



Linux是一个多任务操作系统,这些任务通过共享cpu的方式实现了宏观上的并行执行。
调度器的主要工作就是为这些任务分配cpu运行时间,并尽量保证它们在相同的调度策略中能得到公平的对待。
当前内核默认支持五大调度类,分别是stop调度类、deadline调度类、rt调度类、cfs调度类以及idle调度类。它们的特点如下:
- stop_sched_class
- dl_sched_class
- rt_sched_class
- fair_sched_class
- idle_sched_class
(1)stop调度类:具有最高的优先级,它能抢占所有其它的进程,且不会被其它进程抢占。同一时刻只有一个任务被设定为stop_sched_class。
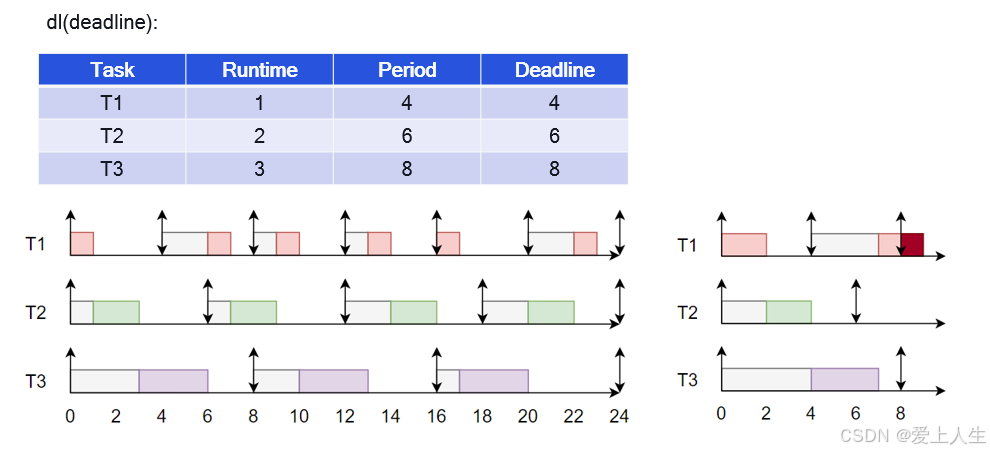
(2)deadline调度类:它的优先级介于stop调度类和rt调度类之间。主要用于那些在每个给定周期内,都需要在设定的截止期限之前被调度的任务。
deadline调度器只有一种调度策略:SCHED_DEADLINE。deadline调度器选取 deadline 距离当前时间点最近的进程并执行它。
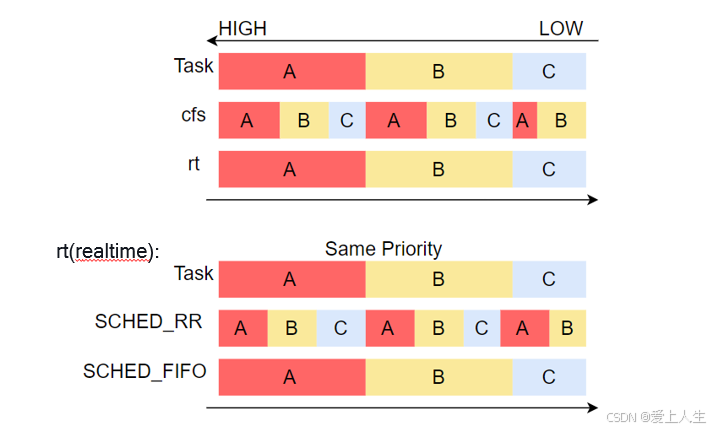
(3)rt调度类:它的优先级低于deadline调度类,但高于cfs调度类,其主要用于那些实时性要求较高的任务。这种任务将严格按照优先级调度,低优先级的任务不能抢占高优先级任务。
但其对相同优先级的任务具有两种调度策略,SCHED_FIFO 和 SCHED_RR。其中:
SCHED_FIFO:这种任务被调度后,只能被比它优先级更高的任务抢占。而与其优先级相同的任务只能等该任务运行完成后才能被调度
SCHED_RR:它与SCHED_FIFO唯一的不同,是若就绪队列中含有与其相同优先级的任务时,它们之间采用时间片轮转的方式调度
(4)cfs调度类:它采用完全公平调度算法。它也包含两种调度策略,SCHED_NORMAL和SCHED_BATCH。
SCHED_NORMAL 是 CFS 的基本实现,采用了到的 “时间片轮转“ 和 “动态优先级“ 调度机制。
动态优先级:普通进程具有一个 nice 值来表示其优先级,nice 值越小,进程优先级越高。
时间片轮转:如果有多个普通进程的优先级相同,则采用轮流执行的方式。
其中SCHED_BATCH是批处理进程,它的主要目的是在系统空闲时间运行一些需要大量 CPU 时间的后台任务。并不使用时间片轮转和动态优先级调度机制,而是采用了一种基于进程组的批量处理策略。该算法会将所有的后台任务进程加入到一个进程组中,该进程组会共享一个可调度时间片。
(5)idle调度类:idle进程具有最低优先级,只有当cpu上没有其它可调度进程时,才会调度该进程运行
PS:
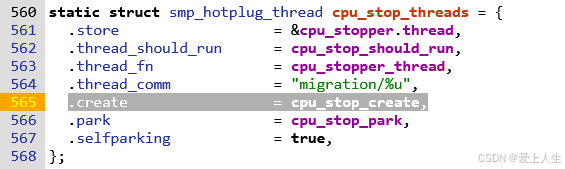
Stop调度器是系统中优先级最高的调度器,它的主要作用是在系统任务需要处理立即处理的功能时,抢占其他任务,并且不能被其他任务抢占。
stop调度的任务优先级非常高,因此它的任务通常需要短时间完成。Stop调度器一般在SMP系统上使用,用来做cpu hotplug和进程迁移(负载均衡)。
当产生一个调度点的时候,DL调度器总是选择其Deadline距离当前时间点最近的那个任务并调度它执行。
Σ(WCETi / Pi) <= M - (M - 1) x Umax
每个任务的(运行时间/周期)的总和应该小于或等于处理器的数目M,减去最大的利用率Umax乘以(M-1)
Umax是所有DL任务中,(运行时间/周期)值最大的那个(即对CPU资源需求最大)。
M=1: 1/2 + 1/2 = 1 <= 1
M=2: 1/2 + 1/2 = 1 <= 2 – (2-1) * 1/2 = 3/2

