



在机器学习中,常常遇到过拟合的现象。这时,选择各种模型的参数就显得十分重要。如何选择最合适的参数呢?
sklearn中提供了一些cross-validation的方法,下面来逐一介绍。
cross_val_score
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
#得到花的数据集,其中有四个特征,一个标签
iris = load_iris()
X = iris.data
y = iris.target
#使用cross_val_score中的'accuracy'方法,对模型进行打分
from sklearn.model_selection import cross_val_score
knn = KNeighborsClassifier(n_neighbors=5)
scores = cross_val_score(knn, X, y, cv=5, scoring='accuracy')#分五组
print(scores)#每组都有相应的分数
#利用cross_val_score找到最佳参数,并用matplotlib可视化
import matplotlib.pyplot as plt
k_range = range(1, 31)
k_scores = []
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
#loss = -cross_val_score(knn, X, y, cv=10, scoring='neg_mean_squared_error') #对于回归问题可以使用这个打分方法
scores = cross_val_score(knn, X, y, cv=20, scoring='accuracy') #对于分类问题可以使用这个打分方法
k_scores.append(scores.mean())#每组分数求平均
plt.plot(k_range, k_scores)
plt.xlabel('Value of K for KNN')
plt.ylabel('Cross-Validated Accuracy')
plt.show()
对于KNN算法来说,选择模型参数n_neighbors对结果有较大影响。
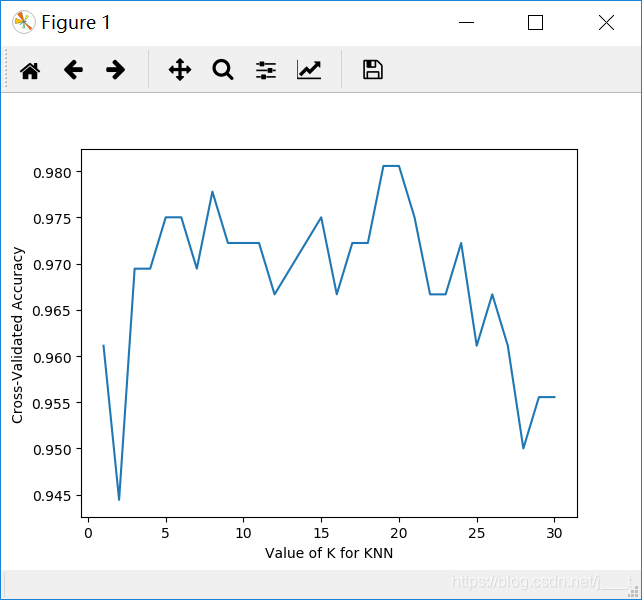
从图中我们可以看出,当n_neighbors选择为20左右时,针对iris数据集的训练效果是最好的。
learning_curve
from sklearn.model_selection import learning_curve
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
#得到数图像的训练集,每一个图像有64个特征,一个标签
digits = load_digits()
X = digits.data
y = digits.target
print(X.shape, y.shape)
#learning_curve函数返回三个narray,分别是训练集大小,训练集上的误差和测试集上的误差
#打分方法选择neg_mean_squared_error
#可以提供训练数据集大小的列表,来测试当训练集变多,会不会出现过拟合现象。
#如果出现过拟合现象,模型在训练集规模变大的情况下,正确率会变低,loss会变大
train_sizes, train_loss, test_loss= learning_curve(
SVC(gamma=0.01), X, y, cv=5, scoring='neg_mean_squared_error',
