




 本文深入探讨了YOLO目标检测算法,对比RCNN系列,YOLO实现了端到端的一次性检测,大大提升了检测速度。文章详细解释了YOLO如何通过单一网络预测物体位置和类别,以及其独特的损失函数设计。
本文深入探讨了YOLO目标检测算法,对比RCNN系列,YOLO实现了端到端的一次性检测,大大提升了检测速度。文章详细解释了YOLO如何通过单一网络预测物体位置和类别,以及其独特的损失函数设计。
人类在观察一张图像时,对于图像中的物体通常可以秒辨认并定位,完全不用太多的思考。因此目标检测的要求不仅要准,而且要快。而在YOLO出现之前,RCNN系列是目标检测中最精准的算法,虽然faster rcnn比最初始的RCNN快了很多,但其速度也只有7fps。究其原因是RCNN系列将 Proposal 的选取和选定 Proposal 后的分类和回归分作两个stage,就算用 RPN 网络取代 selective search,仍然是两个stage,因此导致了检测的缓慢。
YOLO算是one stage的开山之作,虽然精度不及当时的Faster RCNN,但他的检测速度达到Faster RCNN的6-7倍,此外还有更小更快的网络 Fast YOLO,速度更是达到了Faster RCNN 的22倍。而精度方面,YOLO 的 mAP 虽不及 Faster RCNN,但相差的可以接受。
one stage意味着候选框的选定,分类和回归都是在一个CNN中,实现了端到端的训练。
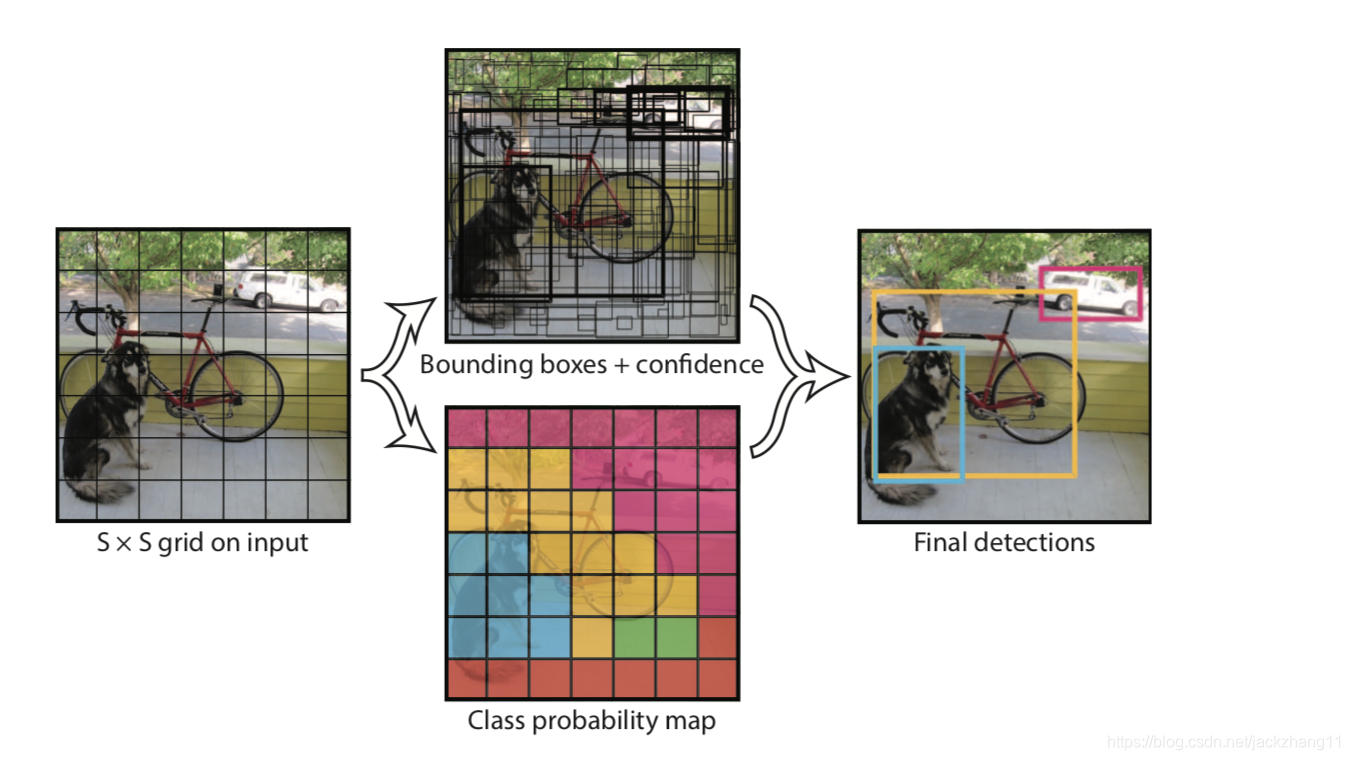
如上图所示,YOLO将一张自然图像分割为7*7的grid cell,每一个grid负责预测两个bounding box,每一个bounding box对应五个值:x, y, w, h和置信度。其中 (x, y) 表示bounding box 的坐标中心相对于所处的grid cell的左上角的偏置; (w, h)表示候选框的长和宽与整个图像长和宽的比值,这样坐标和长宽四个参数都可以做到归一化(归一化的目的是为了防止计算loss时数值较大的参数产生的梯度覆盖掉较小参数的影响);置信度表示该bbox中包含目标物体的信任度,可以用 