







 本文介绍了Scala的基本概念,包括变量定义、函数特性、柯里化、匿名函数等,并详细讲解了Scala集合的操作方法,如List的拼接、filter过滤、reduce规约等。
本文介绍了Scala的基本概念,包括变量定义、函数特性、柯里化、匿名函数等,并详细讲解了Scala集合的操作方法,如List的拼接、filter过滤、reduce规约等。
变量定义
scala变量定义有三种方式,分别是:
1、val:定义常量;
2、var:定义变量;
3、lazy val:惰性变量;
scala> var a=100
a: Int = 100
scala> var b=10
b: Int = 10
scala> lazy val c=a+b
c: Int = <lazy>
scala> c
res0: Int = 110
当执行完 lazy val c=a+b 后,c 没有被立马求值,而是当其被使用的时候,才计算其值。
scala中的函数
scala中的函数可以:
1、把函数作为实参传递给另一个函数;
2、把函数作为返回值;
3、把函数赋值给变量(匿名函数一般就是这种方式);
4、把函数存储在数据结构中;
5、scala的函数中经常会遇到"_",下划线表示通配所有类型。
求值策略:
1、call by value:无论是否使用都会求值;
2、call by name:只有在使用时才会求值;
实例网上有很多:https://blog.youkuaiyun.com/bluejoe2000/article/details/43966723。都是用的死循环的例子,很重要的一点就是call by name在不使用的时候是不会计算的,所以当死循环函数不使用时,是不会触发的。
柯里化
个人理解就是类似原子函数
// 柯里化函数的写法,就是将函数的每个参数都单独出来
def curry_add(a: Int)(b: Int): Int = {
a + b
}
// 后面的“_”,是匹配除了第一个参数后的所有参数
val addOne = curry_add(1)_ // 1就是匹配参数a
addOne(2) // 结果:3 // 2匹配参数b
匿名函数
可以在函数体内定义匿名函数,用于计算
匿名函数的定义格式:(形参列表)=>{函数体}
object Test {
def main(args:Array[String]) {
var mul = (x: Int, y: Int) => x*y
println(mul(3, 4))
}
}
scala中的集合
List
1、List拼接
// :: 操作符
var a = List(1, 2, 3, 4, 5)
println(0 :: a) //将x拼接到列表a的前面
// 打印: List(0, 1, 2, 3, 4, 5)
2、List的常用操作
var list = List(1, 2, 3, 4, 5)
println(list.head) // 获取第一个元素
println(list.tail) // 返回除了第一个元素的List
3、reduceLeft规约函数
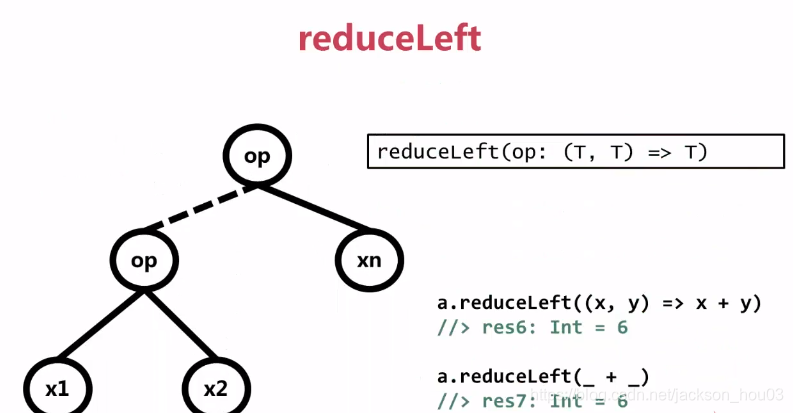
4、foldLeft(有初始值的规约)
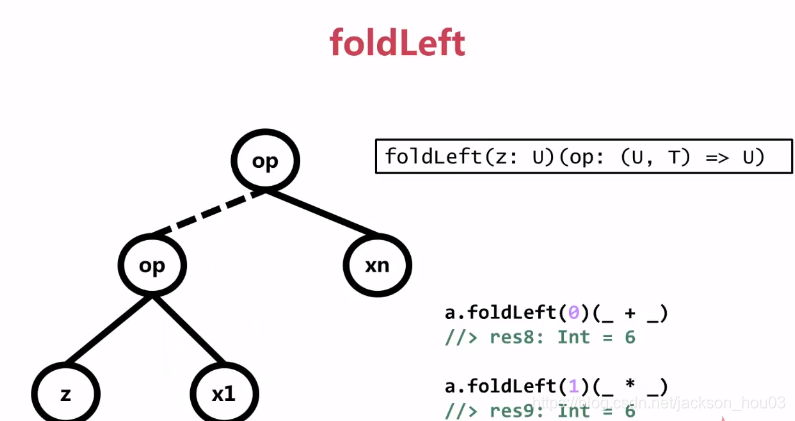
注意对比reduceLeft和foldLeft的返回类型,reduceLeft的返回类型和元素类型已知;而foldLeft首先是一个柯里化函数,其次它的返回值跟第一个参数z一致。
reduce和fold函数对比
def main(args: Array[String]): Unit = {
var l = List(1, 2, 3, 4, 5, 6, 7, 8)
// l = l.map(x => x + 1)
// println(l)
var result = l.reduce(_ + _)
println(result)
// 从左向右减
result = l.reduce(_ - _)
println(result)
// 从左向右减
result = l.reduceLeft(_ - _)
println(s"reduceLeft: $result")
// 从右边开始,前一个减去后面的结果:1-(2-(3-(4-(5-(6-(7-8))))))
result = l.reduceRight(_ - _)
println(s"reduceRight: $result")
