




 本文探讨了MyBatis二级缓存中LRU算法的实现原理,指出常见误解,并详细分析了源码。在MyBatis的LruCache中,不活跃的节点作为头节点会被剔除,而非尾节点。通过调整缓存大小为5,当超过容量时,新增元素会导致最不活跃的头节点被移除。LRU算法的关键在于重写removeEldestEntry方法和设置accessOrder属性。虽然HashMap本身线程不安全,但MyBatis通过TransactionalCache和SynchronizedCache确保了二级缓存在并发环境下的安全性,所有关键操作都在锁的保护下进行。
本文探讨了MyBatis二级缓存中LRU算法的实现原理,指出常见误解,并详细分析了源码。在MyBatis的LruCache中,不活跃的节点作为头节点会被剔除,而非尾节点。通过调整缓存大小为5,当超过容量时,新增元素会导致最不活跃的头节点被移除。LRU算法的关键在于重写removeEldestEntry方法和设置accessOrder属性。虽然HashMap本身线程不安全,但MyBatis通过TransactionalCache和SynchronizedCache确保了二级缓存在并发环境下的安全性,所有关键操作都在锁的保护下进行。
首先说结论,百度Mybatis的lru算法时,都说的是,活跃的节点放到了头部,如果容量满了,会先剔除掉尾节点。这个说法是不对的,在MyBatis中的lruCache中,不活跃的节点是头节点,这个节点会被剔除掉,每次我们的get和put操作时,会把活跃的节点放到尾部。
为了方便研究问题,我们先修改源码,将LruCache的容量改小点:size改为5.
public class LruCache implements Cache {
private final Cache delegate;
private Map<Object, Object> keyMap;
private Object eldestKey;
public LruCache(Cache delegate) {
this.delegate = delegate;
//修改容量为5
setSize(5);
}
//省去别的方法
}或者:直接在源码的测试包下面找到,LruCache的测试类
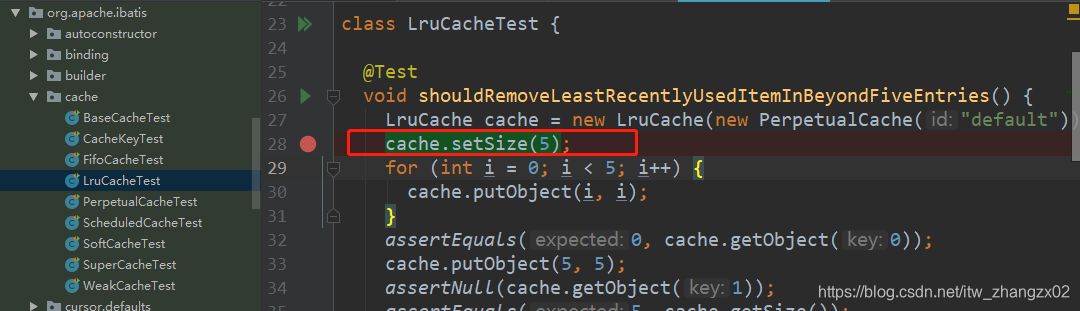
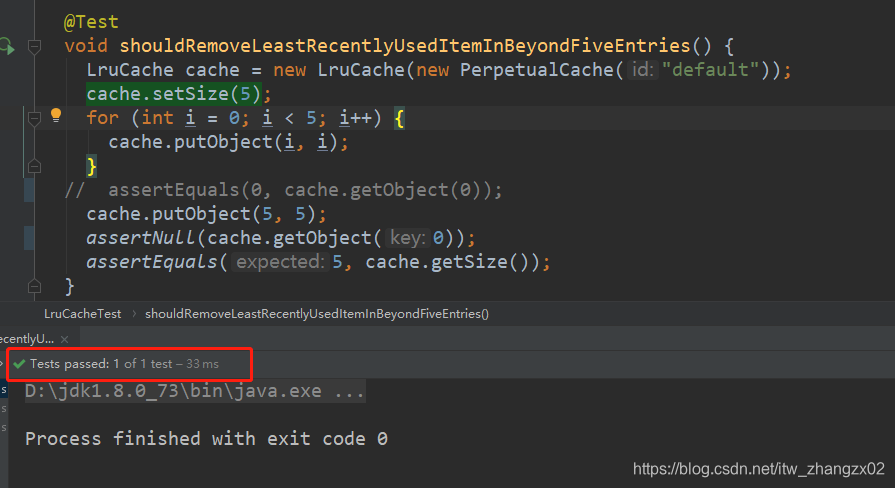
我的容量为5,先放入进去0,1,2..,4;然后我放入5.这时候,我的0被移除了。
我们先看看,我们的put操作:
//执行SetSize的时候,我们会先初始化一个匿名内部类(继承LinkedHashMap),第三个参数设置
//为false时,是按
//加入map时的时间排序的,如果时true时,就是按照操作时间排序的。(put和get操作可以理解为都是对
//数据进行了操作)
public void setSize(final int size) {
keyMap = new LinkedHashMap<Object, Object>(size, .75F, true) {
private static final long serialVersionUID = 4267176411845948333L;
//这个方法必须重写,返回为true时,说明超过容量,要移除不活跃的节点(header节点
//)。因为在HashMap中这个方法是默认返回fasle的,也就是容量满了不会移除节点
@Override
protected boolean re 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









