



 本文详细介绍Paddle深度学习框架的使用方法,包括环境搭建、数据预处理、模型构建、训练与预测等核心步骤,适合有一定深度学习基础的学习者。
本文详细介绍Paddle深度学习框架的使用方法,包括环境搭建、数据预处理、模型构建、训练与预测等核心步骤,适合有一定深度学习基础的学习者。
Paddle是百度的一个深度学习框架,所谓Paddle其实就是Parallel Distributed Deep Learning(并行分布式深度学习)的缩写,本文会从原理层面出发理解Paddle这种代码结构背后的东西。
本文要求你有基本的深度学习知识,对一些常见概念,不会细讲。
环境:MacOSPython:3.5.6 (Anaconda虚拟环境)PaddlePaddle:Fluid 1.1(pip直接安装)
数据预处理
训练模型前,对数据进行预处理是必要的,这样训练出来的模型才是具有泛化能力的,通常从3个方面进行数据预处理。
-
1.数据连续值与离散值的处理离散值通常转为对应的独热向量,如红绿灯数据集,其中0,1,2分别表示红灯、绿灯与黄灯,可以将红灯转为[1,0,0]
-
2.数值归一化训练数据数值的取值范围不同,比如年龄取值范围为[0~100],而对应财富的取值范围为[10000~1000000],那么不同大小的数值对模型权重的影响就会很不同,而且机器学习中很多ticks都是针对取值范围相似的数值进行的,比如L1、L2正则化。
-
3.切分训练集、测试集与验证集训练集用于训练,测试集用于验证模型在未知数据上的效果,通常测试误差越小,效果越好,测试集中的数据不能用于模型训练(作弊行为),通常一个模型具有多个超参数,可以使用多组不同的超参数定义模型然后训练,训练出的模型在验证集上验证效果,选择效果最好的模型的超参数。
Paddle五步走
任何框架构建模型的整体步骤都类似,只是对应的具体方法不同,这五步分别是:
-
1.构建数据读取器,可以读取Batch数据提供给训练器
-
2.构建网络结构,Paddle中常将网络结构定义成train_program()方法
-
3.定义训练器,等构建好事件监听器后
-
4.构建事件监听器,事件监听器是Paddle中的一个概念,通常的作用就是打印一下训练的结果
-
5.构建预测器,传入测试数据获得模型预测结果
上面的五步要在Paddle中实现其实很简单,Paddle都提供了相应的封装方法。
1.数据读取器
使用Paddle.batch()方法来获得一个数据读取器,该数据读取器可以读取对应的一组数据
-
train_reader = paddle.batch( -
paddle.reader.shuffle( -
paddle.dataset.uci_housing.train(), buf_size=500 -
), batch_size=BATCH_SIZE -
)
这里使用Paddle内部提供好了波士顿房价数据,每个数据有14个值,前13个是房子的各种数据,而最后一个就是房价,这里Paddle内部已经将数据分成了测试集以及训练集,同时也为我们做了归一化处理,但这种不透明的感觉不怎么好,如果要使用自己的数据集就会显得难以入手。所以简单来看一下Paddle内部是如何处理波士顿房价数据的。
先看paddle.dataset.ucihousing.train()方法,该方法逻辑如下,先调用loaddata去加载数据,然后定义reader()迭代器,并返回迭代器,交由paddle.reader.shuffle()处理。
-
def train(): -
global UCI_TRAIN_DATA -
load_data(paddle.dataset.common.download(URL, 'uci_housing', MD5)) -
-
def reader(): -
for d in UCI_TRAIN_DATA: -
yield d[:-1], d[-1:] -
-
return reader
其预处理的逻辑都在load_data()方法中,其代码如下,关键步骤我都标注了相应的注释
-
def load_data(filename, feature_num=14, ratio=0.8): -
global UCI_TRAIN_DATA, UCI_TEST_DATA -
if UCI_TRAIN_DATA is not None and UCI_TEST_DATA is not None: -
