



#1、CURRENT_USER():返回当前用户
#2、SESSION_USER():返回当前用户
#3、SYSTEM_USER():返回当前用户
#4、USER():返回当前用户
SELECT CURRENT_USER();
SELECT SESSION_USER();
SELECT SYSTEM_USER();
SELECT USER();
以上都是返回当前用户,结果相同
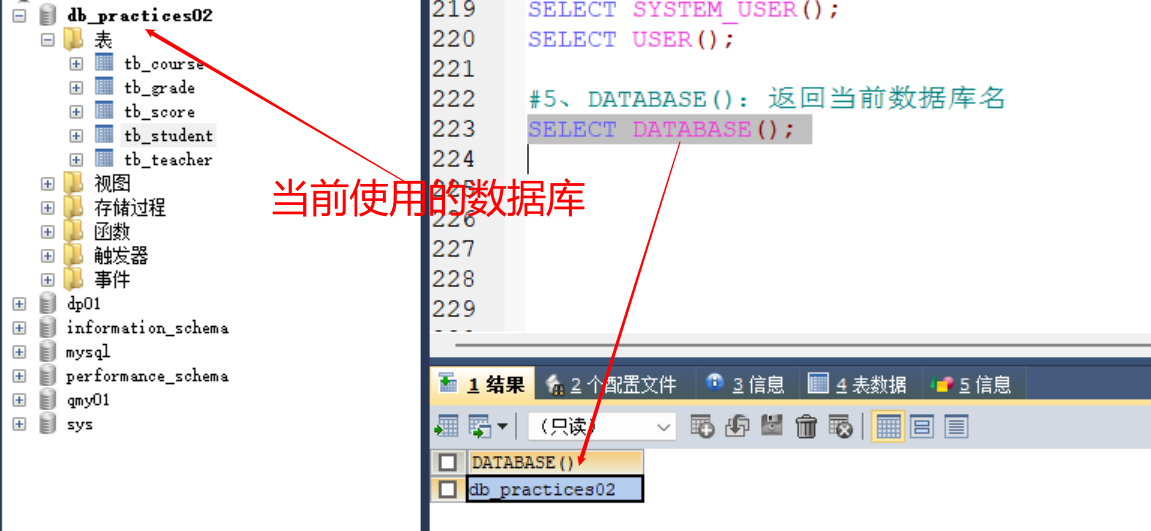
#5、DATABASE():返回当前数据库名
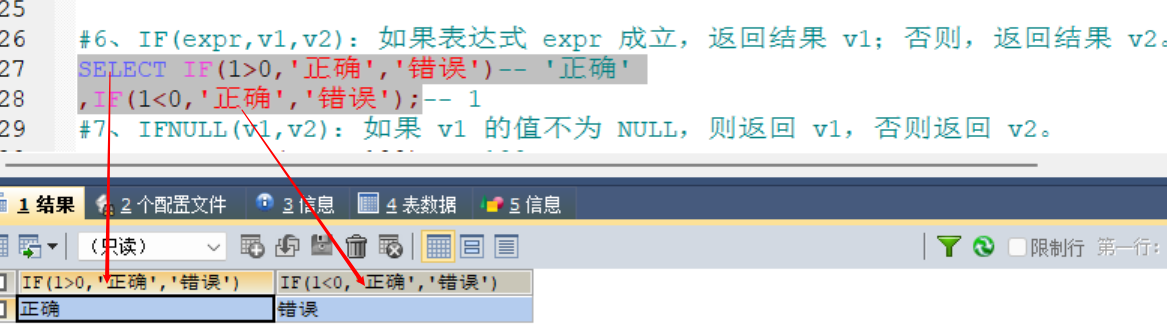