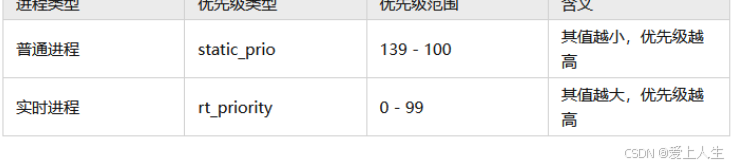
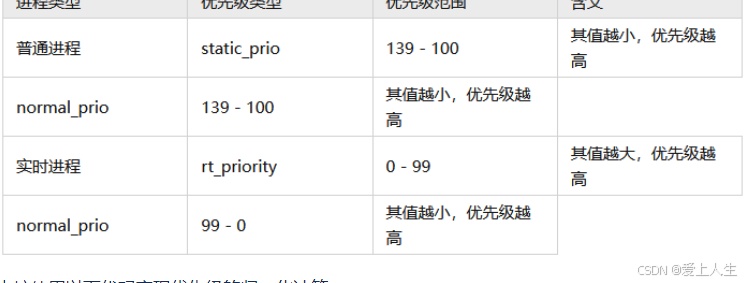
进程优先级
进程具有不同优先级,进程优先级是调度器选择下一个调度进程的主要依据。为此内核定义了以下四个与优先级相关的变量.
struct task_struct {