return -
# load data as Array from binary file -
data = np.fromfile(filename, sep=' ') -
# reshape the data Array -> [506, 14] -
data = data.reshape(data.shape[0] // feature_num, feature_num) -
# get the max nums and min nums from Array -
maximums, minimums, avgs = data.max(axis=0), data.min(axis=0), data.sum( -
axis=0) / data.shape[0] -
feature_range(maximums[:-1], minimums[:-1]) -
# data Normalized -
for i in six.moves.range(feature_num - 1): -
data[:, i] = (data[:, i] - avgs[i]) / (maximums[i] - minimums[i]) -
offset = int(data.shape[0] * ratio) -
UCI_TRAIN_DATA = data[:offset] -
UCI_TEST_DATA = data[offset:]
一开始,通过numpy的fromfile方法从文件中读取数据,该方法会读取文件中的数据并返回相应的数组,如图:

然后通过data.reshape()方法重塑数据的结构,波士顿房价数据14个元素为一组数据,所有重塑成宽为14的数据矩阵,如图:

接着通过numpy提供的max()、min()与sum()方法获得数据的最大值、最小值与均值
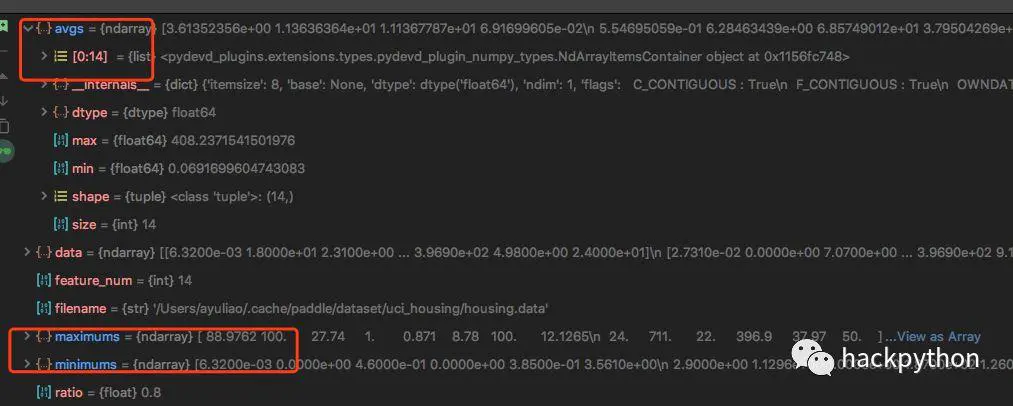
通过最大值、最小值与均值就可以对所有数据进行归一化操作,其中红框中最后一个值为24,表示房价,房价并没有进行归一化处理,还是原始的值,目标值是不能进行归一化操作的,需要注意
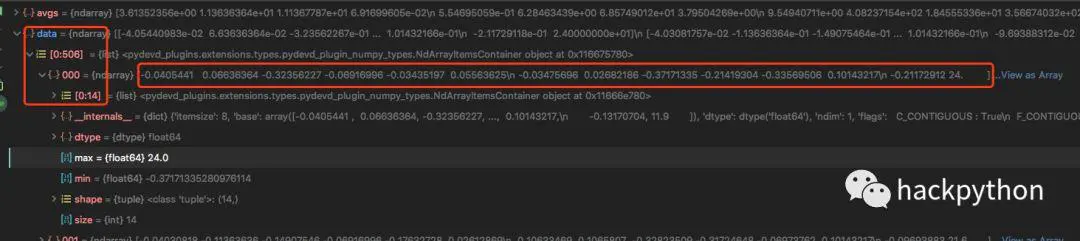
最后根据8:2比例将数据分为训练数据与测试数据。
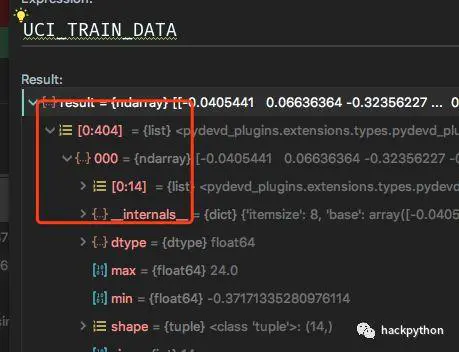
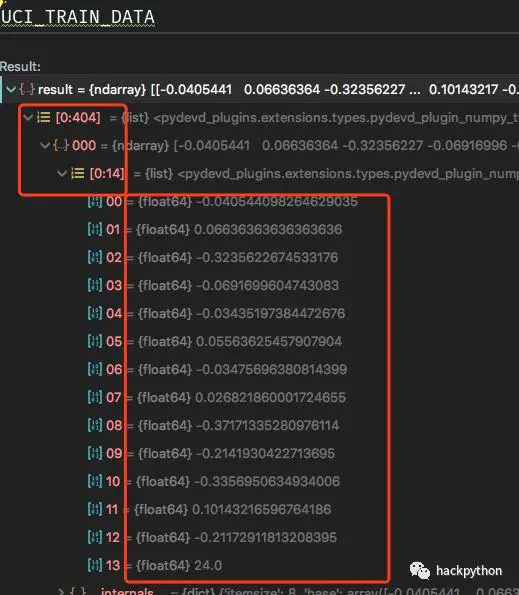
简单一下总体流程就是,读入数据为numpy的array对象,然后重塑成需要的形状,接着就是获得最大、最小值以及均值,通过这些值对数据进行归一化操作,将所有的数据取值范围都压缩到一个范围,然后就将处理好的数据分为训练集与测试集。并定义个reader()迭代器提供数据,提供是,将房子的属性数据与房子的价格数据分开提供,因为价格是我们模型要预测的数据,进行监督学习时的标准答案,所有分开提供。
最后,提供出现训练的数据其类型为float64,这个很重要,因为在定义网络结构的输入层时,需要定义对应的类型,不然数据在输入的过程中,会报错
2.构建网络结构
预测房价这里使用最简单的线性回归,公式如下:
$$ yi = w1x{i1} + w2x_{i2}... + b$$
使用单个全连接层处理则可,整个神经网络结构如下:
-
def train_program(): -
y = fluid.layers.data(name='y', shape=[1], dtype='float32') -
x = fluid.layers.data(name='x', shape=[13], dtype='float32') -
-
y_predict = fluid.layers.fc(input=x, size=1, act=None) -
-
loss = fluid.layers.square_error_cost(input=y_predict, label=y) -
avg_loss = fluid.layers.mean(loss) -
return avg_loss