#6、IF(expr,v1,v2):如果表达式 expr 成立,返回结果 v1;否则,返回结果 v2。
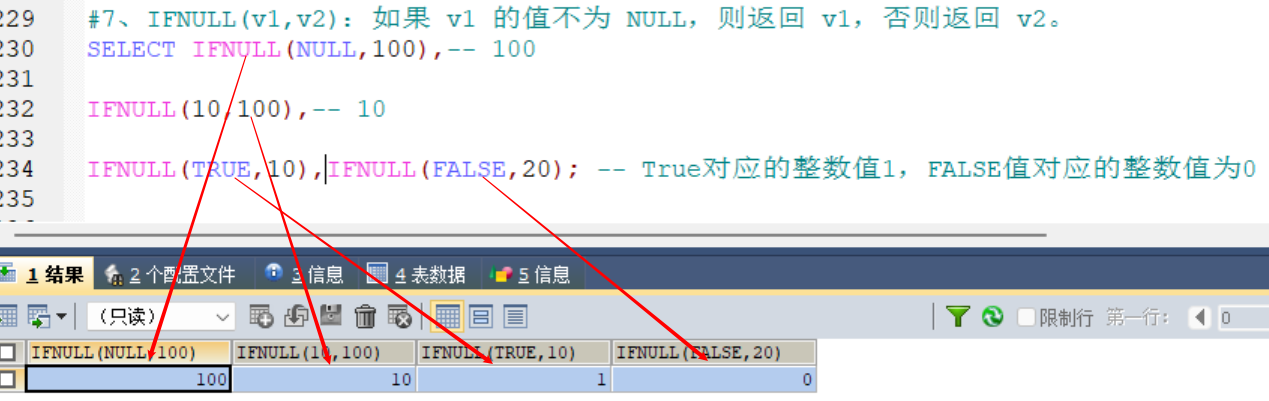
#7、IFNULL(v1,v2):如果 v1 的值不为 NULL,则返回 v1,否则返回 v2。
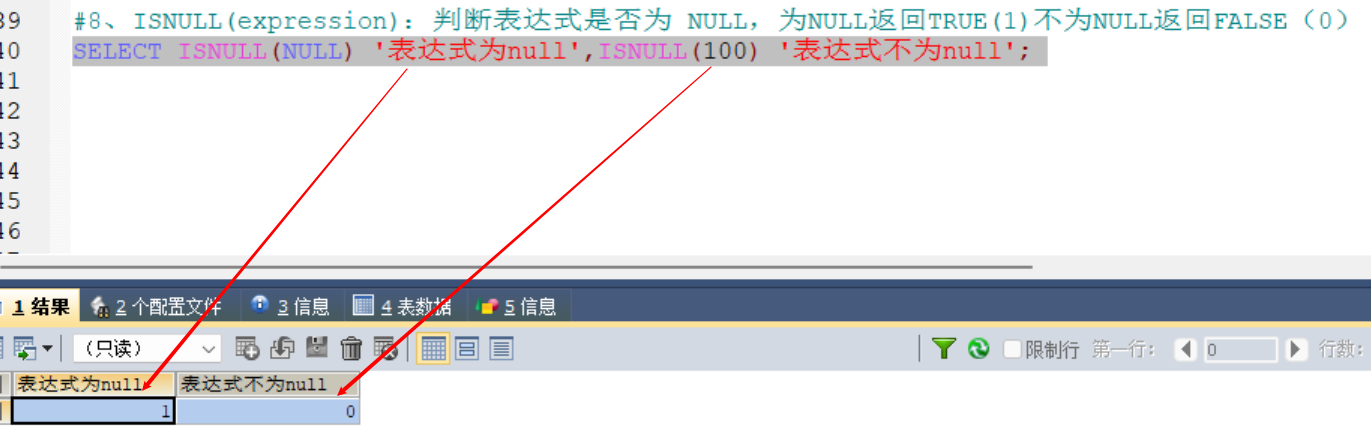
#8、ISNULL(expression):判断表达式是否为 NULL,为NULL返回TRUE(1)不为NULL返回FALSE(0)
