourceNames) {
// 校验参数
Preconditions.checkArgument(null != shardingRuleConfig, "ShardingRuleConfig cannot be null.");
Preconditions.checkArgument(null != dataSourceNames && !dataSourceNames.isEmpty(), "Data sources cannot be empty.");
this.ruleConfiguration = shardingRuleConfig;
// 获取所有的实际数据库
shardingDataSourceNames = new ShardingDataSourceNames(shardingRuleConfig, dataSourceNames);
// 表路由规则
tableRules = createTableRules(shardingRuleConfig);
// 获取广播表
broadcastTables = shardingRuleConfig.getBroadcastTables();
// 绑定表
bindingTableRules = createBindingTableRules(shardingRuleConfig.getBindingTableGroups());
// 获取默认的分库策略并创建
defaultDatabaseShardingStrategy = createDefaultShardingStrategy(shardingRuleConfig.getDefaultDatabaseShardingStrategyConfig());
// 获取默认的分表策略并创建
defaultTableShardingStrategy = createDefaultShardingStrategy(shardingRuleConfig.getDefaultTableShardingStrategyConfig());
// 分片键配置
defaultShardingKeyGenerator = createDefaultKeyGenerator(shardingRuleConfig.getDefaultKeyGeneratorConfig());
// 主从规则
masterSlaveRules = createMasterSlaveRules(shardingRuleConfig.getMasterSlaveRuleConfigs());
// 加密规则
encryptRule = createEncryptRule(shardingRuleConfig.getEncryptRuleConfig());
}
2.2.1 创建表路由规则
org.apache.shardingsphere.core.rule.ShardingRule#createTableRules
private Collection<TableRule> createTableRules(final ShardingRuleConfiguration shardingRuleConfig) {
// 分片规则过滤,每个表规则配置生成TableRule
return shardingRuleConfig.getTableRuleConfigs().stream().map(each ->
new TableRule(each, shardingDataSourceNames, getDefaultGenerateKeyColumn(shardingRuleConfig))).collect(Collectors.toList());
}
2.2.1.1 构建分表策略
org.apache.shardingsphere.core.rule.TableRule#TableRule(org.apache.shardingsphere.api.config.sharding.TableRuleConfiguration, org.apache.shardingsphere.core.rule.ShardingDataSourceNames, java.lang.String)
public TableRule(final TableRuleConfiguration tableRuleConfig, final ShardingDataSourceNames shardingDataSourceNames, final String defaultGenerateKeyColumn) {
// 获取逻辑表
logicTable = tableRuleConfig.getLogicTable().toLowerCase();
List<String> dataNodes = new InlineExpressionParser(tableRuleConfig.getActualDataNodes()).splitAndEvaluate();
dataNodeIndexMap = new HashMap<>(dataNodes.size(), 1);
// 获取实际数据库列表,收集到actualTables
actualDataNodes = isEmptyDataNodes(dataNodes)
? generateDataNodes(tableRuleConfig.getLogicTable(), shardingDataSourceNames.getDataSourceNames()) : generateDataNodes(dataNodes, shardingDataSourceNames.getDataSourceNames());
actualTables = getActualTables();
// 分库策略
databaseShardingStrategy = null == tableRuleConfig.getDatabaseShardingStrategyConfig() ? null : ShardingStrategyFactory.newInstance(tableRuleConfig.getDatabaseShardingStrategyConfig());
// 分表策略
tableShardingStrategy = null == tableRuleConfig.getTableShardingStrategyConfig() ? null : ShardingStrategyFactory.newInstance(tableRuleConfig.getTableShardingStrategyConfig());
