









AI大模型踩过的坑,每一个都价值千万
看着你们公司几十台服务器嗡嗡作响,显卡温度报警声此起彼伏,老板又在催问"
大模型什么时候能上线?"
这个熟悉的场景,是不是让你想起了那句话——“理想很丰满,现实很骨感”。
训练一个千亿参数的大模型,好比盖一栋摩天大楼。你以为只要有钱买材料、雇工人就行了?错!数据就是你的地基,地基不牢,再好的建筑师也救不了你。
把大象装进冰箱需要几步?三步。
训练大模型也需要几步?还是三步:**数据准备、预训练、后训练。**听起来简单,做起来?那可真是"一入AI深似海"。
![[tu]](https://i-blog.csdnimg.cn/direct/fb849441cd354a05b2001dcb389b9ff3.png)
先导模型:你的"试错成本控制器"
大家有没有遇到过这种情况:花了几个月时间训练大模型,结果数据配比有问题,模型效果惨不忍睹。
这时候你恨不得找个地缝钻进去,老板的眼神能杀死人。
聪明的工程师发明了"先导模型"这个救命稻草。
打个比喻,就像你买房前会先看样板间一样,先导模型就是你的"数据样板间"。用1B参数的小模型先跑一遍,验证数据配比是否合理,再应用到主模型上。
![[tu]](https://i-blog.csdnimg.cn/direct/6e554be6a9464673bc619f1d3597ef41.png)
这种做法救了无数工程师的职业生涯。
有个朋友跟我说,他们团队用先导模型发现数学数据配比不足,及时调整后,主模型在数学推理任务上的表现提升了40%。要是直接用主模型试错,光是重新训练的时间成本就能让项目延期半年。
多级先导模型更是高级玩法。一级先导模型管大方向,二级先导模型做精细调优。就像军队作战,有战略层面的司令部,也有战术层面的前线指挥所。
虽然增加了复杂度,但大大降低了风险。
预训练配比:数据的"营养搭配"
训练大模型就像养孩子,光给他吃肉不行,光吃蔬菜也不行,得营养均衡。数据配比就是你的"营养搭配师"。
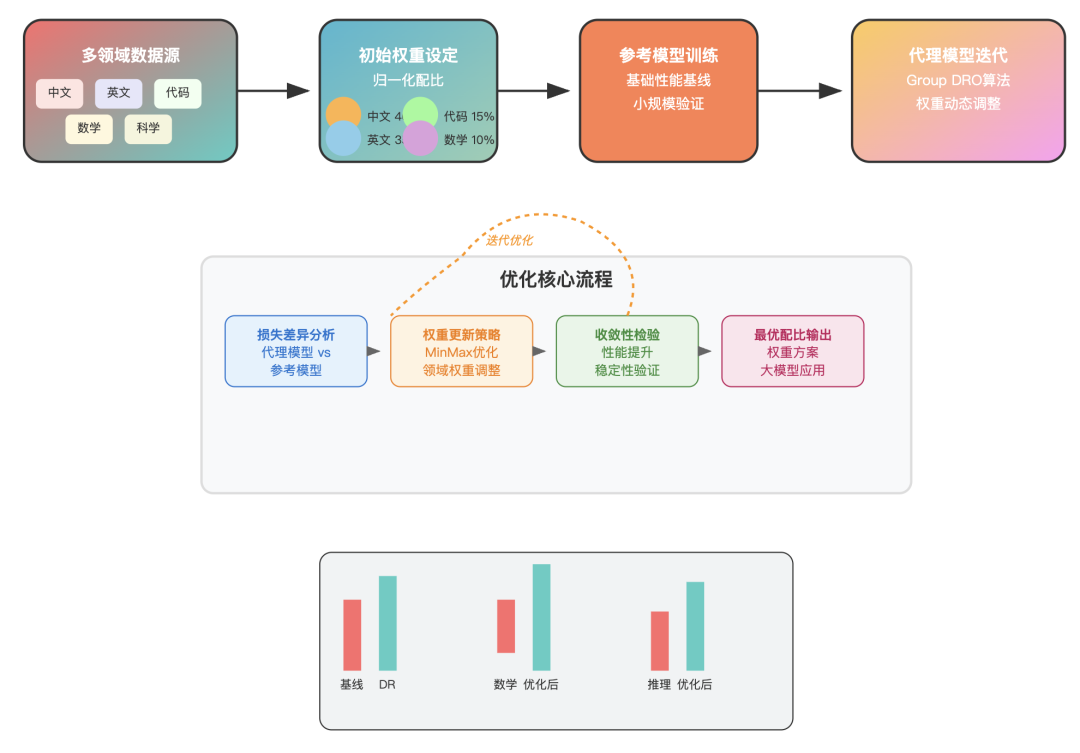
有个有趣的发现:增加中文数据比例到40%,模型在英文评测集上的表现竟然比纯英文数据训练的还要好。
这打破了很多人的常识认知。就像学会了中文的外国人,理解英文反而更透彻了。
数学数据更是"性价比之王"。LLaMA3把数学数据比例提到25%,代码占到17%,结果在各种推理任务上都有显著提升。这说明数学训练不仅提升数学能力,还能增强逻辑思维能力。
后训练筛选:从"大海捞针"到"精准制导"
如果说预训练是"广撒网",那后训练就是"精准制导"。
这个阶段,数据质量比数量更重要。你宁愿要1万条高质量数据,也不要100万条垃圾数据。
CherryLLM的思路很巧妙:用少量数据先训练一个小模型,然后用这个模型评估哪些数据的"指令追随难度"最高。
难度高的数据往往包含更丰富的信息,训练价值更大。就像健身教练会给你安排适当难度的训练,太简单没效果,太难又容易受伤。
![[tu]](https://i-blog.csdnimg.cn/direct/f2303cb55f6844119aaafbc13e01388b.png)
LESS方法更是"技术流"的代表。它通过计算样本梯度相似度来筛选数据,这就像给每个数据样本做"基因检测",找出那些对模型训练贡献最大的样本。
有个实际案例让我印象深刻:某团队用少量数学数据进行微调,结果模型在多个通用任务上都有显著提升。
这说明高质量的专业数据具有"溢出效应",不仅提升专业能力,还能增强通用能力。
结语
训练大模型就像烹饪一道复杂的大菜。
数据是食材,配比是调料,筛选是火候控制。光有好食材不行,还得会搭配、会调味、会控制火候。
先导模型让你避免了"把一锅好菜炒糊"的风险,预训练配比确保了"营养均衡",后训练筛选保证了"精工细作"。这套组合拳下来,你的大模型才能在激烈的竞争中脱颖而出…
现在,你还觉得训练大模型只是简单的"把大象装进冰箱"吗?



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











