



论文链接 arxiv
参考 优快云
1. 动机
由于 natural prior(比如 暗通道先验,大气散射模型等等) 很难描述所有的现实复杂情况,只能对某一类图像退化进行建模. 而 Diffusion 可以对复杂先验进行学习. 而 latent diffusion 极大地减少了参数量, 为后续的工作提供了可能;
此外, DM 会生成一些不必要的 artifect, 造成低 psnr,因此将 Transformer 作为 basemodel;
DMs generate a more accurate target distribution without encountering optimization instability or mode collapse;
2. 方法流程
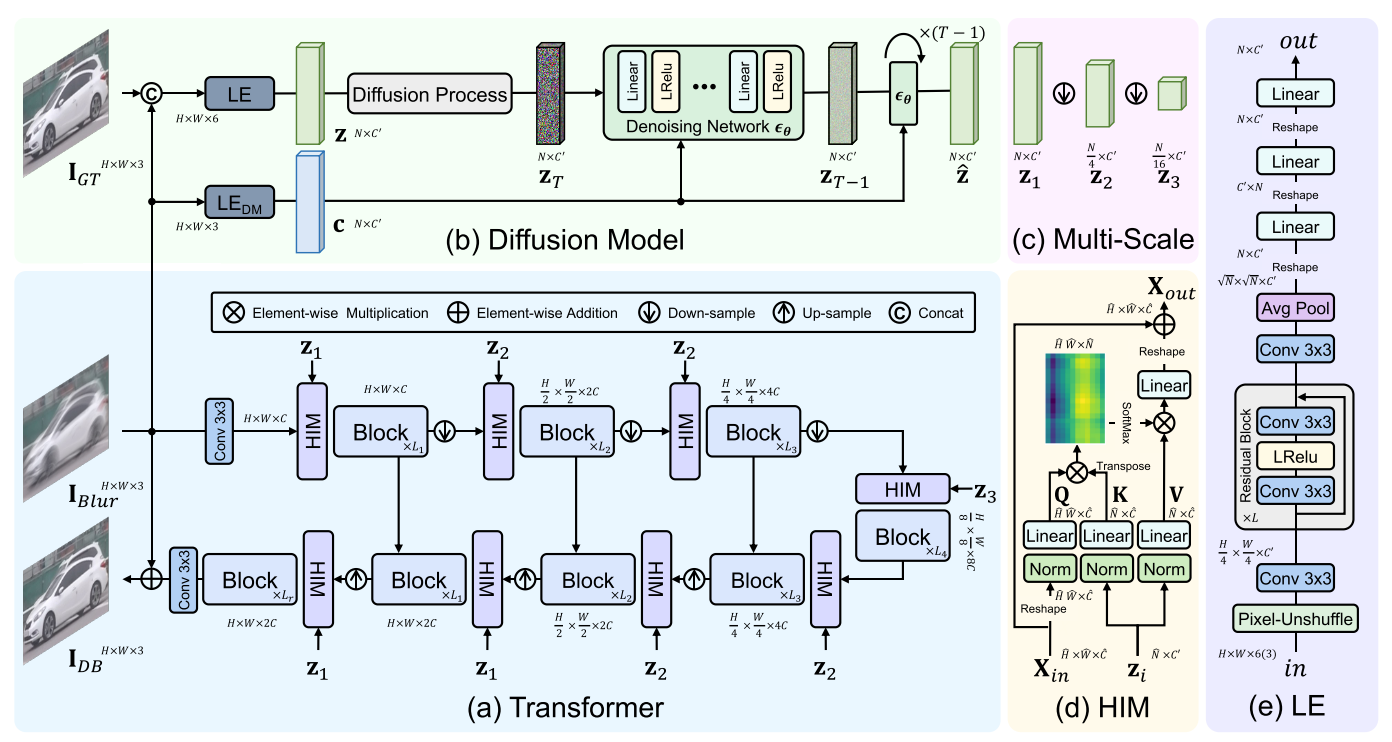
采用 Diffusion 作为 Restormer 的先验知识模型,用来指导训练,从而提升去模糊效果.