#9、NULLIF(expr1, expr2):比较两个字符串,如果字符串 expr1 与 expr2 相等 返回 NULL,否则返回 expr1(不区分字母大小写)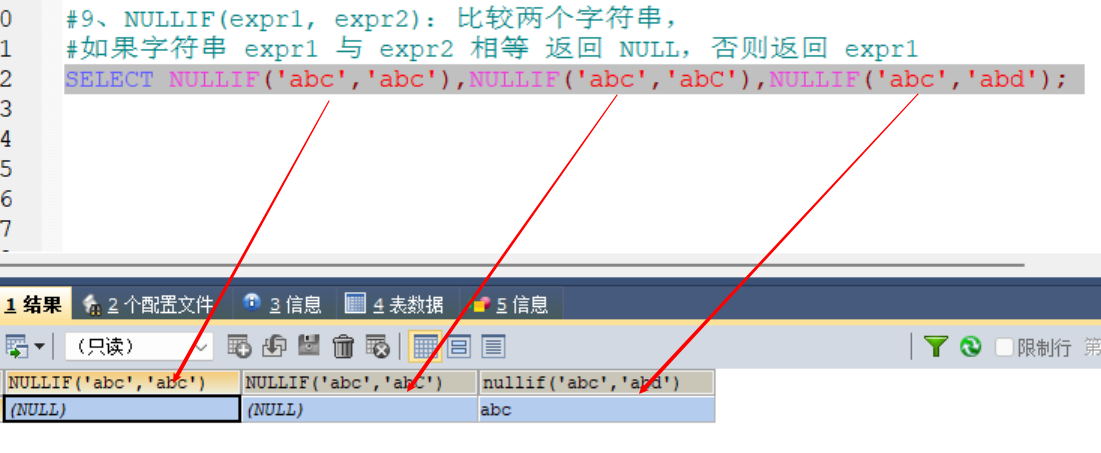
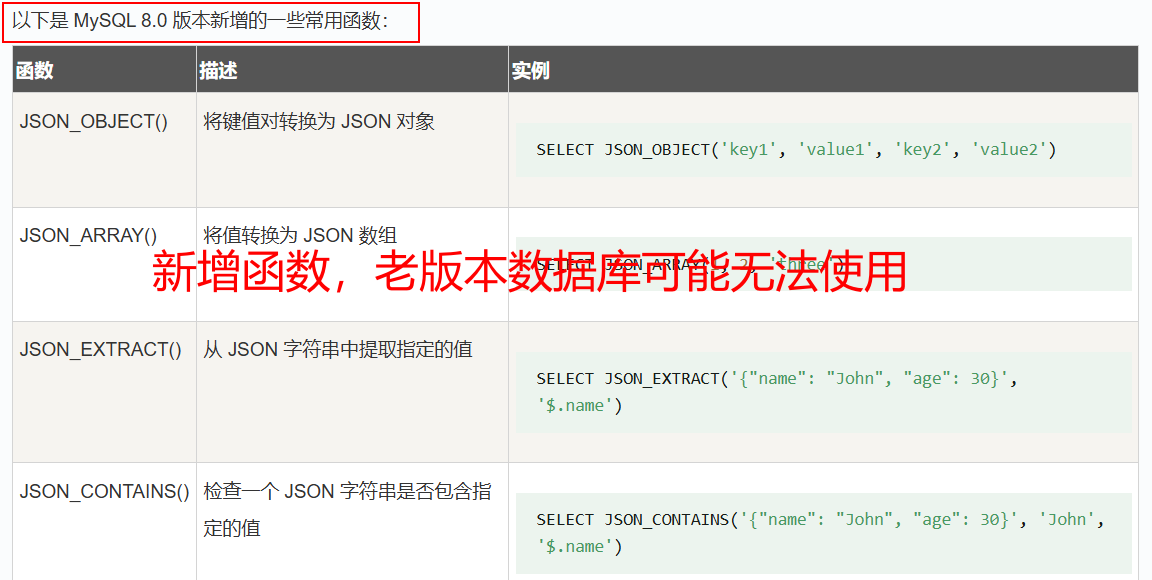
#10、VERSION():返回数据库的版本号,用于防范某些新出的函数在老版本的数据库无法使用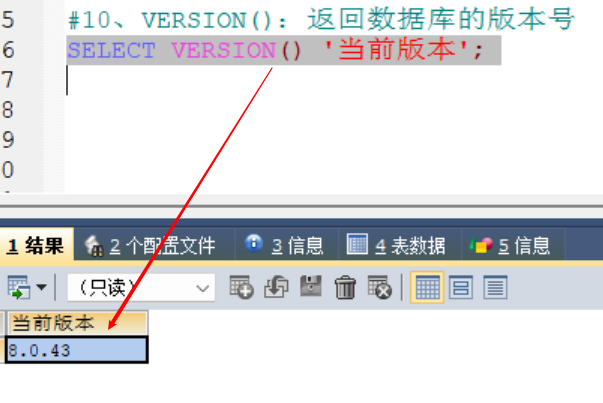
# -------------------------------------------------------
#七、分组查询