final KeyGeneratorConfiguration keyGeneratorConfiguration = tableRuleConfig.getKeyGeneratorConfig();
// 自动生成的主键列
generateKeyColumn = null != keyGeneratorConfiguration && !Strings.isNullOrEmpty(keyGeneratorConfiguration.getColumn()) ? keyGeneratorConfiguration.getColumn() : defaultGenerateKeyColumn;
//SPI: 获取分布式主键,分片键有UUID和SNOWFLAKE两个实现类
// 检查是否有分片算法配置,没有则返回null,有执行 new ShardingKeyGeneratorServiceLoader().newService SPI
shardingKeyGenerator = containsKeyGeneratorConfiguration(tableRuleConfig)
? new ShardingKeyGeneratorServiceLoader().newService(tableRuleConfig.getKeyGeneratorConfig().getType(), tableRuleConfig.getKeyGeneratorConfig().getProperties()) : null;
checkRule(dataNodes);
}
SPI方式实现了分布式主键
org.apache.shardingsphere.spi.algorithm.keygen.ShardingKeyGeneratorServiceLoader
public final class ShardingKeyGeneratorServiceLoader extends TypeBasedSPIServiceLoader<ShardingKeyGenerator> {
static {
//SPI: 加载ShardingKeyGenerator 主键生成策略
NewInstanceServiceLoader.register(ShardingKeyGenerator.class);
}
public ShardingKeyGeneratorServiceLoader() {
super(ShardingKeyGenerator.class);
}
}
找到SPI配置文件
src/main/resources/META-INF/services/org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator
ShardingJDBC实现了雪花算法和UUID
org.apache.shardingsphere.core.strategy.keygen.SnowflakeShardingKeyGenerator
org.apache.shardingsphere.core.strategy.keygen.UUIDShardingKeyGenerator
2.3 创建数据源构造函数
org.apache.shardingsphere.shardingjdbc.jdbc.core.datasource.ShardingDataSource#ShardingDataSource
@Getter
public class ShardingDataSource extends AbstractDataSourceAdapter {
private final ShardingRuntimeContext runtimeContext;
static {
//SPI: 加载路由组件
NewInstanceServiceLoader.register(RouteDecorator.class);
//SPI: 加载SQL重写组件
NewInstanceServiceLoader.register(SQLRewriteContextDecorator.class);
//SPI: 加载结果处理组件
NewInstanceServiceLoader.register(ResultProcessEngine.class);
}
public ShardingDataSource(final Map<String, DataSource> dataSourceMap, final ShardingRule shardingRule, final Properties props) throws SQLException {
// 获取数据库类型
// 通过spring.shardingsphere.datasource.xxx.url配置获取数据库类型
super(dataSourceMap);
//检查数据库类型
checkDataSourceType(dataSourceMap);
// 创建上下文
runtimeContext = new ShardingRuntimeContext(dataSourceMap, shardingRule, props, getDatabaseType());
}
private void checkDataSourceType(final Map<String, DataSource> dataSourceMap) {
for (DataSource each : dataSourceMap.values()) {
Preconditions.checkArgument(!(each instanceof MasterSlaveDataSource), "Initialized data sources can not be master-slave data sources.");
}
}
@Override
public final ShardingConnection getConnection() {
return new ShardingConnection(getDataSourceMap(), runtimeContext, TransactionTypeHolder.get());
}
}
2.3.1 初始化上下文
org.apache.shardingsphere.shardingjdbc.jdbc.core.context.ShardingRuntimeContext#ShardingRuntimeContext
public ShardingRuntimeContext(final Map<String, DataSource> dataSourceMap, final ShardingRule shardingRule, final Properties props, final DatabaseType databaseType) throws SQLException {