Paddle使用fluid.layers.data()方法来定义输入层,可以同比TensorFlow中的placeholder,fluid.layers.data()方法参数名很直观,该方法会将输入的数据转成对应类型的Tensor,通过dtype参数指定输入数据类型,这里使用float32类型,经过试验发现,训练集的数据类型为float64,读入层的数据为float32不会报错。
Fluid目前支持的数据类型有:
-
float16: 部分操作支持
-
float32: 主要实数类型
-
float64: 次要实数类型,支持大部分操作
-
int32: 次要标签类型
-
int64: 主要标签类型
-
uint64: 次要标签类型
-
bool: 控制流数据类型
-
int16: 次要标签类型
-
uint8: 输入数据类型,可用于图像像素
通常,读入数据是什么类型,定义输入层时,dtype就填写什么类型。
然后通过fluid.layers.fc()方法获得全连接层,其中input参数传入上一层的输出,size表示本层节点的个数,act表示本全连接层使用的激活函数,因为要通过房子的属性预测房子的价格,而价格是单个的,所有全连接节点的个数size为1,输出房子的价格,这就是当前这个简单模型输出的预测价格,该价格要和真实的价格做比较,获得一个损失,通过不断的训练,减小该损失,这里通过fluid.layers.squareerrorcost()方法获得平方损失,paddle支持多种损失。
定义了网络结构与损失后,接着就可以定义优化器了,如下,这里使用SGD优化算法
-
def optimizer_program(): -
return fluid.optimizer.SGD(learning_rate=0.001)
3.定义训练器
实现了模型结构和要使用的优化算法后,就可以来定义一个训练器了,定义的方法非常简单,只需要将前面定义好的模型结构与优化算法对应的方法传入,代码如下:
-
# 定义使用CPU还是GPU -
use_cuda = False -
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace() -
-
# 创建训练器,传入模型结构train_program,代码运行的地方place以及优化方法optimizer_program -
trainer = Trainer( -
train_func=train_program, -
place=place, -
optimizer_func=optimizer_program -
)
在上述代码中,还需要定义代码执行的设备,即使用GPU还是CPU,以及有GPU使用第几块GPU,指定的这个设备会被用于训练代码。
这样训练器其实就定义完了。
4.定义事件监听器
训练器定义完后,其实还不可以直接进行,因为在Paddle中还需要定义事件监听器,简单而言就是监听查看训练过程中的数据变化,比如常用于打印每一次训练后损失的变化以及相应的输出,这里我们同样也来实现一个事件监听器,代码如下:
-
feed_order = ['x', 'y'] -
-
# 保存模型 -
params_dirname = 'fit_a_line.model' -
-
-
from paddle.utils import Ploter -
-
train_title = 'Tarin cose' -
test_title = 'Test cose' -
plot_cost = Ploter(train_title, test_title) -
-
step = 0 -
-
def event_handler_plot(event): -
global step -
if isinstance(event, EndStepEvent): -
if step % 10 == 0: -
print("%s, Step %d, Cost %f" % -
(train_title, step, event.metrics[0])) -
-
if step % 100 == 0: -
test_metrics = trainer.test( -
reader=test_reader, feed_order=feed_order -
) -
print("%s, Step %d, Cost %f" % (test_title, step, test_metrics[0])) -
-
if test_metrics[0] < 10.0: -