# 当需要分组查询时需要使用GROUP BY子句,例如查询每个部门的工资和,这说明要使用部分来分组。
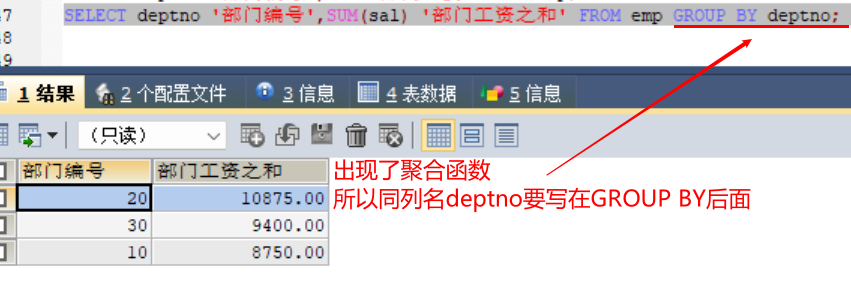
注:凡和聚合函数同时出现的列名,则一定要写在group by 之后
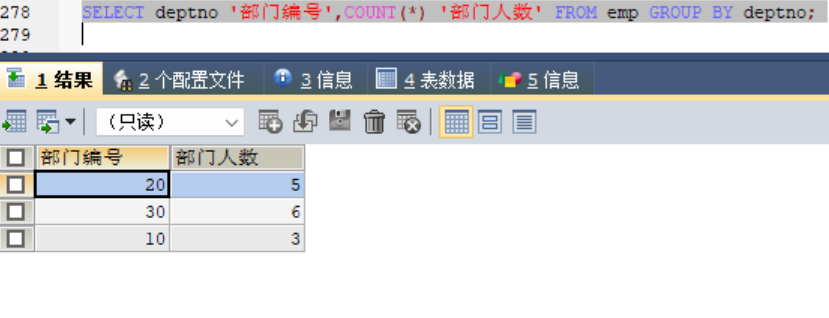
#1、查询每个部门的部门编号和每个部门的工资和:
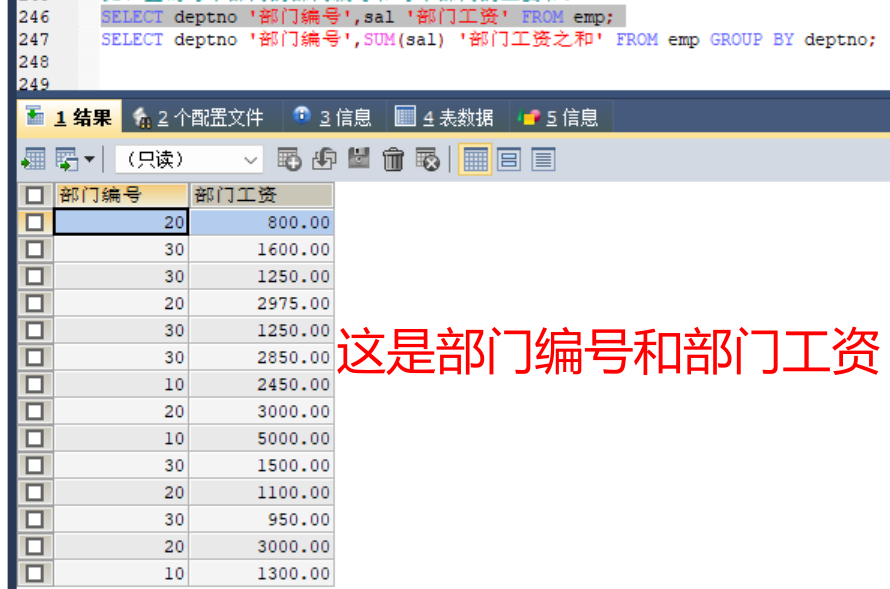
#2、查询每个部门的部门编号以及每个部门的人数