super(dataSourceMap, shardingRule, props, databaseType);
//创建分片规则缓存
cachedDatabaseMetaData = createCachedDatabaseMetaData(dataSourceMap);
shardingTransactionManagerEngine = new ShardingTransactionManagerEngine();
// 事务管理器初始化
shardingTransactionManagerEngine.init(databaseType, dataSourceMap);
}
2.3.2 事务管理器初始化
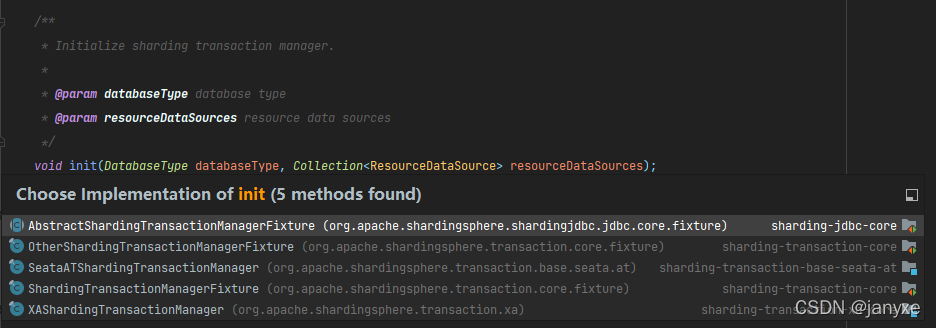
org.apache.shardingsphere.transaction.ShardingTransactionManagerEngine#init
public void init(final DatabaseType databaseType, final Map<String, DataSource> dataSourceMap) {
for (Entry<TransactionType, ShardingTransactionManager> entry : transactionManagerMap.entrySet()) {
entry.getValue().init(databaseType, getResourceDataSources(dataSourceMap));
}
}
org.apache.shardingsphere.transaction.spi.ShardingTransactionManager 不同的实现,加上相关配置即可开启
3 获取Connection 源码解析
3.1 源码入口
// 获取连接对象
Connection conn = dataSource.getConnection();
3.2 ShardingConnection实现连接
org.apache.shardingsphere.shardingjdbc.jdbc.core.datasource.ShardingDataSource#getConnection
传入数据源集合,上下文对象以及事务类型(LOCAL, XA, BASE)
public final ShardingConnection getConnection() {
return new ShardingConnection(getDataSourceMap(), runtimeContext, TransactionTypeHolder.get());
}
3.3 ShardingConnection 构造方法
org.apache.shardingsphere.shardingjdbc.jdbc.core.connection.ShardingConnection#ShardingConnection
public ShardingConnection(final Map<String, DataSource> dataSourceMap, final ShardingRuntimeContext runtimeContext, final TransactionType transactionType) {
this.dataSourceMap = dataSourceMap;
// 上下文对象
this.runtimeContext = runtimeContext;
this.transactionType = transactionType;
// 事务管理器
shardingTransactionManager = runtimeContext.getShardingTransactionManagerEngine().getTransactionManager(transactionType);
}
4 createStatement 源码解析
4.1 源码入口
Statement statement = connection.createStatement();
4.2 ShardingStatement构造方法创建
org.apache.shardingsphere.shardingjdbc.jdbc.core.connection.ShardingConnection#createStatement()
public Statement createStatement() {
return new ShardingStatement(this);
}
4.3 ShardingStatement构造方法创建StatementExecutor对象
org.apache.shardingsphere.shardingjdbc.jdbc.core.statement.ShardingStatement#ShardingStatement(org.apache.shardingsphere.shardingjdbc.jdbc.core.connection.ShardingConnection)
public ShardingStatement(final ShardingConnection connection) {
this(connection, ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY, ResultSet.HOLD_CURSORS_OVER_COMMIT);
}
public ShardingStatement(final ShardingConnection connection, final int resultSetType, final int resultSetConcurrency) {
this(connection, resultSetType, resultSetConcurrency, ResultSet.HOLD_CURSORS_OVER_COMMIT);
}
public ShardingStatement(final ShardingConnection connection, final int resultSetType, final int resultSetConcurrency, final int resultSetHoldability) {
super(Statement.class);
this.connection = connection;
statementExecutor = new StatementExecutor(resultSetType, resultSetConcurrency, resultSetHoldability, connection);