Pr(Object)∗IOUpredtruthPr(Object)*IOU_{pred}^{truth}Pr(Object)∗IOUpredtruth 来计算,第一项表示bbox中包含物体的可能性,如果候选框中没有任何物体,那么他的值为0,整个置信度也为0;如果有物体,那么置信度就和bbox和GT的IOU相等。
一个grid cell除了预测两个bbox,还需要预测这里面包含的物体类别,原文中采用PASCAL VOC数据集,因此总共20个类别。值得注意的是,一个grid cell只做一次类别预测,尽管里面有两个bbox,但相当于这两个bbox预测某一类物体,这里其实也是YOLO的一个不足之处。这里可能会疑惑,既然预测同一类物体,为何要用两个box,一个不就够了吗?我的想法是,这相当于让两个人去做同一项任务,这两个之间必然有一个做的更好,用在这里应该也是一样的,在两个框中取IOU或置信度更高的那个。
此外还有一个 20 维的类别向量。训练阶段只需要判断物体的中心是否在box中,如果在的话给这一维度的值打上 1 的标签即可;而在测试阶段,需要在这个预测值的基础上乘置信度,对应论文中的 Pr(Classi∣Object)Pr(Object)∗IOUpredtruthPr(Class_{i}|Object)Pr(Object)*IOU_{pred}^{truth}Pr(Classi∣Object)Pr(Object)∗IOUpredtruth,前一项是预测的每个类别的概率,后两项乘积为置信度,这是为了防止Pr(Classi∣Object)Pr(Class_{i}|Object)Pr(Classi∣Object)很大,而置信度接近 0 的情况,这种情况也不能认定bbox中有那个预测概率很大的物体。
因此整个网络的输出为7∗7∗(2∗5+20)=7∗7∗307*7*(2*5+20)=7*7*307∗7∗(2∗5+20)=7∗7∗30。网络的模型结构如下:
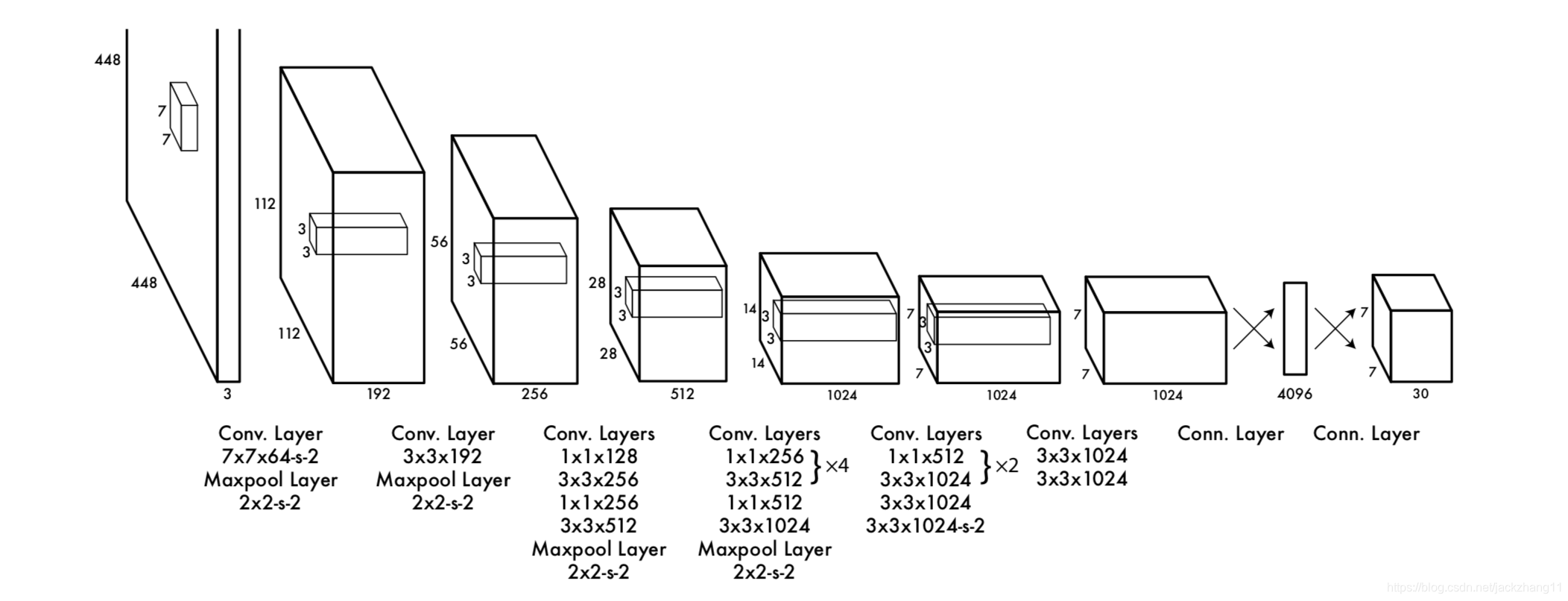
