






 本文详细讲解了Hive中的TRUNC函数、正则表达式替换regexp_replace、COALESCE函数、时间戳转换 unix_timestamp 和 casewhen条件判断,以及substr函数的使用。此外,还比较了leftjoin与leftsemijoin的区别,并介绍了collect_list与collect_set在聚合中的应用,以及NVL函数的空值处理。
本文详细讲解了Hive中的TRUNC函数、正则表达式替换regexp_replace、COALESCE函数、时间戳转换 unix_timestamp 和 casewhen条件判断,以及substr函数的使用。此外,还比较了leftjoin与leftsemijoin的区别,并介绍了collect_list与collect_set在聚合中的应用,以及NVL函数的空值处理。
目录
CONCAT_WS(SEPARATOR ,collect_set(column))
left semi join
Hive中,左关联有left join和left semi join两种方式,两种方式存在很大的差别。
简单总结来说:
left join就是我们平时所用的left join。
而当A表left semi join关联B表时,结果表只能有A表的列,且B表只能在on中设置过滤条件,并且当B表有重复数据时,A表只会关联B对应值一次。某种意义上来说left semi join与in的功能非常相似。
当主表与关联表的关联列都存在重复数据时,由于产生笛卡尔积,使用left join是低效的。此时使用left semi join或者in时,往往能快速的查询出结果。
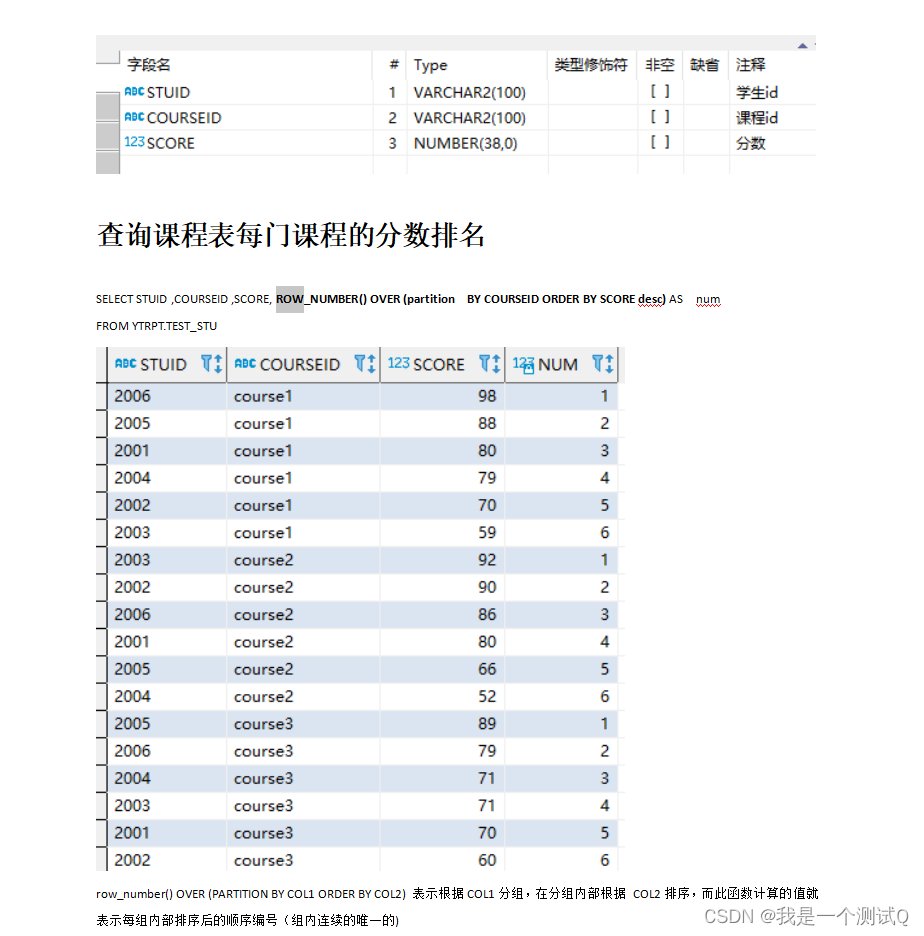
row_number () over
语法格式:row_number() over(partition by 分组列 order by 排序列 desc)
row_number() over()分组排序功能:
在使用 row_number() over()函数时候,over()里头的分组以及排序的执行晚于 where 、group by、 order by 的执行。
TRUNC函数
语法格式如下:
TRUNC(date[,fmt])
其中:date 一个日期值
fmt 日期格式,该日期将由指定的元素格式所截去
trunc('2021-11-28','MM') --2021-11-01
trunc('2021-11-28','YY') --2021-01-01
-
regexp_replace
语法: regexp_replace(string A, string B, string C)
操作类型: strings
返回值: string
说明: 将字符串A中的符合java正则表达式B的部分替换为C。
regexp_replace('2021-11-28','-','') --20211128
regexp_replace('h234ney', '\\d', 'o') --hoooney
regexp_replace('h234ney', '\\d+', 'o') --honey
-
coalesce
COALESCE(expression_1, expression_2, ...,expression_n)依次参考各参数表达式,遇到非null值即停止并返回该值。如果所有的表达式都是空值,最终将返回一个空值
coalesce('a','b') --a
coalesce(null,'b') --b-
unix_timestamp
unix_timestamp(string date) 转换格式为“yyyy-MM-dd HH:mm:ss“的日期到UNIX时间戳 单位是秒
unix_timestamp(string date, string pattern) 转换pattern格式的日期到UNIX时间戳 单位是秒
(unix_timestamp(coalesce(a.start_depart_time1,a.start_upcar_time1),'yyyy-MM-dd HH:mm:ss')-unix_timestamp(a.start_down_time1,'yyyy-MM-dd HH:mm:ss'))/3600
--取2个时间之间的差值,单位h-
case when
case when in_time =-1 then 0 else in_time end
CASE when 1= 1 then 1
when 2=2 then 2
else 3 end as c1
CAST (case when 1 =1 then 12.345 end as decimal(20,1)) as t1 ---12.3substr
使用语法: substr(string A, int start),substring(string A, int start)
substr(string A, int start, int len)
select substr('abcde',3) from test;//意为从第三个开始截取,一直到结尾。a的下标为1。
cde
select substr('abcde',-1) from testl; //截取最后一位
e
select substr('abcde',3,2) from test;//从第三个起开始截取两个步长
cd
select substring('abcde',-2,2) from test;//截取最后两个
decollect_list与collect_set
将分组中的某列转为一个数组返回,不同的是collect_list不去重而collect_set去重
| group_name | code |
| 合并组1 | 556001 |
| 合并组1 | 556006 |
| 合并组1 | 556006 |
select group_name,collect_set(merge_net_code) as merge_net_code_1
from ods.xxx
group by group_name| group_name | merge_net_code_1 |
| 合并组1 | ["556001","556006"] |
CONCAT_WS(SEPARATOR ,collect_set(column))
select group_name,concat_ws(',',collect_set(merge_net_code)) as merge_net_code_1
from ods.xxx
group by group_name| group_name | merge_net_code_1 |
| 合并组1 | 556001,556006 |
nvl
NVL函数的格式如下:NVL(expr1,expr2)
含义是:如果oracle第一个参数为空那么显示第二个参数的值,如果第一个参数的值不为空,则显示第一个参数本来的值

















 875
875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