}
由于这两种优先级的含义并不相同,为了更方便地对它们进行统一管理,内核对其进行了归一化。其主要流程为:
(1)规定所有进程的优先级都归一化为其值越小,则优先级越高的方式。并用一个新的变量normal_prio表示
(2)普通进程的normal_prio等于其静态优先级static_prio,实时进程的normal_prio按以下公式转换:
normal_prio = MAX_RT_PRIO - 1 - rt_prio (其中MAX_RT_PRIO = 100)
通常情况下 normal_prio 在进程执行过程中是不变的。但是内核在运行过程中可能需要临时修改一个进程的优先级,以解决一些像优先级反转之类的问题。
因此内核引入了一个变量 prio 用于表示动态优先级,它在系统运行过程中可能会被临时修改,而调度器实际使用的就是动态优先级。
转换完成后,它们的关系如下图:
内核使用以下代码实现优先级的归一化计算.
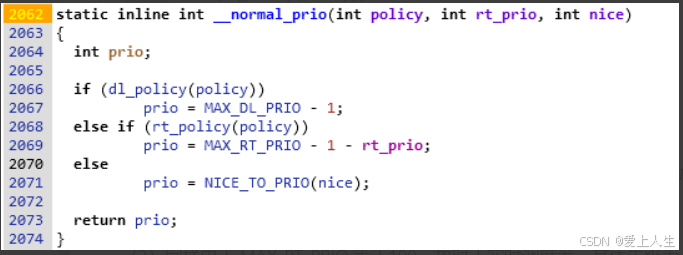
(1)由于MAX_DL_PRIO等于0,故对于deadline调度类,其优先级固定为-1
![]()
(2)同样由于 MAX_RT_PRIO 等于100,故对于实时调度类,其优先级为 99 – rt_prio
(3)对于普通进程,其优先级是通过nice值计算的。nice值是用户态用于表示进程优先级的一个参数,其值为-20 – 19,同样其值越小优先级越高。它与static_prio和normal_prio的关系都是有一个120的偏移。即static_prio = normal_prio = nice + 120
core.c - kernel/sched/core.c - Linux source code v6.13.6 - Bootlin Elixir Cross Referencer
(4)stop调度类,内核规定其优先级为-2。
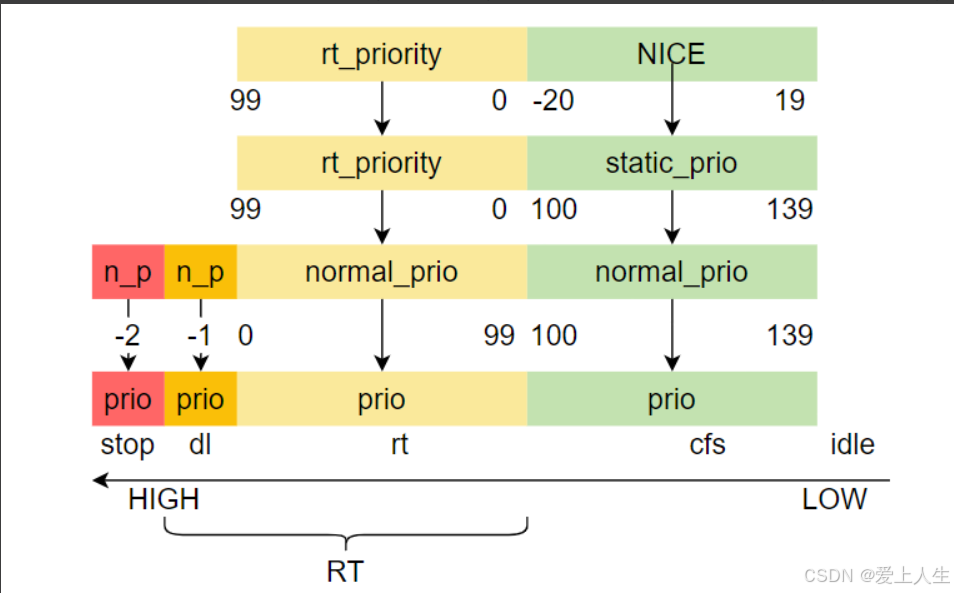
进程优先级之间的关系如下图:
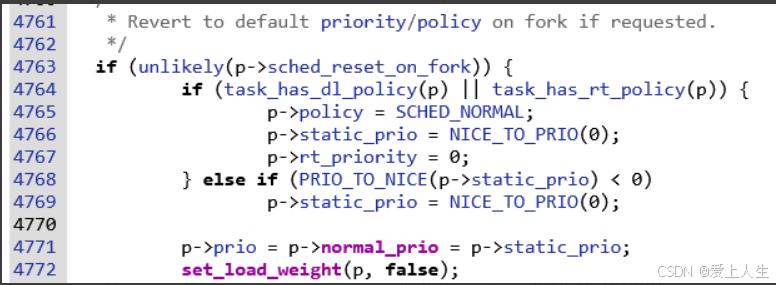
设置默认 policy/prio
设置子进程的调度类
初始化调度实体

__schedule
core.c - kernel/sched/core.c - Linux source code v6.13.6 - Bootlin Elixir Cross Referencer
__pick_next_task:挑选出下一个要执行的进程。
core.c - kernel/sched/core.c - Linux source code v6.13.6 - Bootlin Elixir Cross Referencer
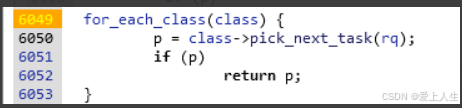
遍历所有调度器,根据优先级挑选出下一个要执行的进程。



















 896
896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