train_sizes=[0.1, 0.25, 0.5, 0.75, 1])
#对于每一种训练规模,都会有一组长度为5的列表(因为cv=5)来表示loss
#对于每一组loss,取其平均代表最终loss
#由于是每一组loss要求平均,所以需要axis=1,axis=1表示行内求平均
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
plt.plot(train_sizes, train_loss_mean, 'o-', color="r",
label="Training")
plt.plot(train_sizes, test_loss_mean, 'o-', color="g",
label="Cross-validation")
print(train_sizes, type(train_sizes))
plt.xlabel("Training examples")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()
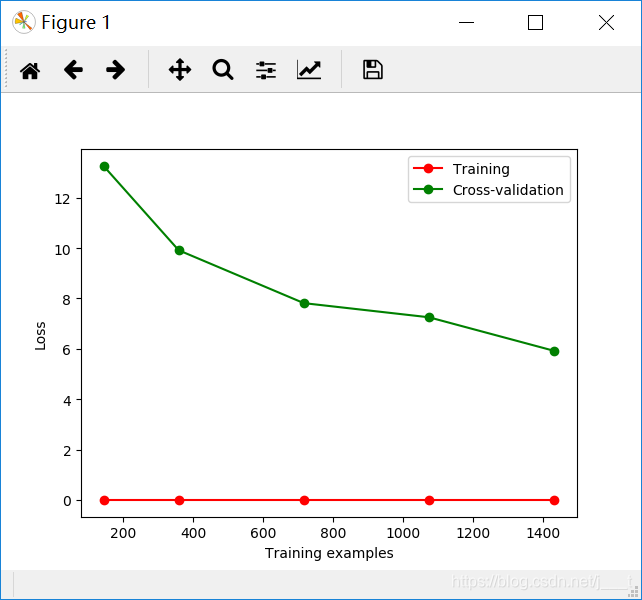
从图像中可以看到,测试集的loss逐步减小,模型拟合的较为合适,参数选择对于这个数据集没有问题。
validation_curve
from sklearn.model_selection import validation_curve
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
data = load_digits()
X = data.data
Y = data.target
#创建个数为5的等比数列
param_range = np.logspace(-6, -2.3, 5)
train_loss, test_loss = validation_curve(
SVC(), X, Y, param_name='gamma', param_range = param_range,
cv = 10, scoring = 'neg_mean_squared_error'
)
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1)
plt.plot(param_range, train_loss_mean, 'o-', color = 'r',
label = 'training')
plt.plot(param_range, test_loss_mean, 'o-', color = 'g',
label = 'test')
plt.xlabel('gamma')
plt.ylabel('loss')
plt.legend(loc='best')
plt.show()
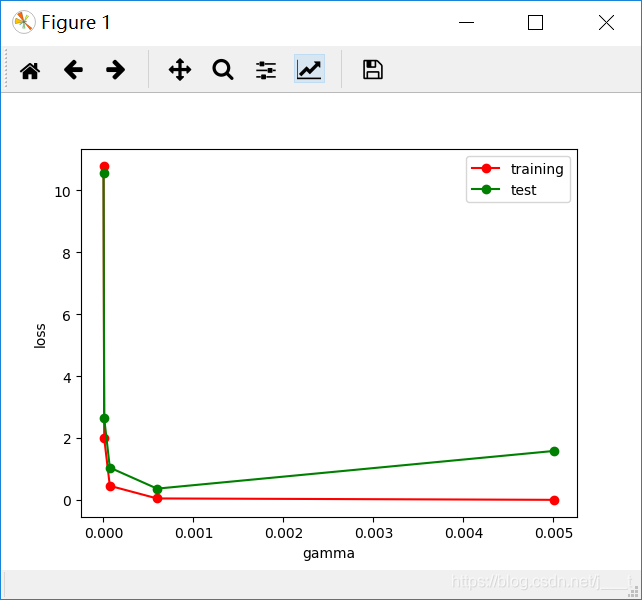
右图中可以看出,模型参数gamma选择0.005左右时最佳,再大就会出现过拟合现象
总结
三个方法都是针对一个模型和数据集进行打分,返回打分结果
其中cross_val_score函数最弱,只有最基本的交叉验证功能。learning_curve函数可以传入一个代表训练集占比的列表,validation_curve函数可以传入模型的参数列表。通过这三个函数,可以找到适合模型和数据集的参数,减小loss。


















 1039
1039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