print('loss is less than 10.0, stop') -
trainer.stop() -
step += 1 -
-
if isinstance(event, EndEpochEvent): -
if event.epoch % 10 == 0: -
if params_dirname is not None: -
# 保存模型参数 -
trainer.save_params(params_dirname)
事件监听器的代码比较简单,其中一个重要的逻辑就是通过isinstance()方法判断当前的事件event是不是EndStepEvent类型,每一次训练结束都会产生EndStepEvent类型的对象,该对象包含这训练中获得的数据,此时就是可以从该对象中获取这些数据并打印形式处理,上述代码中,每10次就会输出训练时的损失,每100次就会使用测试数据来验证一次,判别该模型在测试数据上的损失,如果损失低于10,那么训练就结束了。
值得注意的是,使用测试数据进行测试使用了训练器的test()方法,并向其中传入了两个参数,其中reader参数输入的测试时要使用的数据,而feed_order参数输入的事测试数据读入使用时的顺序。
模型读入数据的顺序是很重要的,如何定义这个顺序?看两点。
第一点,理解传入模型的数据的情况,比如这里使用paddle.dataset.uci_housing.test()方法获得测试数据,其源码如下:
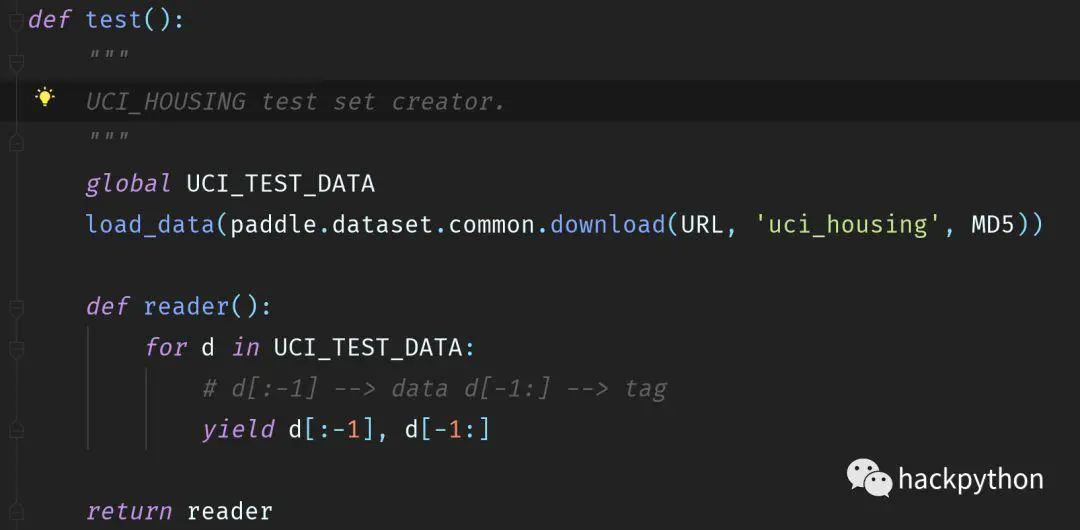
返回数据分成两部分,第一部分是具体的数据,即房子的各种数据数据,第二部分是房子的价格,而这两个部分对应着输入层,当前数据类型依旧值得再次强调,读入数据的数据类型要与对应输入层的数据类型相匹配。
第二点,理解模型结构中的数据读入层,除了要注意对应的数据类型,还要注意数据的形状以及该读入层的名称,这里数据读入层的代码如下:
-
def train_program(): -
y = fluid.layers.data(name='y', shape=[1], dtype='float32') -
x = fluid.layers.data(name='x', shape=[13], dtype='float32')
可以看出,名为y的数据输入层其形状为1,对应着输入数据的房子价格,而名为x的数据输入层其形状为13,对应着输入数据的房子属性。
结合这两点就可以看出,这里的输入数据顺序 feed_order=['x','y'],因为读入数据第一部分返回的是房间属性数据,应该交由名称为x的数据输入层处理,而读入数据第二部分返回的事房间价格,应该交由名称为y的数据输入层处理。
理清数据输入层后,继续看到事件监听器的代码,这里还对每一轮训练结束后要进行的操作,具体逻辑为,训练了10轮后,就使用训练器trainer的save_params()方法将数据保存在模型中。
Paddle的事件监听器目前支持监听如下几种事件:
-
BeginEpochEvent:每一轮训练开始前会获得
-
EndEpochEvent:每一轮训练结束后会获得
-
BeginStepEvent:每一次训练结束后会获得
-
EndStepEvent:每一次训练结束后会获得
所谓一轮即将整个训练集数据都过了一遍,而每一次指当前使用一batch数据训练。
5.训练模型
到这里,就凑齐了训练器要进行训练的所有条件,接着就可以调用训练器trainer的train()方法训练模型了,代码如下:
-
trainer.train( -
reader=train_reader, -
num_epochs=100, -
event_handler=event_handler_plot, -
feed_order=feed_order -
)
train()方法需要传递4个参数,其中reader参数获得训练数据,numepochs参数定义训练的最大轮数,eventhandler参数获得事件监听器,feed_order参数定义输入数据对应到数据输入层的顺序
6.使用模型进行预测
在Paddle中,进行预测比较麻烦,首先需要定义预测网络的结构,代码如下:
-
def inference_program(): -
mm = fluid.layers.data(name='mm', shape=[13], dtype='float64') -