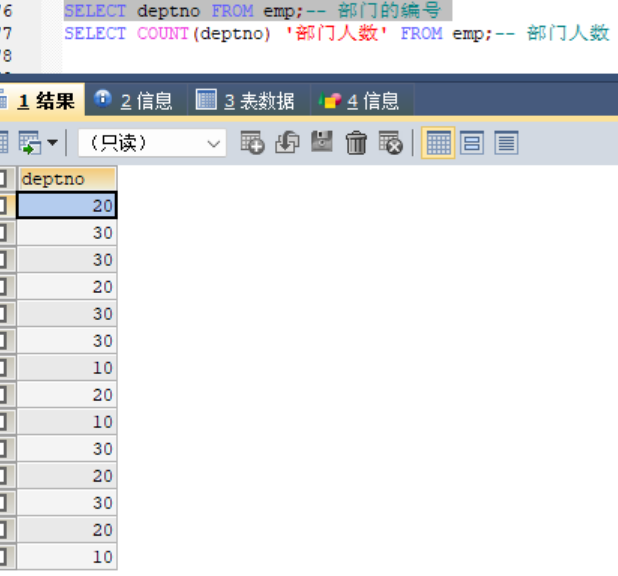
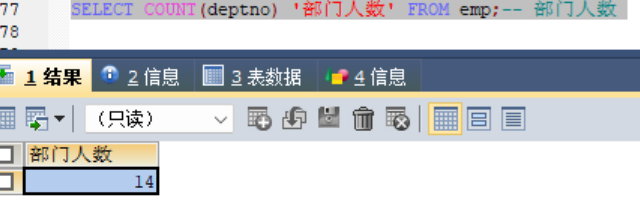
合在一块就是每个部门的人数,由于出现了聚合函数,所以同列名一定要写在group by 之后
#3、查询每个部门的部门编号以及每个部门工资大于1500的人数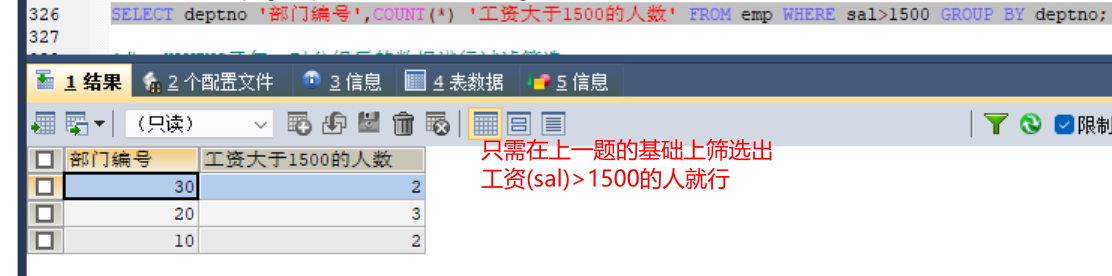
#八、HAVING子句:对分组后的数据进行过滤筛选
注:having与where的区别:
1、having是在分组后对数据进行过滤,where是在分组前对数据进行过滤