}
5 statement.executeQuery 查询逻辑
5.1 源码入口
java.sql.Statement#executeQuery
ResultSet result = statement.executeQuery(sql);
5.2 执行语句过程
org.apache.shardingsphere.shardingjdbc.jdbc.core.statement.ShardingStatement#executeQuery
@Override
public ResultSet executeQuery(final String sql) throws SQLException {
if (Strings.isNullOrEmpty(sql)) {
throw new SQLException(SQLExceptionConstant.SQL_STRING_NULL_OR_EMPTY);
}
ResultSet result;
try {
// 这个上下文中包含了实际运行所需要的全部信息。包括真实数据源、真实SQL、真实参数
// 执行引擎的准备阶段
executionContext = prepare(sql);
// 执行引擎的执行阶段
List<QueryResult> queryResults = statementExecutor.executeQuery();
// 结果归并阶段
MergedResult mergedResult = mergeQuery(queryResults);
result = new ShardingResultSet(statementExecutor.getResultSets(), mergedResult, this, executionContext);
} finally {
currentResultSet = null;
}
currentResultSet = result;
return result;
}
执行流程图
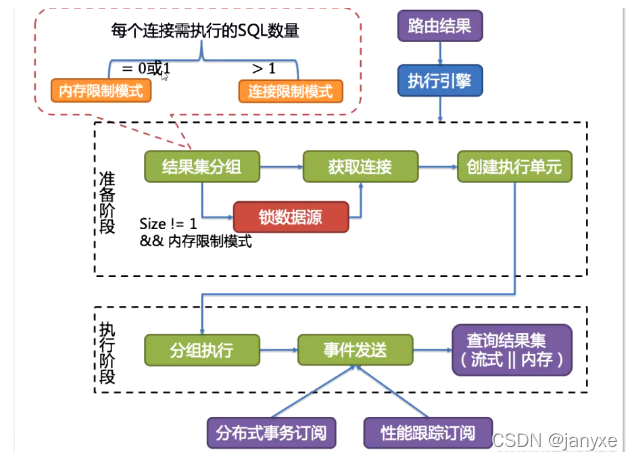
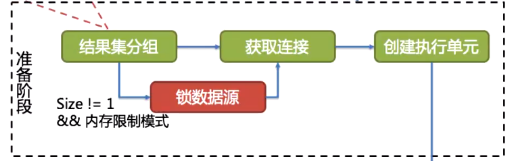
5.2.1 准备阶段
执行引擎的准备阶段:结果集分组->获取连接->创建执行单元
源码入口
executionContext = prepare(sql);
org.apache.shardingsphere.shardingjdbc.jdbc.core.statement.ShardingStatement#prepare
private ExecutionContext prepare(final String sql) throws SQLException {
statementExecutor.clear();
ShardingRuntimeContext runtimeContext = connection.getRuntimeContext();
BasePrepareEngine prepareEngine = new SimpleQueryPrepareEngine(
runtimeContext.getRule().toRules(), runtimeContext.getProperties(), runtimeContext.getMetaData(), runtimeContext.getSqlParserEngine());
ExecutionContext result = prepareEngine.prepare(sql, Collections.emptyList());
statementExecutor.init(result);
statementExecutor.getStatements().forEach(this::replayMethodsInvocation);
return result;
}
org.apache.shardingsphere.underlying.pluggble.prepare.BasePrepareEngine#prepare
public ExecutionContext prepare(final String sql, final List<Object> parameters) {
List<Object> clonedParameters = cloneParameters(parameters);
RouteContext routeContext = executeRoute(sql, clonedParameters);
// 创建执行上下文
ExecutionContext result = new ExecutionContext(routeContext.getSqlStatementContext());
// 重写逻辑SQL,将真实执行单元保存到上下文中
result.getExecutionUnits().addAll(executeRewrite(sql, clonedParameters, routeContext));
if (properties.<Boolean>getValue(ConfigurationPropertyKey.SQL_SHOW)) {
SQLLogger.logSQL(sql, properties.<Boolean>getValue(ConfigurationPropertyKey.SQL_SIMPLE), result.getSqlStatementContext(), result.getExecutionUnits());
}
return result;
}
重写SQL,将逻辑SQL转化为实际SQL,创建执行单元
org.apache.shardingsphere.underlying.pluggble.prepare.BasePrepareEngine#executeRewrite
private Collection<ExecutionUnit> executeRewrite(final String sql, final List<Object> parameters, final RouteContext routeContext) {
//SQL重写引擎装饰者
registerRewriteDecorator();
SQLRewriteContext sqlRewriteContext = rewriter.createSQLRewriteContext(sql, parameters, routeContext.getSqlStatementContext(), routeContext);
