









 本文详细介绍了ShardingJdbc2.x中SQL执行后的结果合并过程,涉及execute、executeUpdate和executeQuery三种方法的不同处理,重点解析了ShardingResultSet对象的生成,包括MergeEngine的merge方法、ResultSetMerger的实现(如Stream、Memory和Decorator)以及limit关键字的处理。最后,概述了结果集解析和字段值转换的步骤。
本文详细介绍了ShardingJdbc2.x中SQL执行后的结果合并过程,涉及execute、executeUpdate和executeQuery三种方法的不同处理,重点解析了ShardingResultSet对象的生成,包括MergeEngine的merge方法、ResultSetMerger的实现(如Stream、Memory和Decorator)以及limit关键字的处理。最后,概述了结果集解析和字段值转换的步骤。
从前面几篇文章,我们了解了从SQ解析---》SQL路由--》SQL改写--》SQL执行的整体过程。这一篇主要是讲解执行的结果如何变成正规结果相应到调用方的。
这里不同的执行方法处理的方式( execute , executeUpdate , executeQuery )也是不一样的
1.execute 方法返回的是 boolean 类型,处理比较简单
public boolean execute() throws SQLException {
List<Boolean> result = executorEngine.executePreparedStatement(sqlType, preparedStatementUnits, parameters, new ExecuteCallback<Boolean>() {
@Override
public Boolean execute(final BaseStatementUnit baseStatementUnit) throws Exception {
return ((PreparedStatement) baseStatementUnit.getStatement()).execute();
}
});
if (null == result || result.isEmpty() || null == result.get(0)) {
return false;
}
return result.get(0);
}
2.executeUpdate 方法,返回的是int类型,执行成功的条数,这里计算也是比较简单的
public int executeUpdate() throws SQLException {
List<Integer> results = executorEngine.executePreparedStatement(sqlType, preparedStatementUnits, parameters, new ExecuteCallback<Integer>() {
@Override
public Integer execute(final BaseStatementUnit baseStatementUnit) throws Exception {
return ((PreparedStatement) baseStatementUnit.getStatement()).executeUpdate();
}
});
return accumulate(results);
}
private int accumulate(final List<Integer> results) {
int result = 0;
for (Integer each : results) {
result += null == each ? 0 : each;
}
return result;
}
3.executeQuery 方法是查询方法,这里做了一些复杂的计算
@Override
public ResultSet executeQuery() throws SQLException {
ResultSet result;
try {
Collection<PreparedStatementUnit> preparedStatementUnits = route();
List<ResultSet> resultSets = new PreparedStatementExecutor(
getConnection().getShardingContext().getExecutorEngine(), routeResult.getSqlStatement().getType(), preparedStatementUnits, getParameters()).executeQuery();
① result = new ShardingResultSet(resultSets, new MergeEngine(resultSets, (SelectStatement) routeResult.getSqlStatement()).merge(), this);
} finally {
clearBatch();
}
currentResultSet = result;
return result;
}
这里在SQL执行完成之后进行了①的操作,主要是返回了ShardingResultSet对象,在这里我们看到调用了MergeEngine的merge方法对结果集进行合并操作。
public ResultSetMerger merge() throws SQLException {
① selectStatement.setIndexForItems(columnLabelIndexMap);
return ③ decorate(② build());
}
第一步.处理一些函数和groupby,orderby等关键词的字段
public void setIndexForItems(final Map<String, Integer> columnLabelIndexMap) {
setIndexForAggregationItem(columnLabelIndexMap);
setIndexForOrderItem(columnLabelIndexMap, orderByItems);
setIndexForOrderItem(columnLabelIndexMap, groupByItems);
}
第二步.创建合并的操作类: ResultSetMerger
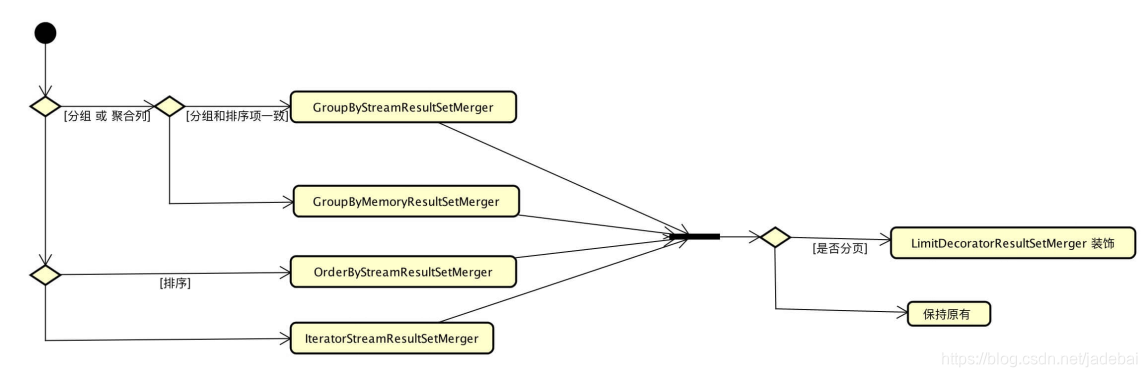