2、having后面可以使用分组函数(统计函数),where后面不可以使用分组函数。
3、WHERE是对分组前记录的条件,如果某行记录没有满足WHERE子句的条件,那么这行记录不会参加分组;而HAVING是对分组后数据的约束。
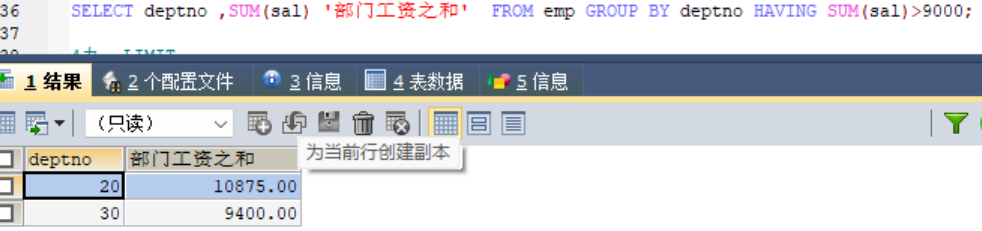
#1、查询工资总和大于9000的部门编号以及工资和
由于having是在分组之后进行筛选,所以至于要在原有的工资之和的基础上添加一句 HAVING 语句进行筛选即可
#九、LIMIT
#LIMIT用来限定查询结果的起始行,以及总行数。
