




hdfs的设计理念:当数据集的大小超过单台计算机的存储能力时,就有必要将其进行分区并存储到若干台单独的计算机上。可以这样说
hadoop有一个抽象的文件系统概念,HDFS只是其中的一个实现。
在hadoop里,hadoop定义了一个抽象的文件系统的概念,具体就是hadoop里面定义了一个java的抽象类:org.apache.hadoop.fs.FileSystm,这个抽象类用来定义hadoop中的一个文件系统接口,只要某个文件系统实现了这个接口,那么它就可以作为hadoop支持的文件系统
|
文件系统 |
URI方案 |
Java实现 (org.apache.hadoop) |
定义 |
|
Local |
file |
fs.LocalFileSystem |
支持有客户端校验和本地文件系统。带有校验和的本地系统文件在fs.RawLocalFileSystem中实现。 |
|
HDFS |
hdfs |
hdfs.DistributionFileSystem |
Hadoop的分布式文件系统。 |
|
HFTP |
hftp |
hdfs.HftpFileSystem |
支持通过HTTP方式以只读的方式访问HDFS,distcp经常用在不同的HDFS集群间复制数据。 |
|
HSFTP |
hsftp |
hdfs.HsftpFileSystem |
支持通过HTTPS方式以只读的方式访问HDFS。 |
|
HAR |
har |
fs.HarFileSystem |
构建在Hadoop文件系统之上,对文件进行归档。Hadoop归档文件主要用来减少NameNode的内存使用。 |
|
KFS |
kfs |
fs.kfs.KosmosFileSystem |
Cloudstore(其前身是Kosmos文件系统)文件系统是类似于HDFS和Google的GFS文件系统,使用C++编写。 |
|
FTP |
ftp |
fs.ftp.FtpFileSystem |
由FTP服务器支持的文件系统。 |
|
S3(本地) |
s3n |
fs.s3native.NativeS3FileSystem |
基于Amazon S3的文件系统。 |
|
S3(基于块) |
s3 |
fs.s3.NativeS3FileSystem |
基于Amazon S3的文件系统,以块格式存储解决了S3的5GB文件大小的限制。 |
在hadoop里有一个文件系统概念,例如上面的FileSystem抽象类,它是位于hadoop的Common项目里,主要是定义一组分布式文件系统和通用的I/O组件和接口,hadoop的文件系统准确的应该称作hadoop I/O。而HDFS是实现该文件接口的hadoop自带的分布式文件项目,hdfs是对hadoop I/O接口的实现。
下面我给大家展示一张表,这样大家对hadoop的FileSystem里的相关API操作就比较清晰了,表如下所示:
|
Hadoop的FileSystem |
Java操作 |
Linux操作 |
描述 |
|
URL.openSteam FileSystem.open FileSystem.create FileSystem.append |
URL.openStream |
open |
打开一个文件 |
|
FSDataInputStream.read |
InputSteam.read |
read |
读取文件中的数据 |
|
FSDataOutputStream.write |
OutputSteam.write |
write |
向文件写入数据 |
|
FSDataInputStream.close FSDataOutputStream.close |
InputSteam.close OutputSteam.close |
close |
关闭一个文件 |
|
FSDataInputStream.seek |
RandomAccessFile.seek |
lseek |
改变文件读写位置 |
|
FileSystem.getFileStatus FileSystem.get* |
File.get* |
stat |
获取文件/目录的属性 |
|
FileSystem.set* |
File.set* |
Chmod等 |
改变文件的属性 |
|
FileSystem.createNewFile |
File.createNewFile |
create |
创建一个文件 |
|
FileSystem.delete |
File.delete |
remove |
从文件系统中删除一个文件 |
|
FileSystem.rename |
File.renameTo |
rename |
更改文件/目录名 |
|
FileSystem.mkdirs |
File.mkdir |
mkdir |
在给定目录下创建一个子目录 |
|
FileSystem.delete |
File.delete |
rmdir |
从一个目录中删除一个空的子目录 |
|
FileSystem.listStatus |
File.list |
readdir |
读取一个目录下的项目 |
|
FileSystem.getWorkingDirectory |
|
getcwd/getwd |
返回当前工作目录 |
|
FileSystem.setWorkingDirectory |
|
chdir |
更改当前工作目录 |
hadoop的FileSystem里有两个类:FSDataInputStream和FSDataOutputStream类,它们相当于java I/O里的InputStream和Outputsteam,而事实上这两个类是继承java.io.DataInputStream和java.io.DataOutputStream。
hdfs的架构
一个典型的hdfs集群中,包含 namenode,secondarynode,和至少一个datanode,所有的数据都存储在运行datanode进程的节点的块(block)里。
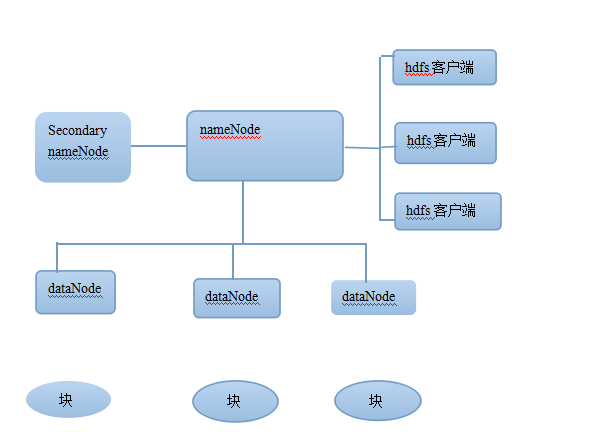
首先要解析块这个名词
每个磁盘都有默认的数据块大小,就是磁盘进行读写的最小单元,文件系统也有文件块的概念,如ext3,ext2等。
hdfs的默认文件系统的块大小为64M,也可以通过设置 hdfs-site.xml配置文件中的dfs.block.size项的大小。
dfs.relication 配置为每个HDFS的块在hadoop集群中复制份数。
例如 :一个data.txt文件,大小为150M,hdfs文件块大小为64M,那么文件就分为3块
第一块 64M
第二块 64M
第三块 22M
这里特别要指出,hdfs小于一个块文件大小的文件不会占据整个块的空间,但是还是会分配一个块。
nameNode ,SecondaryNameNode
nameNode也被称为名字节点,是hdfs(master/slave)架构的主角色,维护整个文件系统的目录树,以及目录树里所有的文件和
目录,这些信息以两种文件存储在本地文件系统 一种》fsimage(命名空间镜像,即HDFS元数据的完整快照),另外一种 edit log(命名空间镜像的编辑日志)
secondaryNameNode 用于定期合并fsimage和edit log.
fsimage文件其实是文件系统元数据的一个永久性检查点,其流程如下