return routeContext.getRouteResult().getRouteUnits().isEmpty() ? rewrite(sqlRewriteContext) : rewrite(routeContext, sqlRewriteContext);
}
初始化执行器
org.apache.shardingsphere.shardingjdbc.executor.StatementExecutor#init
public void init(final ExecutionContext executionContext) throws SQLException {
setSqlStatementContext(executionContext.getSqlStatementContext());
// 保存需要执行的真实数据,真实SQL和参数。
getInputGroups().addAll(getExecuteGroups(executionContext.getExecutionUnits()));
cacheStatements();
}
5.2.2 执行阶段
执行阶段包括 分组执行->时间发送->查询结果集
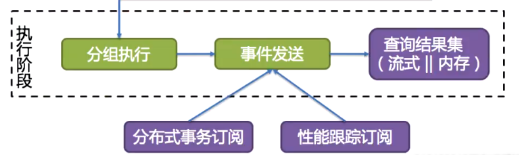
源码入口
org.apache.shardingsphere.shardingjdbc.executor.StatementExecutor#executeQuery
List<QueryResult> queryResults = statementExecutor.executeQuery();
org.apache.shardingsphere.shardingjdbc.executor.StatementExecutor#executeQuery
public List<QueryResult> executeQuery() throws SQLException {
final boolean isExceptionThrown = ExecutorExceptionHandler.isExceptionThrown();
SQLExecuteCallback<QueryResult> executeCallback = new SQLExecuteCallback<QueryResult>(getDatabaseType(), isExceptionThrown) {
@Override
protected QueryResult executeSQL(final String sql, final Statement statement, final ConnectionMode connectionMode) throws SQLException {
return getQueryResult(sql, statement, connectionMode);
}
};
// 执行SQL逻辑
return executeCallback(executeCallback);
}
org.apache.shardingsphere.shardingjdbc.executor.AbstractStatementExecutor#executeCallback
@SuppressWarnings("unchecked")
protected final <T> List<T> executeCallback(final SQLExecuteCallback<T> executeCallback) throws SQLException {
List<T> result = sqlExecuteTemplate.execute((Collection) inputGroups, executeCallback);
// inputGroups中包含了所需执行的真实数据库以及真实SQL和参数(在准备阶段保存的)
refreshMetaDataIfNeeded(connection.getRuntimeContext(), sqlStatementContext);
return result;
}
org.apache.shardingsphere.sharding.execute.sql.execute.SQLExecuteTemplate#execute(java.util.Collection<org.apache.shardingsphere.underlying.executor.engine.InputGroup<? extends org.apache.shardingsphere.sharding.execute.sql.StatementExecuteUnit>>, org.apache.shardingsphere.sharding.execute.sql.execute.SQLExecuteCallback)
public <T> List<T> execute(final Collection<InputGroup<? extends StatementExecuteUnit>> inputGroups, final SQLExecuteCallback<T> callback) throws SQLException {
return execute(inputGroups, null, callback);
}
org.apache.shardingsphere.sharding.execute.sql.execute.SQLExecuteTemplate#execute(java.util.Collection<org.apache.shardingsphere.underlying.executor.engine.InputGroup<? extends org.apache.shardingsphere.sharding.execute.sql.StatementExecuteUnit>>, org.apache.shardingsphere.sharding.execute.sql.execute.SQLExecuteCallback, org.apache.shardingsphere.sharding.execute.sql.execute.SQLExecuteCallback)
public <T> List<T> execute(final Collection<InputGroup<? extends StatementExecuteUnit>> inputGroups,
final SQLExecuteCallback<T> firstCallback, final SQLExecuteCallback<T> callback) throws SQLException {
try {
//serial 串行还是并行,取决于连接模式
