



 本文详细介绍了在CentOS7系统中部署Hadoop2.7.5分布式集群的具体步骤,包括创建文件目录、配置环境变量、修改配置文件等关键环节,以及启动和验证集群的方法。
本文详细介绍了在CentOS7系统中部署Hadoop2.7.5分布式集群的具体步骤,包括创建文件目录、配置环境变量、修改配置文件等关键环节,以及启动和验证集群的方法。
CentOS7下Hadoop2.7.5分布式集群部署(四)最终部署
-
创建新的文件目录
(1)打开一个新终端#su root 输入密码登录
(2)进入目录,#cd /usr/local/hadoop
(3)创建dfs、tmp两个文件夹,#mkdir -p dfs tmp
(4)进入dfs目录,#cd dfs
(5)创建name、data两个文件夹爱,#mkdir -p name data
(6)授权
#chown -R hadoop:hadoop /usr/local/hadoop/dfs/name
#chown -R hadoop:hadoop /usr/local/hadoop/dfs/data -
配置hadoop-env.sh
(1)[root@master local]# cd /usr/local/hadoop/hadoop-2.7.5/etc/hadoop
(2)[root@master hadoop]#vim hadoop-env.sh
(3)在末尾添加
export JAVA_HOME=/usr/local/java/jdk1.8.0_231
- 配置core-site.xml
#vim /usr/local/hadoop/hadoop2.7.5/etc/hadoop/core-site.xml
(路径是这个)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
- 配置hdfs-site.xml
#vim /usr/local/hadoop/hadoop2.7.5/etc/hadoop/hadoop-env.sh
<configuration>
<!-- 设置namenode的http通讯地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<!-- hdfs副本的数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- nameNode数据目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/dfs/name</value>
</property>
<!-- dataNode数据目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/dfs/data</value>
</property>
</configuration>- 修改yarn-site.xml
#vim yarn-site.xml
<configuration>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- reducer取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
- 配置mapred-site.xml
#cp mapred-site.xml.template mapred-site.xml
#vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name> <value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value>
</property>
</configuration>
- 配置slaves
(1)#su root,输入密码登录
(2)[root@master hadoop]# vim slaves
slave1
slave2 - 关闭防火墙
(1) #su root 输入密码登录
(2)#systemctl disable firewalld每台机器都重复该步骤 - 永久关闭selinux
(1)#su root 输入密码登录
(2)#vim /etc/selinux/config
修改SELINUX=disable每台机器都重复该步骤 - 启动HADOOP集群
(1)#su root,输入密码进行登录
(2)#sudo chown -R hadoop /usr/local/hadoop(每台都要授权)
(以下只在master下执行)
(3)hadoop用户下进行[root@master hadoop]# su - hadoop[hadoop@master hadoop]$ hdfs namenode -format
一定要在第一次启动要执行格式化,之后启动不用执行这个
(4)授权#sudo chown -R hadoop /usr/local/hadoop/hadoop-2.7.5进入到sbin路径下
(5)#start-dfs.sh
(6)#start-yarn.sh
(7)#mr-jobhistory-daemon.sh start historyserver - 验证
(1)#su - hadoop
(2)#jps
master
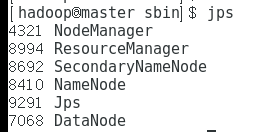
slave1
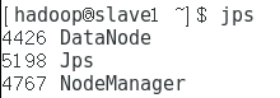 slave2
slave2
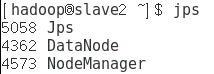
注意:多次格式化后,需将dfs和tmp文件删除再创建,再格式化
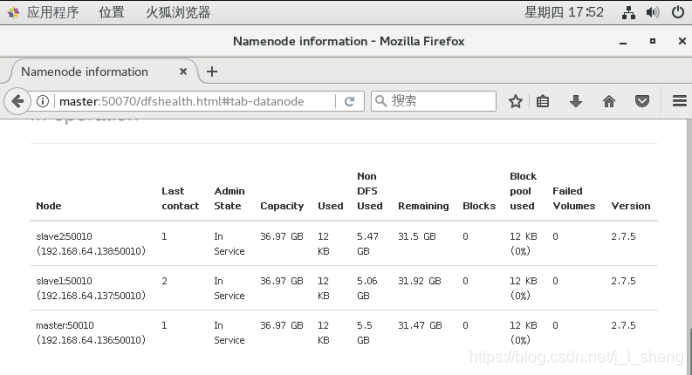
(3)打开浏览器,输入http://master:50070
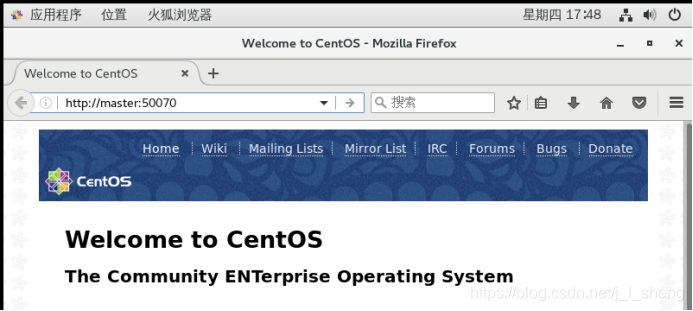 结果如下:
结果如下:
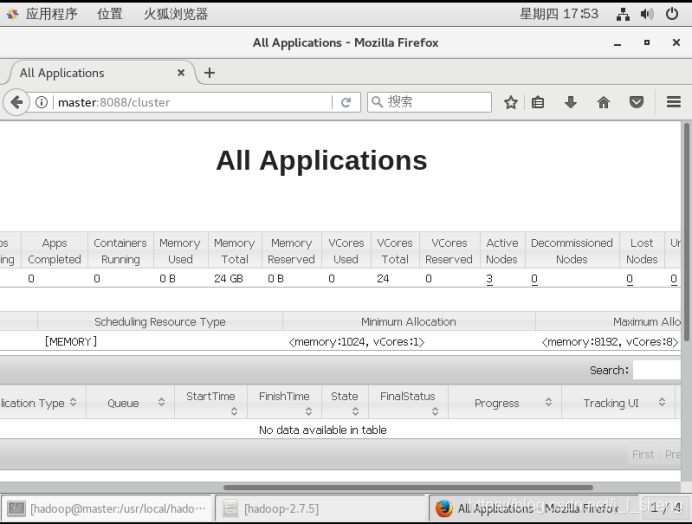
(4)再次输入master:8080/cluster

















 2112
2112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