网络模型受到GoogleNet启发,不过并没有用Inception模块,而是用1∗11*11∗1后接3∗33*33∗3卷积的操作以减少模型参数,最后一层采用线性激活函数,其他层采用Leaky Relu。
模型输入为448∗448448*448448∗448的三通道图像,经历了若干卷积池化层以后,得到的输出为7∗7∗307*7*307∗7∗30的向量,与上文相对应。
整个模型训练时的损失函数如下:
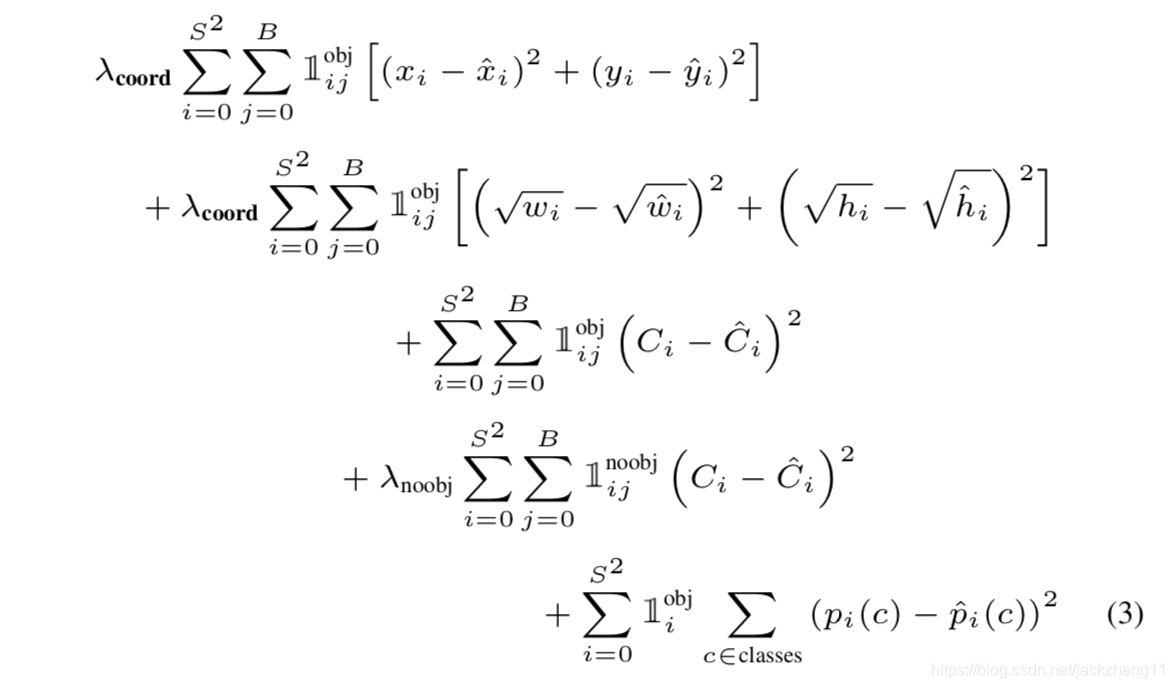
其中λcoord\lambda_{coord}λcoord和λnoobj\lambda_{noobj}λnoobj是为了平衡数量级用的调节参数,如果不加这个参数,可能导致有些项的数值和梯度太大,覆盖了其他较小项的影响;1ijobj1_{ij}^{obj}1ijobj表示的是第i个cell的第j个bbox包不包括物体,如果包括则该值为1,需要考虑坐标、置信度和类别的因素;如果不包括,则该值为0,而1ijnoobj1_{ij}^{noobj}1ijnoobj为1,这时只需要考虑第四行的置信度项即可。
还有一点是为什么这里的w和h都带根号?这是因为对于较大的框,些许的坐标误差影响不是太大;而较小的框更加敏感,些许的误差带来的影响可能会比较大。我的理解是,加上根号相当于自身是一个二阶导不断减小的增函数,因此在w和h较大的部分的平均变化率要更小。举个例子现在有两个预测box对应的的w1,w2w_{1},w_{2}w1,w2,其中w1<w2w_{1}<w_{2}w1<w2,所以第一个box的敏感程度更高,假设这两个box都对应一个GT,GT的宽度表示为w(w刚好等于二分之一的w1+w2w_{1}+w_{2}w1+w2),那此时∣w1−w∣|\sqrt w_{1}-\sqrt w|∣w1−w∣比∣w2−w∣|\sqrt w_{2}-\sqrt w|∣w2−w∣更大,loss惩罚在小候选框上更加严厉。
我们发现,损失函数的每一项都是L2 Loss,并且对于分类问题也是如此,因此YOLO将分类问题转化为了回归问题。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