#limit [起始行,] 数据条数
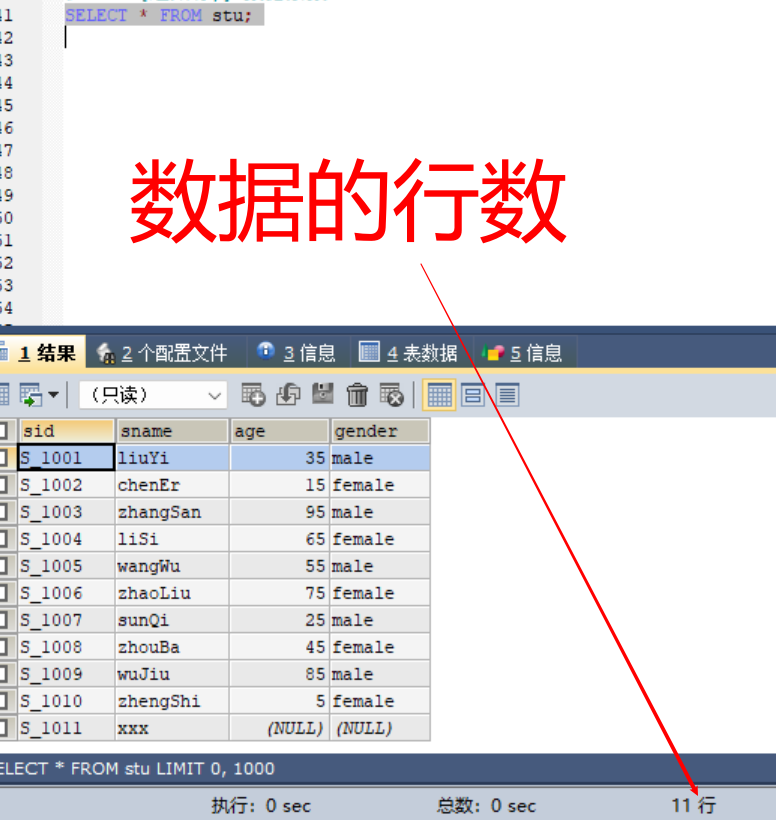
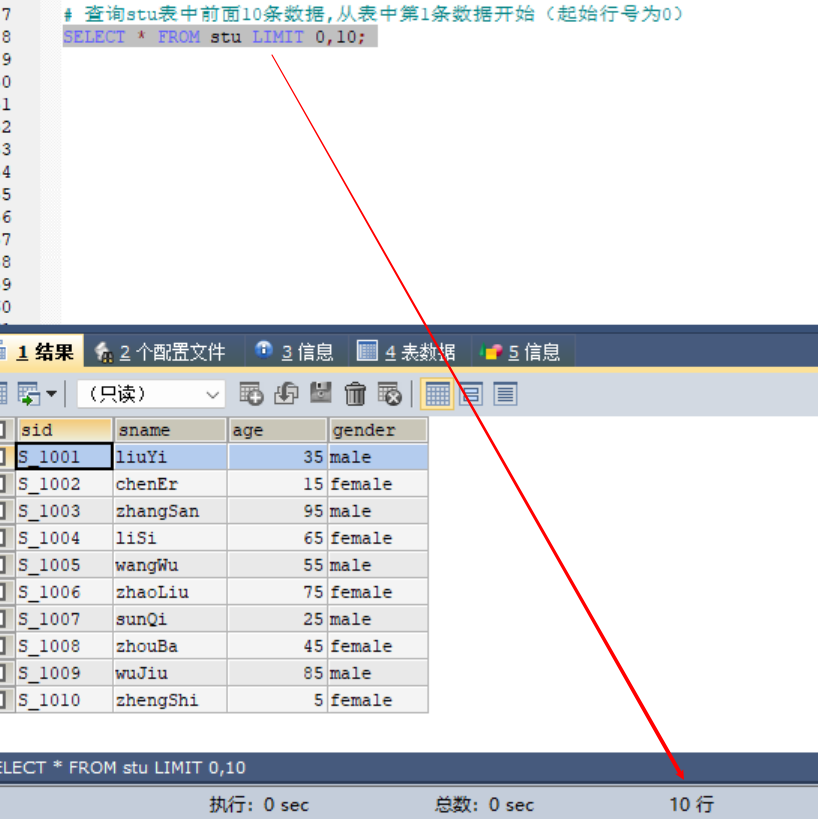
# 查询stu表中前面10条数据,从表中第1条数据开始(起始行号为0)
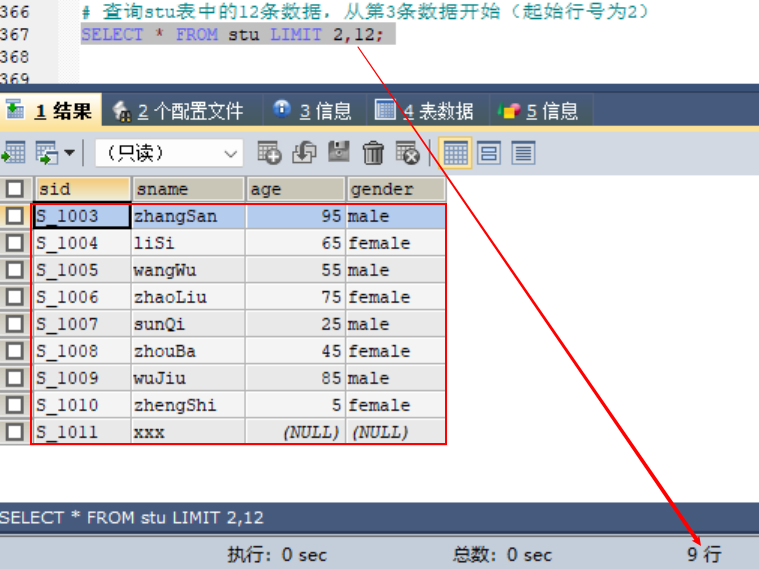
# 查询stu表中的12条数据,从第3条数据开始(起始行号为2)
# limit中的起始行号可以省略,当省略时,起始行号默认从0开始(也就是第1条数据)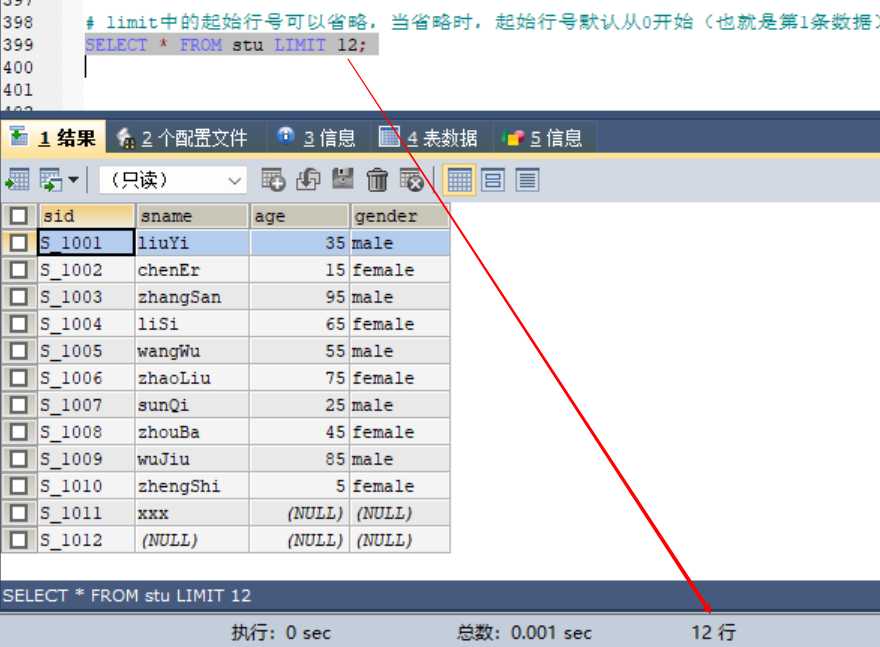
