




 本文是Mysql的基础教程,涵盖了登录连接数据库、查看数据库、select数据检索、ORDER BY排序、WHERE子句过滤、LIKE操作符、GROUP BY分组、JOIN查询、INSERT插入、UPDATE更新和DELETE删除等操作。详细讲解了每个操作的使用方法和示例,帮助初学者掌握Mysql的基本操作。
本文是Mysql的基础教程,涵盖了登录连接数据库、查看数据库、select数据检索、ORDER BY排序、WHERE子句过滤、LIKE操作符、GROUP BY分组、JOIN查询、INSERT插入、UPDATE更新和DELETE删除等操作。详细讲解了每个操作的使用方法和示例,帮助初学者掌握Mysql的基本操作。
一.mysql基本操作
登录连接数据库
Mysql 登录方式分为两种,第一种为原生命令行的登录方式,如下:
- 按
Win + R打开我们的cmd命令行工具:

- 点击确定按钮,会弹出一个黑色的命令窗口,如下所示:

- 连接mysql,需要在窗口中输入
mysql -u (用户名) -p命令,然后再输入密码:

如果出现下图所示,不是内部或外部命令的情况,可能是你还没有把mysql的安装路径加入到本地的Path系统环境变量里面。

解决方法
-
如下图所示,在电脑的控制面板中找到高级系统设置:

-
在弹出界面顶部找到高级选项,点击环境变量按钮,如下所示:

-
在弹出的界面的系统环境变量(s)中找到Path:

-
点击编辑按钮,将mysql的bin目录添加进去,如:

-
Path中还会有其他软件的bin目录,用英文的
;将它们分隔即可。 -
然后关闭cmd 工具再打开,再次输入mysql的登录命令。

-
输入正确的密码,就可以登录成功啦,如下图所示是登录成功的界面。

查看数据库
当数据库登录成功之后,如果我们想查看数据库的列表,可以输入show databases;命令,会返回一个数据库列表。

如果要使用其中某个数据库,可以使用use 数据库名;命令,出现Databases changed表示提示你选择数据库成功:

在进入数据库之后,如果要查看数据库中的表,可以使用show tables;命令,回车后会下面会列出这个数据库中所有的表。

select检索数据
查询单个列
例如我们使用select语句从goods表中查询goods_name列 ,输出下所示:
SELECT goods_name FROM goods;

查询多个列
你也可以同时查询多个列,例如查询goods表中c_id、goods_name、price三个列的数据,列名之间用逗号分隔,输出如下所示:
SELECT c_id, goods_name, price FROM goods;

查询所有列
SELECT语句还可以直接查询表中所有的列,通过在列名的位置使用*通配符来查询,例如查询goods表所有数据,该语句输出如下:
select * from goods;

DISTINCT 查询不同行
使用SELECT 语句查询某一列数据的时候会返回所有的匹配行,但是这些匹配行中很可能会有重复的数据,如果我们不想得到重复的数据,可以使用DISTINCT关键字,此关键字表示只返回不同的值。
- 例如从goods表中查询price字段的数据结果如下所示,可以看到有两个3.00的数据:

- 使用
DISTINCT关键字后的查询结果如下所示,另一个重复的数据会被剔除:

LIMIT 限制查询结果
SELECT语句可以通过指定列名返回指定列的数据或使用*返回所有列数据,除此之外,使用LIMIT可以返回第一行或者前N行的数据。这也很好理解,LIMIT的中文意思表示限制,LIMIT后面接数字,则表示限制查询多少记录。
- 例如获取goods表中全部数据,如下所示,一共有5条记录:

- 使用
LIMIT关键字来获取前两行数据,如下所示:

- 如果要得到下一个2行(也就是第三行和第四行),可制定要检索的开始行和行数,如:
SELECT * FROM goods LIMIT 2,2 Limit 2, 2;
指定返回从第2行开始的2行数据,第一个数字为开始位置,第二个数字为要检索的行数,该语句输出如下:

ORDER BY排序
按单个列排序
在SELECT查询数据的时候,可以看如下返回的数据没有一个特定的顺序,如下:

其实查询出来的数据并不是以纯粹的随机顺序来显示的,如果不排序数据一般是从底层表中出现的顺序显示,这可以是数据最初的添加到表中的顺序,但是,如果数据后来进行过更新或者删除,则此顺序将会受到mysql重用回收存储空间的影响。
为了明确SELECT语句查询出的数据,可使用ORDER BY 子句对此输出结果进行排序,如下图中,是按price列进行排序(默认升序排序):

按多个列排序
实际应用中,我们可能需要按多个列来排序,如果要按照多个列排序,只要使列名之间用逗号隔开,如下所示,首先按照price列排序,然后再按照c_id列排序,输出结果如下:

至于为什么输出结果如上图所示,这里解释一下,按多个列排序具体操作是,在按price列排序之后,如果price列有相同的顺序,再继续按c_id列来对这些具有相同price的记录进行排序。反之,如果price没有相同的记录,那么就不会再按c_id列排序了。
指定排序方向
数据排序默认都是升序排序ASC,降序排序需要用到DESC,下图是按照price降序排序:

在多个列排序中,也可以分别指定排序形式,比如将price(价格)按降序排序,c_id(分类id)按升序排序,如下所示(当然这里其实没什么变化,因为price没有相同的数据,所以不会再按c_id列排序了):

where过滤数据
使用WHERE子句
数据表一般都包含大量的数据,通常会根据特定操作的需要提取表数据中的子集,只查询所需的数据需要指定搜索条件,在SELECT 语句中可以使用where子句来指定搜索条件,对数据进行过滤。注意where子句位于表名FROM子句之后,例如:

WHERE子句操作符
在where子句中我们可以使用如下几种操作符,来确定一个列是否包含对应特定的值。
=等于,查询·goods_name·列为西瓜的记录:
SELECT * FROM goods where goods_name = '西瓜'

!=不等于,查询goods_name列不为西瓜的所有记录:
SELECT * FROM goods where goods_name != '西瓜'

<>不等于,查询price列不等于5.00的记录:
SELECT * FROM goods where price <> 5.00

<小于,查询price小于5.00的记录:
SELECT * FROM goods where price < 5.00

<=小于等于,查询price列小于等于5.00的数据:
SELECT * FROM goods where price <= 5.00

>大于,查询price列大于5.00的记录:
SELECT * FROM goods where price > 5.00

>=大于等于,查询price列大于等于5.00的记录:
SELECT * FROM goods where price >= 5.00

BETWEEN查询指定的两个值(包括)之间的记录,例如查询price值位于5.00和7.00之前的记录:
SELECT * FROM goods where price between 5.00 and 7.00

组合WHERE子句
如果SELECT语句中有多个where条件,那么就需要用到and、or、&&、||等运算符、其中and和&& ,or和||是一样的意思。
AND操作符用来指示查询满足所有给定条件的记录,如查询满足c_id等于2的和price大于3.00的商品,注意这个和字很重要,说明必须同时满足两个条件:
SELECT * FROM goods where c_id = 2 and price >3.00

我们再来看一个查询语句,复杂一点点,同时使用了or和and:
SELECT * FROM goods where c_id = 2 or goods_name ='葡萄' and price >=4.00
当or操作符和and操作符同时存在会优先处理and操作符,那么这条sql语句的意思就会变成查询满足c_id=2这个条件 或者同时满足 goods_name为葡萄和price>=4.00这两个条件的商品,换句话说就是AND操作符的优先级更高。
那么此问题的解决办法是使用括号来明确的分组相应的操作符,如:
SELECT * FROM goods where (c_id = 2 or goods_name ='葡萄' ) and price >=4.00
这样一来sql语句的意思就变成了查询满足c_id=2或者goods_name为葡萄这两个条件中的一个 并且同时满足price>=4.00这个条件的商品,前面两个条件用括号括了起来,因为括号具有较AND 或 OR 操作符更高的计算次序。
IN操作符
圆括号在where子句中还有另外一种用法,就是IN操作符,它是用来指定条件范围,范围中的每一个条件都可以进行匹配。IN操作符取值用逗号分隔,全部在圆括号中,如查询满足id为1、2、4的记录:
select * from goods where id in (1,2,4)
其输出结果如下:

NOT操作符
NOT操作符在where子句中只有一个功能,就是对任何的条件取反,否定它之后的所跟的任何条件操作,如查询goods_name不是西瓜的记录:
select * from goods where not goods_name= '西瓜'
其输出结果如下:

like过滤数据
LIKE操作符
之前所有的操作符都是针对已知数据来进行过滤的,不管是匹配还是大于或者小于某值,或则检查某个范围的值,但是我们要搜索一个值的时候这些过滤条件都并不是好用的,那么我们就应该用到LIKE操作符。
LIKE操作符用于在 where 子句中搜索列中的指定模式,但是LIKE子句需要搭配通配符来使用,如果没有搭配通配符就相当于等于的意思。
如不使用通配符来查询goods_name 为苹果的记录:
select * from goods where goods_name like '苹果'

百分号(%)通配符
通配符%是最常使用的,在搜索串中,%可以代表任何字符出现的任意次数,如我们查找商品名称以‘苹’开头的记录:
select * from goods where goods_name like '苹%'

此例子使用了搜索模式,在执行这条子句时,将搜索任意以‘苹’开头的词(只要是以苹字开头,不管后面接多少个其他字都满足条件)。
或者我们还可以使用%在查询goods_name以‘果’结尾的记录:
select * from goods where goods_name like '%果'

以及使用查询goods_name的值中任意位置包含‘果’字的记录,不论’果’字之前或之后出现什么字符都满足条件。如:
select * from goods where goods_name like '%果%'

下划线(_)通配符
与上面百分号(%)的通配符类似的还有下划线(_)通配符,不同的是下划线通配符只匹配单个字符。如查询goods_name列中第一个字符为任意字符,后面以’果’字结尾的记录:
select * from goods where goods_name like '_果'

假如将上述sql语句中的_换成%通配符看看查询结果是怎样的:
select * from goods where goods_name like '%果'

这样我们就可以看出两个通配符的差别了,下面是一些常用的通配符使用格式:
%a:以a结尾的数据。a%:以a开头的数据。%a%:含有a的数据。_a_:三位且中间字母是a的 。_a:两位结尾且结尾字母是a的。a_:两位且开头字母是a的。
groupby分组数据
创建分组
分组是在SELECT语句的group by子句中建立的,比如根据c_id分组计算每个分类的总数量,其输出结果如下:
select c_id, count(*) as total from goods group by c_id

过滤分组
除了我们用group by分组数据外,我们还允许过滤分组,规定包括哪些分组,排除哪些分组,例如:我们之前用c_id分组获得每个分组有多少的总数量,然后根据这个总数量来进行过滤。
之前我们已经where子句的作用了,但是在这个分组例子中where不能完成,因为where过滤指定的是行而不是分组,且where没有分组的概念,那么我们这里可以使用HAVING子句,HAVING非常类似于WHERE。
事实上,目前为止所学的所有类型的WHERE子句都可以用HAVING来替代。唯一的差别是Where过滤行,而HAVING过滤分组。如:
select c_id, count(*) as total from goods group by c_id having total >2
分组和排序
我们在用分组的时候如果还想将数据根据指定的列来排序,那么我们可以把group by 和 order by 来一起使用,如:
select c_id,count(*) as total from goods group by c_id order by total desc