return executorEngine.execute((Collection) inputGroups, firstCallback, callback, serial);
} catch (final SQLException ex) {
ExecutorExceptionHandler.handleException(ex);
return Collections.emptyList();
}
}
判断是否是串行还是并行
org.apache.shardingsphere.underlying.executor.engine.ExecutorEngine#execute(java.util.Collection<org.apache.shardingsphere.underlying.executor.engine.InputGroup>, org.apache.shardingsphere.underlying.executor.engine.GroupedCallback<I,O>, org.apache.shardingsphere.underlying.executor.engine.GroupedCallback<I,O>, boolean)
public <I, O> List<O> execute(final Collection<InputGroup<I>> inputGroups,
final GroupedCallback<I, O> firstCallback, final GroupedCallback<I, O> callback, final boolean serial) throws SQLException {
if (inputGroups.isEmpty()) {
return Collections.emptyList();
}
return serial ? serialExecute(inputGroups, firstCallback, callback) : parallelExecute(inputGroups, firstCallback, callback);
}
5.2.3 结果归并阶段
源码入口
MergedResult mergedResult = mergeQuery(queryResults);
result = new ShardingResultSet(statementExecutor.getResultSets(), mergedResult, this, executionContext);
org.apache.shardingsphere.shardingjdbc.jdbc.core.statement.ShardingStatement#mergeQuery
private MergedResult mergeQuery(final List<QueryResult> queryResults) throws SQLException {
ShardingRuntimeContext runtimeContext = connection.getRuntimeContext();
MergeEngine mergeEngine = new MergeEngine(runtimeContext.getRule().toRules(), runtimeContext.getProperties(), runtimeContext.getDatabaseType(), runtimeContext.getMetaData().getSchema());
return mergeEngine.merge(queryResults, executionContext.getSqlStatementContext());
}
org.apache.shardingsphere.underlying.pluggble.merge.MergeEngine#merge
public MergedResult merge(final List<QueryResult> queryResults, final SQLStatementContext sqlStatementContext) throws SQLException {
registerMergeDecorator();
return merger.process(queryResults, sqlStatementContext);
}
处理查询结果
org.apache.shardingsphere.underlying.merge.MergeEntry#process
public MergedResult process(final List<QueryResult> queryResults, final SQLStatementContext sqlStatementContext) throws SQLException {
// 合并
Optional<MergedResult> mergedResult = merge(queryResults, sqlStatementContext);
Optional<MergedResult> result = mergedResult.isPresent() ? Optional.of(decorate(mergedResult.get(), sqlStatementContext)) : decorate(queryResults.get(0), sqlStatementContext);
return result.orElseGet(() -> new TransparentMergedResult(queryResults.get(0)));
}
org.apache.shardingsphere.underlying.merge.MergeEntry#merge
private Optional<MergedResult> merge(final List<QueryResult> queryResults, final SQLStatementContext sqlStatementContext) throws SQLException {
for (Entry<BaseRule, ResultProcessEngine> entry : engines.entrySet()) {
if (entry.getValue() instanceof ResultMergerEngine) {
ResultMerger resultMerger = ((ResultMergerEngine) entry.getValue()).newInstance(databaseType, entry.getKey(), properties, sqlStatementContext);
