







AI医生、AI工程师、AI设计师同时在线?多模态大模型让一切皆有可能
在人工智能的舞台上,多模态大模型正在上演一场精彩纷呈的视觉盛宴。它不仅能读懂图片中的细节玄机,更能挥洒创意,将文字化为生动画面。
从医生手中的CT影像到工厂流水线的质检,从设计师的灵感迸发到数字内容的智能创作,多模态大模型正在重新定义我们与数字世界的互动方式…
![[]](https://i-blog.csdnimg.cn/direct/08daf97f167047ccb0e8ef6ae673d9a6.png)
多模态大模型:AI视觉的新纪元
多模态大模型正掀起AI领域新一轮技术革命。从识别简单图像到理解复杂场景,从生成单幅图画到创作连贯视频,这项技术正以惊人的速度改变着我们与数字世界交互的方式。
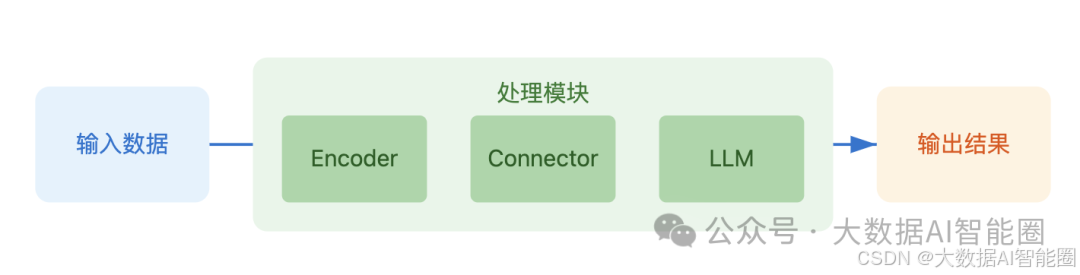
当今企业正面临信息洪流带来的机遇与挑战。文字、图像、音频、视频等多种形式数据蕴藏着巨大价值,而多模态大模型开启了一个全新认知时代。从基础图像理解到复杂场景推理,从简单文生图到高质量视频生成,这项技术正重新定义着AI的能力边界。
让我们深入探讨多模态大模型的三大核心能力:
基础图像理解能力
现代多模态大模型展现出卓越的视觉认知水平。它们不仅能完成传统的图像分类、目标检测任务,还能准确解读图片中的细节信息、空间关系和上下文语境。GPT-4V等模型甚至能理解图片中的箭头标注、文字说明等视觉提示,展现出接近人类的场景理解能力。
细粒度图像分析
在医疗影像分析、工业质检等专业领域&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