组合关联查询
创建联结
假如有两个表,一个是商品表goods,一个是商品分类表cat,商品表的c_id 对应分类表的id,这样就形成了关系表,如下
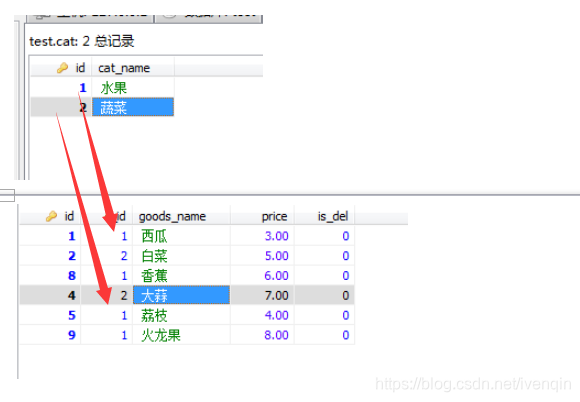
如上所示,这样分解数据存放在多个表才能有效的存储,更方便的处理,并且具有更大的可伸缩性,这样我们就要使用联结,联结是一种机制,用来在一条SELECT 语句中关联表,因此称为联结,可以联结多个表返回一组输出,如:
select * from goods, cat where goods.c_id = cat.id
其输出结果如下:

这样一来就是两个表联结起来,SELECT语句前与前面所有的语句一样也可以指定其中的列,如:
select goods.id,c_id,goods_name,cat_name from goods,cat where goods.c_id = cat.id
如果两个表中有同样的列名称,指定列的时候会报出错误,那么要指定出列名goods.id,因为只给出id就不知道是哪一个,其输出结果如下:

假如我们在创建联结的时候没有带上where条件子句,会怎样呢? 如:
select goods.id,c_id,goods_name,cat_name from goods,cat
其输出结果如下:

发现其第一个表的每一行与第二个表中的每一行配对,而不管它们是否可以配在一起,这样我称为笛卡尔积,由没有联结条件的表关系返回的结果为笛卡尔积,检索出的行的数目是第一个表中的行数乘以第二个表中的行数,但是这样的数据是没有意义的,所以不要忘了where 条件子句且保证where 子句的准确性
内部联结
在上述联结中我们所用的都成为等值联结,它基于两个表之间的相等测试,这种也成为内部联结,其实我们还可以用稍微不同的语法来明确指定联结的类型,如:
select goods.id,goods_name,price,cat_name from goods INNER JOIN cat on goods.c_id=cat.id
其返回结果如下:

此语句的SELECT与上面之前的SELECT相同,但是From子句不同。这里,两个表之间的关系是From子句的组成部分,以INNER JOIN指定。在使用这种语法时,联结条件用特定的on子句而不是where子句给出,传递给on的实际条件与传递where条件其实相同。
使用别名
我们在使用联结查询的时候,查询某一些列的时候我们可以使用别名as给列重新起一个名字(别名),如下所示,给id列指定了一个别名aa:
select goods.id as aa , goods_name, price,cat_name from goods INNER JOIN cat on goods.c_id=cat.id
还有一种情况就是在from语句后面的表名指定一个别名,那么查询列的时候就可以使用别名来指定列名,如下所示,给goods表指定一个别名a,给cat表指定一个别名b,在我们指定列(说明这个列是哪个表中的列,以免两个表中有相同列名时发送冲突)的时候就可以通过这个别名来指定:
SELECT a.id AS aa, goods_name, price, cat_name
FROM goods AS a
INNER JOIN cat AS b ON a.c_id=b.id
其输出结果如下:

外部联结
上述联结都是将一个表中的行与另一个表中的行相关联,但有时候会需要包含没有关联行的那些行,如:
SELECT * FROM goods AS g LEFT JOIN cat AS c ON g.c_id = c.id
其输出结果如下:
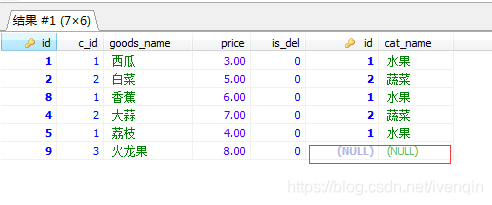
该语句类似上面的内部联结,这条SELECT语句使用了关键字left join从from的子句从左边表good表来关联另外一个表查询,但与内部联结关联两个表中的行不同的是,外部联结还包括没有关联行的行。
上面是从左边表来关联另外一个表查询,我们还可以使用right join,也就是右边表关联左边表来查询,如:
SELECT * FROM goods AS g RIGHT JOIN cat AS c ON g.c_id = c.id
其输出结果如下:

合并查询
多数的sql语句都是包含从一个或多个表中返回数据的单条SELECT语句。那么我们也可以使用多条sql语句来合并起来,并将结果作为单个查询结果集返回,这样的组合通常成为合并或复合查询,那么使用方法可用union操作符号来组合多条sql查询。如:
SELECT * FROM goods Where price = 3.00
UNION
SELECT * FROM goods WHERE id = 2
其返回结果如下:

有时候我们在使用union的时候要注意几条规则:
union必须是由两条或两条以上的select语句组成的,语句之间用关键字union分隔。union中的每个查询必须包含相同的列、表达式或聚集函数。
插入数据
插入单条
Insert into 是指插入或添加到数据库表中,例如我们向goods表中插入单条数据:
insert into goods values (10, 3, '红薯', '1.00', 0)

此例子插入一个新的商品到goods表中,储存到每个列中的数据都由values子句指定,每个列都需要对应一个值,如果该列没有值,那么各个列必须以它们在表定义中出现的次序填充,虽然这种插入方式语法很简单,但是并不安全,我们应该避免尽量使用,而我们应该要这样写,如:
insert into goods (c_id,goods_name,price) values (11,'玉米','5.00')
执行结果:

这两种写法查询结果都一样,但是下面这个insert语句表名后的括号里明确地给出了列名。在插入行时,将用values列表中的相应值填入列表中的对应项。因为提供了列名,values必须以其指定的次序匹配指定的列名,不一定按各个列出现在实际表中的次序。这种写法的优点是,即使表的结构改变,insert语句仍然能正确工作。
当我们设置一个列为自增长时,可以不指定这个列的值,因为它会自动增长,例如上面的id列。
插入多条
Insert可以同时插入多条记录,例如向goods表中同时插入两条记录:
insert into goods (c_id, goods_name, price) values (2, '玉米', 5.00),(2, '土豆', 2.00)

插入检索出的数据
Insert 一般用来给表插入一个指定列值的行,其实insert还存在另外一种形式,可以利用它将一条select语句的查询结果插入另一个表中。这就是所谓的insert selelct。
例如将standby_goods表的查询结果插入到goods表中:
insert into goods(c_id, goods_name, price) select c_id, goods_name, price from standby_goods
standby_goods表的数据如下:

结果如下:

Update 更新数据
更新部分数据
想要更新和修改数据我们可以使用update语句,如将goods 表中id 为9的记录中c_id列的值修改为1:
update goods set c_id = 1 where id = 9

update语句总是以要更新的表的名字开始,set命令用来将新值赋给被更新的列,where子句指定条件。
如果在update语句中没有指定where子句则表示更新所有goods表中c_id列的值,所以这个地方我们要注意。
update还可以更新多个列,如下所示:
update goods set c_id = 1, price=5.00 where id = 9

多表关联更新
先来看一个update语句:
UPDATE goods , cat SET goods.goods_name = '芒果', cat.cat_name = '新鲜水果' where goods.id = 5 and cat.id=1
执行结果:


此语句改变了两个表的数据,在update后接了两个表,set指定了两个表中要改变的列的值,where子句中指定需要满足的条件。最终结果改变了goods表中满足id=5的goods_name列的值,以及cat表中满足id = 1的cat_name 列的值。
Delete 删除数据
根据条件删除
从一个表中删除一行特定的数据就需要使用delete语句,如:
delete from goods where id =4
指定结果:

这样id为4的数据就被删除了,但是要注意的是,假如delete语句中不带where条件,则表示删除表中全部的数据,这是很危险的所以要特别注意这个问题。
学习更多关于数据库的知识可以去:https://www.9xkd.com/


















 408
408




 到【灌水乐园】发言
到【灌水乐园】发言