return Optional.of(resultMerger.merge(queryResults, sqlStatementContext, schemaMetaData));
}
}
return Optional.empty();
}
结果合并的三种实现类
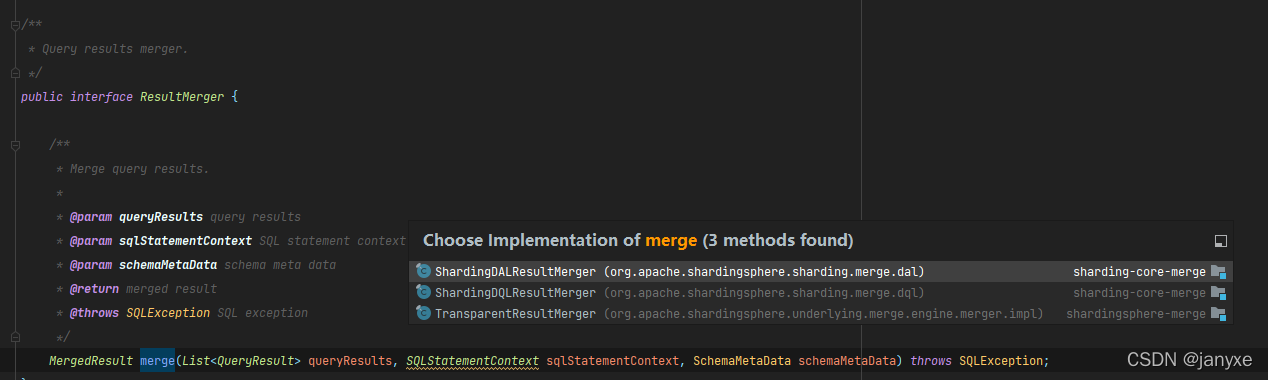
org.apache.shardingsphere.sharding.merge.dql.ShardingDQLResultMerger#merge
public MergedResult merge(final List<QueryResult> queryResults, final SQLStatementContext sqlStatementContext, final SchemaMetaData schemaMetaData) throws SQLException {
if (1 == queryResults.size()) {
return new IteratorStreamMergedResult(queryResults);
}
Map<String, Integer> columnLabelIndexMap = getColumnLabelIndexMap(queryResults.get(0));
SelectStatementContext selectStatementContext = (SelectStatementContext) sqlStatementContext;
selectStatementContext.setIndexes(columnLabelIndexMap);
MergedResult mergedResult = build(queryResults, selectStatementContext, columnLabelIndexMap, schemaMetaData);
// 处理分页
return decorate(queryResults, selectStatementContext, mergedResult);
}
根据不同的数据库类型执行相对应的分页逻辑
org.apache.shardingsphere.sharding.merge.dql.ShardingDQLResultMerger#decorate
private MergedResult decorate(final List<QueryResult> queryResults, final SelectStatementContext selectStatementContext, final MergedResult mergedResult) throws SQLException {
PaginationContext paginationContext = selectStatementContext.getPaginationContext();
if (!paginationContext.isHasPagination() || 1 == queryResults.size()) {
return mergedResult;
}
String trunkDatabaseName = DatabaseTypes.getTrunkDatabaseType(databaseType.getName()).getName();
if ("MySQL".equals(trunkDatabaseName) || "PostgreSQL".equals(trunkDatabaseName)) {
return new LimitDecoratorMergedResult(mergedResult, paginationContext);
}
if ("Oracle".equals(trunkDatabaseName)) {
return new RowNumberDecoratorMergedResult(mergedResult, paginationContext);
}
if ("SQLServer".equals(trunkDatabaseName)) {
return new TopAndRowNumberDecoratorMergedResult(mergedResult, paginationContext);
}
return mergedResult;
}
结果归并
org.apache.shardingsphere.shardingjdbc.jdbc.core.resultset.ShardingResultSet#ShardingResultSet
public ShardingResultSet(final List<ResultSet> resultSets, final MergedResult mergeResultSet, final Statement statement, final ExecutionContext executionContext) throws SQLException {
super(resultSets, statement, executionContext);
this.mergeResultSet = mergeResultSet;
columnLabelAndIndexMap = createColumnLabelAndIndexMap(resultSets.get(0).getMetaData());
}
private Map<String, Integer> createColumnLabelAndIndexMap(final ResultSetMetaData resultSetMetaData) throws SQLException {
Map<String, Integer> result = new TreeMap<>(String.CASE_INSENSITIVE_ORDER);
for (int columnIndex = resultSetMetaData.getColumnCount(); columnIndex > 0; columnIndex--) {
result.put(resultSetMetaData.getColumnLabel(columnIndex), columnIndex);
}
return result;
}
总结
以上就是本节根据 ShardingJDBC JavaAPI 为切入点分析源码的过程 ,ShardingJDBC实现了JDBC规范对代码进行了增强。



















 7954
7954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