private ResultSetMerger build() throws SQLException {
if (!selectStatement.getGroupByItems().isEmpty() || !selectStatement.getAggregationSelectItems().isEmpty()) {
if (selectStatement.isSameGroupByAndOrderByItems()) {
return new GroupByStreamResultSetMerger(columnLabelIndexMap, resultSets, selectStatement);
} else {
return new GroupByMemoryResultSetMerger(columnLabelIndexMap, resultSets, selectStatement);
}
}
if (!selectStatement.getOrderByItems().isEmpty()) {
return new OrderByStreamResultSetMerger(resultSets, selectStatement.getOrderByItems());
}
return new IteratorStreamResultSetMerger(resultSets);
}
看一下获取ResultSetMerger的流程图
我们看一下ResultSetMerger的实现类图
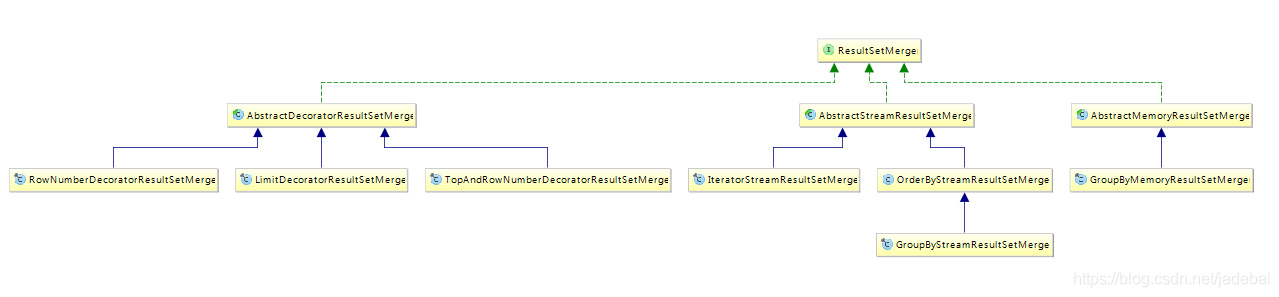
1.Stream 流式:AbstractStreamResultSetMerger :将数据游标与结果集的游标保持一致,顺序的从结果集中一条条的获取正确的数据
2.Memory 内存:AbstractMemoryResultSetMerger:需要将结果集的所有数据都遍历并存储在内存中,再通过内存归并后,将内存中的数据伪装成结果集返回
3.Decorator 装饰者:AbstractDecoratorResultSetMerger:可以和前二者任意组合
第三步.如果有limit关键字,需要组装一下ResultSetMerger,不同的数据库,处理方式不同
private ResultSetMerger decorate(final ResultSetMerger resultSetMerger) throws SQLException {
Limit limit = selectStatement.getLimit();
if (null == limit) {
return resultSetMerger;
}
if (DatabaseType.MySQL == limit.getDatabaseType() || DatabaseType.PostgreSQL == limit.getDatabaseType() || DatabaseType.H2 == limit.getDatabaseType()) {
return new LimitDecoratorResultSetMerger(resultSetMerger, selectStatement.getLimit());
}
if (DatabaseType.Oracle == limit.getDatabaseType()) {
return new RowNumberDecoratorResultSetMerger(resultSetMerger, selectStatement.getLimit());
}
if (DatabaseType.SQLServer == limit.getDatabaseType()) {
return new TopAndRowNumberDecoratorResultSetMerger(resultSetMerger, selectStatement.getLimit());
}
return resultSetMerger;
}
到这里就返回了我们需要的ResultSet ,即ShardingResultSet对象。
接下来就是解析ResultSet对象,映射结果集给到调用方了
在mybatis中就走到了 resultSetHandler.<E> handleResultSets(ps);
然后在获取返回的字段值的时候 rowValue = getRowValue(rsw, discriminatedResultMap, rowKey, null, partialObject);
rowValue = createResultObject(rsw, resultMap, lazyLoader, columnPrefix);这里的rsw=ShardingResultSet
最终会走到 ShardingResultSet的字段处理方法
ResultSetUtil.convertValue(mergeResultSet.getValue(columnLabel, String.class), String.class);
可以看到这里通过ResultSetUtil的convertValue方法对字段的值(通过ResultSetMerger 的getValue获取)进行转换处理。
public static Object convertValue(final Object value, final Class<?> convertType) {
if (null == value) {
return convertNullValue(convertType);
}
if (value.getClass() == convertType) {
return value;
}
if (value instanceof Number) {
return convertNumberValue(value, convertType);
}
if (value instanceof Date) {
return convertDateValue(value, convertType);
}
if (String.class.equals(convertType)) {
return value.toString();
} else {
return value;
}
}
到这里,sharding-jdbc的系列介绍就结束了
我们了解了整体从SQ解析---》SQL路由--》SQL改写--》SQL执行--》SQL结果合并 的整体过程。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