// 从右边开始,前一个减去后面的结果:1-(2-(3-(4-(5-(6-(7-(8-0)))))))
// fold和reduce的区别就是有没有初始值
result = l.foldRight(0)(_ - _)
println(s"foldRight: $result")
}
5、filter
var list = List(1, 2, 3, 4, 5)
println(list.filter(x => x % 2 == 0)) // 通过参数中的匿名函数进行过滤
6、takeWhile
val names = List("spark", "hadoop", "kafka", "hive", "mesos", "zero", "xyz", "marathon")
//需求:将names容器中,获取/过滤出元素长度为4的元素,
//takeWhile, 从第一个元素开始判断,满足条件,就留下,直到遇到第一个不满足的条件的元素,就结束循环
//可见,takeWhile 有可能并不是对所有的元素进行操作的
names.takeWhile(_.length > 4).foreach { x => print(x + " ") }
// 打印输出 spark hadoop kafka
7、map(参数为列表的每个元素)
val arr2 = Array(1,2,3,4,5,6)
arr2.map(_ * 10) //参数为匿名函数
for(i <- arr2)
println(i)
8、flatMap(将二维List转成一维List)
val list1 = List("I love", "coding scala") // 原来是什么类型的集合,调用flatMap后就返回什么类型的集合
val rs_list = list1.flatMap(x => x.split(" ")) // 返回新的集合
rs_list.foreach(x => println(x))
/*打印:
I
love
coding
scala
*/
Rang
1 to 10 // 定义Rang(1,2,3,4,5,6,7,8,9,10)
1 to 10 by 2 // 定义步长为2的Rang(1,3,5,7,9)
1 until 10 // 定义小于10的Rang(1,2,3,4,5,6,7,8,9)
Stream
Stream is lazy list
val stream = (1 to 10000).toStream
println(stream)
/*打印:
Stream(1, ?) // 用到的时候才会求值
*/
Tuple
val t = (1, "Alice", "Math", 95)
println(t)
println(t._1)
println(t._2)
/*打印:
(1,Alice,Math,95)
1
Alice
*/
Map
val map = Map("1" -> "jackson", "2" -> "suson")
println(map.keys)
println(map.values)
val map2 = map + ("3" -> "lucky")
println(map2)
val map3 = map2 - "2"
println(map3)
val map4 = map ++ List("3" -> "jackson1", "4" -> "suson1")
println(map4)
val map5 = map4 -- List("1", "2")
println(map5)
/*打印:
Set(1, 2)
MapLike.DefaultValuesIterable(jackson, suson)
Map(1 -> jackson, 2 -> suson, 3 -> lucky)
Map(1 -> jackson, 3 -> lucky)
Map(1 -> jackson, 2 -> suson, 3 -> jackson1, 4 -> suson1)
Map(3 -> jackson1, 4 -> suson1)
*/
最近因为在看Spark的相关知识,所以先简单入门了下scala。文档只是个人的学习理解。因为是初学,所以错误在所难免,还请各位看官斧正…后续有新的理解也会持续更新。

















 3496
3496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