3. 重点问题
3.1 训练与推理
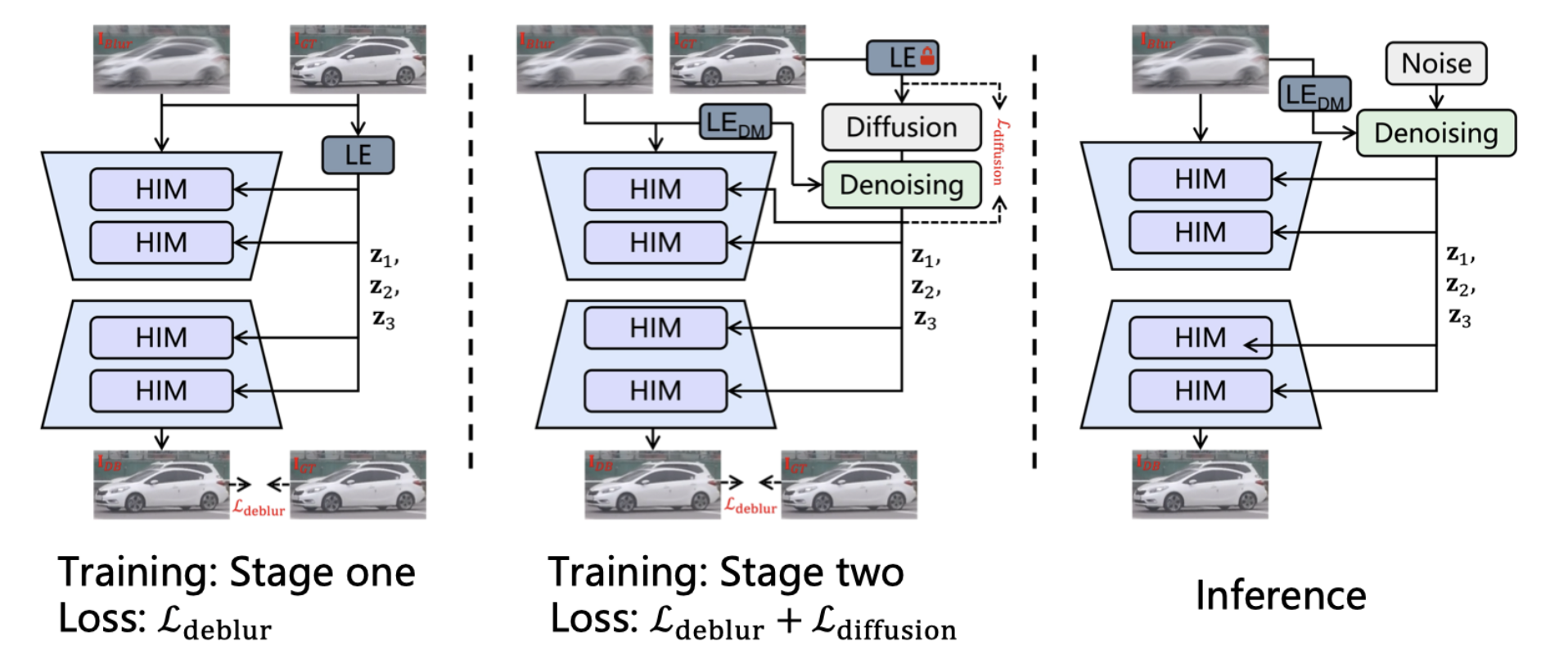
第一阶段: 将真实图像压缩为 Transformer 的先验特征,此阶段训练 Transformer 和 LE 进行特征压缩。
第二阶段:训练潜在扩散模型生成无需真实图像的先验特征,同时联合训练 Transformer 和扩散模型以提升性能。
推理过程:首先通过 LE 将输入的模糊图像压缩成条件潜在表示。其次通过条件化的扩散模型生成先验特征。最后利用 Transformer 在先验特征的指导下重构去模糊图像。
3.2 几点疑惑和解答
为什么要采用两阶段训练? 而不是直接进行第二阶段的训练?
答: 阶段一的主要目的是得到 LE 的参数,为了让像素空间映射到一个固定的 latent space. 如果在第二阶段中, 没有固定 LE 的参数,那么训练的时候就会不断地变换 latent space, 那么 Diffusion 的加噪就失去了意义.
为什么要用 DM 作为先验知识模型,不用不可以吗, 直接将 gt 当作多尺寸的先验知识.
答: 在训练阶段一确实是这么做的,直接对 gt 进行 LE 转换后下采样为 z1,z2,z3; 在阶段二也是将 gt 经过 DM 的输出当作先验知识. 但是我们在推理阶段是看不到 gt 的,因此需要从输入和随机噪声中得到先验知识, 这样就用上了阶段二训练的 denose network.
联合训练的目的是?为什么二阶段不只训练 denose network ?
答: Because there is slight deviation between the predicted prior feature and the actual prior z. 直观上理解就是先验知识改变了, Transformer 参数也适当的调整一下会得到更好的效果.
为什么 DM 学到的东西可以作为先验知识?
答: 这篇文章中 Denoise network 可以从模糊的照片和一个随机的噪声中还原出 Gt 干净图像, 这就表明了它能够学到一些语义信息.


















 2481
2481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