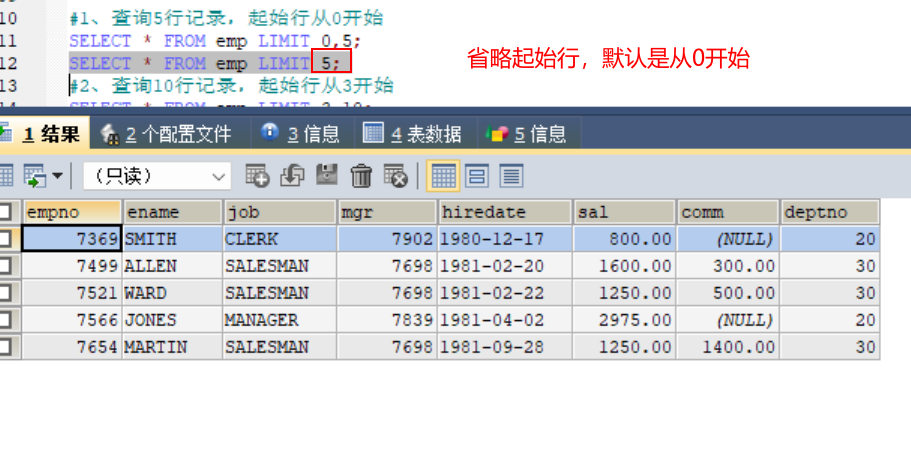
#1、查询5行记录,起始行从0开始
SELECT * FROM emp LIMIT 0,5; 或省略起始行 SELECT * FROM emp LIMIT 5;
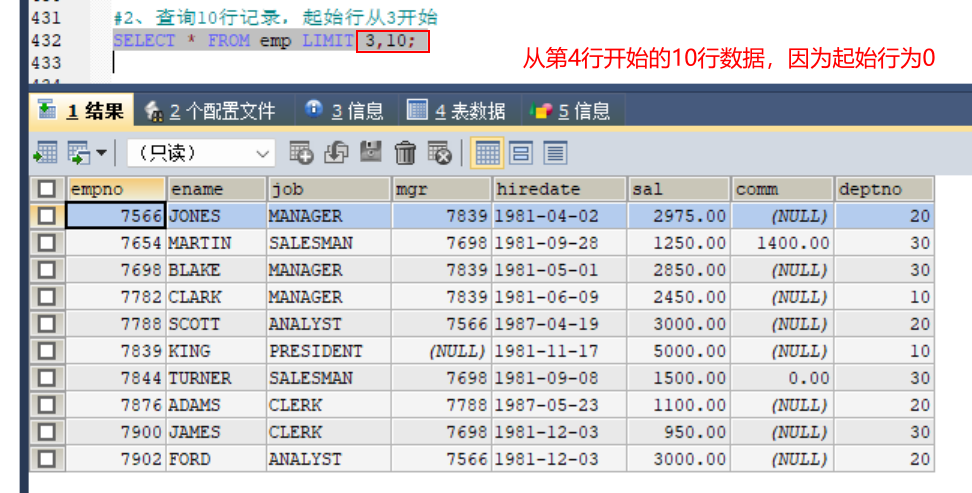
#2、查询10行记录,起始行从3开始

















 2084
2084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









