






之前最开始使用声学模型为CNN+CTC,语言模型为自注意力模型或者隐式马尔科夫链进行做,发现效果算是一般。由于自注意力模型可以将前后关联起来,因此也可以用来进行做语音识别。最终训练了8000多条wav音频后,测试了下字错误率,发现效果还不错,在训练集上表现很优秀,字错误率1%以内。
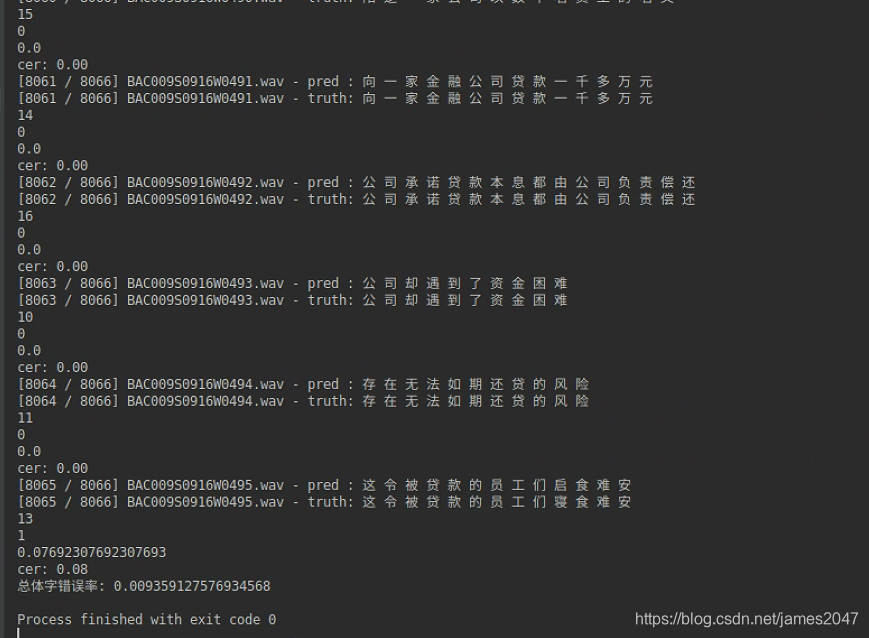

之前最开始使用声学模型为CNN+CTC,语言模型为自注意力模型或者隐式马尔科夫链进行做,发现效果算是一般。由于自注意力模型可以将前后关联起来,因此也可以用来进行做语音识别。最终训练了8000多条wav音频后,测试了下字错误率,发现效果还不错,在训练集上表现很优秀,字错误率1%以内。

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言






















 1212
1212