y_predict = fluid.layers.fc(input=mm, size=1, act=None) -
return y_predict
预测网络的结构很简单,接收输入,然后通过全连接层,获得对应的预测输出。
预测网络结构定义完后,接着就定义对应的预测器,如下:
-
inferencer = Inferencer( -
infer_func = inference_program, param_path = params_dirname, place=place -
)
预测器的定义使用Inferencer()方法,该方法需要传入3个参数,其中inferfunc参数获得预测网络的解耦股,parampath参数获得训练时保存的模型,而place参数则定义预测器运行的设备。
接着可以获得一些测试数据,代码如下:
-
batch_size = 10 -
test_reader = paddle.batch(paddle.dataset.uci_housing.test(), batch_size=batch_size) -
test_data = next(test_reader()) #从test_reader这个迭代器中获得一组数据 -
test_x = numpy.array([data[0] for data in test_data]).astype('float32') -
test_y = numpy.array([data[1] for data in test_data]).astype('float32')
这里通过numpy库获得测试数据中的10个数据,获得测试数据后,将房子属性数据传入预测器中,从而获得预测结果,代码如下:
-
# 将房价的测试数据输入到预测器中,获得预测结果 -
results = inferencer.infer({'mm': test_x}) -
-
print("infer results: (House Price)") -
-
# 预测器通过预测结构 -
for idx, val in enumerate(results[0]): -
print('%d: %.2f'%(idx, val)) -
-
# 真实结果 -
print("\nground truth:") -
for idx, val in enumerate(test_y): -
print("%d: %.2f" % (idx, val))
这里有点需要注意的是,要确保预测器获得的预测数据的格式与预测网络中输入层的类型一致以及与传入的训练模型文件中的输入层数据类型一致,这是经过试验得到的结论,原因不明,其实目前不明白预测时为何不直接获得训练模型来直接进行预测,而是要定义预测网络?
结尾
整体程序的部分运行结果如下:
-
Tarin cose, Step 2020, Cost 28.259064 -
Tarin cose, Step 2030, Cost 80.617767 -
Tarin cose, Step 2040, Cost 15.185576 -
Tarin cose, Step 2050, Cost 38.212794 -
Tarin cose, Step 2060, Cost 17.239103 -
Tarin cose, Step 2070, Cost 12.585729 -
Tarin cose, Step 2080, Cost 29.434976 -
Tarin cose, Step 2090, Cost 37.283709 -
-
infer results: (House Price) -
0: 14.22 -
1: 14.52 -
2: 13.94 -
3: 16.04 -
4: 14.66 -
5: 15.53 -
6: 14.84 -
7: 14.68 -
8: 11.87 -
9: 14.42 -
-
ground truth: -
0: 8.50 -
1: 5.00 -
2: 11.90 -
3: 27.90 -
4: 17.20 -
5: 27.50 -
6: 15.00 -
7: 17.20 -
8: 17.90 -
9: 16.30


















 4865
4865

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