(1).secondaryNameNode 引导nameNode滚动更新edit log文件,并开始将新的内容写入edit log.new
(2).secondaryNameNode将nameNode的 fsimage,edit log文件复制到本地的检查点目录。
(3).secondaryNameNode载入fsimage文件,回放edit log,将其合并到fsimae,将新的fsimage文件压缩后写入磁盘
(4).secondaryNameNode将新的fsimage文件送回namenode,namenode在接受新的fsimage后,直接加载和应用该文件
(5).namenode将edit log.new更名为edit log.
默认情况下每小时发生一次,或者到namenode的edit log文件到达默认的64M,
fsimage保存了最新的元数据检查点。
edits保存自最新检查点后的命名空间的变化。
fsimage文件中包含文件metadata信息,不包含文件块位置的信息。
namenode把文件块位置信息存储在内存中,这些位置信息是,在 datanode加入集群的时候,
namenode询问datanode得到的,并且间断的更新
从最新检查点后,hadoop将对每个文件的操作都保存在edits中,为避免edits不断增大,secondary namenode就会周期性合并fsimage和edits成新的fsimage,edits再记录新的变化
这种机制有个问题:因edits存放在Namenode中,当Namenode挂掉,edits也会丢失,导致利用secondary namenode恢复Namenode时,会有部分数据丢失

hdfs读取文件和写入文件
一 数据读取
例如 hdfs中存储了一个文件/user/data.txt,hdfs客户端要读取该文件,
1.通过验证机制是否允许访问
2.namenode提供hdfs客户端这个文件的第一个数据块的标号已经保存有该数据库块的datanode列表,主意这个列表是datanode与hdfs客户端的距离排序的,有了数据块标号以及datanode,hdfs直接访问最合适的datanode,读取所需的数据块。该过程会一直重复直到该文件所有数据块读取完成。、

二:数据写入
以hdfs客户端向hdfs创建一个新文件为例

当hdfs客户端发送请求,这个请求将被发送到namenode,并建立该文件的元数据,这个新建立的文件元数据并未和任何数据块相关联,此时hdfs客户端会收到响应,当客户端将数据写入流时,数据会被自动拆分成数据包,并将数据包保存在内存队列中,客户端有一个独立的线程,从队列中读取数据包,并向namenode请求一组datanode,hdfs客户端将直接连接到列表中的的第一个datanode,而该datanode又连接到第二个datanode,第二个又连接第三个,如此就建立了数据块的复制管道,hdfs客户端应用程序维护着一个列表,记录哪些包还未收到确认消息。
hdfs 数据完整性
正在写数据的hdfs客户端将数据和校验和发送到由一系列datanode组成的复制管道,管道中最后一个datanode负责验证校验和。
hdfs客户端从datanode读取数据时,也会验证校验和,将他们与datanode中存储的校验和进行比较,每个datanode均保存有一个用于校验和日志,客户端成功校验一个数据块后,会告诉datanode,datanode由此更新日志。
不只是客户端在读取数据和写入数据时会验证校验和,每个datanode也会在一个后台线程运行dataBlockScanner,定期验证存储在这个datanode上的所有数据块。

















 2704
2704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









