




 本文详细解析了Hadoop中WordCount程序的工作原理及流程,包括输入格式、映射、组合、分区、归约等关键步骤。
本文详细解析了Hadoop中WordCount程序的工作原理及流程,包括输入格式、映射、组合、分区、归约等关键步骤。
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.util.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Reducer.*;
import org.apache.hadoop.mapreduce.lib.input.*;
import org.apache.hadoop.mapreduce.lib.output.*;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.lib.partition.*;
public class WordCount {
public static class MyMapper extends Mapper<Object,Text, Text,IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value,Context context) throws IOException,InterruptedException{
StringTokenizer st=new StringTokenizer(value.toString());
while(st.hasMoreTokens()){
String str=st.nextToken();
word.set(str);
context.write(word, one);
System.out.println(str+"="+one.get());
}
}
}
public static class MyReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
private IntWritable result = new IntWritable();
public void reduce(Text key,Iterable<IntWritable> values ,Context context) throws IOException,InterruptedException{
int sum=0;
for(IntWritable val:values)
{
sum+=val.get();
}
System.out.println(key+"="+sum);
result.set(sum);
context.write(key,result);
}
}
public static void main(String [] args) throws Exception
{
Configuration conf= new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job=new Job(conf,"wordcount" );
/**InputFormat类的作用是将输入的数据分割成splits,并将splits进一步拆成<K,V>
*可以通过setInputFormatClass()方法进行设置
*默认为TextInputFormat.class,默认情况可以不写
**/
job.setInputFormatClass(TextInputFormat.class);
/**
*Mapper类的作用是实现map函数,将splits作为输入生成一个结果
*可以通过setMapperClass()方法进行设置
*默认为Mapper.class,默认情况可以不写,此时输入即输出
*/
job.setMapperClass(MyMapper.class);
/**
* 设置Mapper输出的key的类型
*/
job.setMapOutputKeyClass(Text.class);
/**
* 设置Mapper输出的value的类型
*/
job.setMapOutputValueClass(IntWritable.class);
/**
* Combiner类的作用是实现combine函数,将mapper的输出作为输入,合并具有形同key值得键值对
* 可以通过setCombinerClass()方法进行设置
* 默认为null,默认情况不写,此时输入即输出
*/
job.setCombinerClass(MyReducer.class);
/**
* Partitioner类的作用是实现getPartition函数,用于在洗牌过程中将由Mapper输入的结果分成R份,每份交给一个Reducer
* 可以通过setPartitionerClass()方法进行设置
* 默认为HashPartitioner.class,默认情况可以不写,此时输入即输出
*/
job.setPartitionerClass(HashPartitioner.class);
/**
* Reducer类的作用是实现reduce函数,将有combiner的输出作为输入,得到最终结果
* 可以通过setReducerClass()方法进行设置
* 默认为Reducer.class,默认情况可以不写,此时输入即输出
*/
job.setReducerClass(MyReducer.class);
/**
* OutputFormat类,负责输出最终结果
* 可以通过setOutputFormatClass()方法进行设置
* 默认TextOutputFormat.class,默认情况可以不写,此时输入即输出
*/
//job.setOutputFormatClass(TextOutputFormat.class);
/**
* 设置reduce()输出的key的类型
*/
job.setOutputKeyClass(Text.class);
/**
* 设置reduce()输出的value的类型
*/
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.out.println("运行啦");
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
我们先来看main函数,以便了解hadoop的MapReduce的过程,假设输入为两个文件

InputFormat类将输入文件划分成多个splits,同时将这些splits转化为<K,V>的形式,如下,可以发现,当使用默认的TextInputFormat进行处理的时候,K为偏移量,V为每行的文本。

接着map()方法
对以上结果进行处理,根据MyMapper中的map方法,得到以下结果:
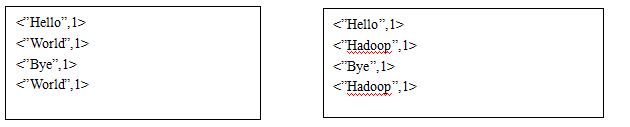
接下来Mapper框架对以上结果进行处理,根据key值进行排序,并合并成集合,得到以下结果:
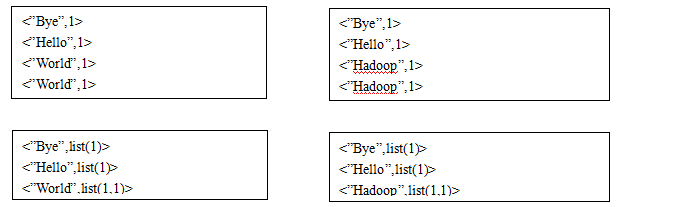
接下来combine类对以上结果进行处理(实际上combine是一个本地的reducer,所以用MyReducer给他复制,见文章最后)得到结果如下:

接下来Reducer框架对其进行处理,结果如下:
接下来reduce()方法进行处理,结果如下:
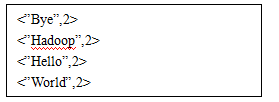
以上是wordcount程序执行的全过程,通过wordcount的代码,我们了解了MapReduce框架的执行流程,如下
InputFormat>>map()方法>>Mapper框架>>Combiner类>>Partitioner类>>Reducer框架>>reduce()方法
以上的每个步骤,不设置具体的类时都会有个默认的类,除了InputFormat类以外,其他类的默认类都是输入即输出,但是InputFormat的默认类是输出为<K,V>
因此,对于wordcount程序来说,如果都采用默认类的话,输出应该为

下面来说说Combiner类,本质上是一个本地的Reducer类。其设计初衷是在本地将需要reduce操作的数据合并,以减少不必要的通信代价,以提高hadoop的运行性能。
但值得注意的是,并不是所有的mapreduce程序都可以将reduce过程移植到本地进行combine,这需要在逻辑上考虑这种移植是否可行!要想 进行本地reduce(combine),一个必要的条件是,reduce的输入输出格式必须一样!比如,对于wordcount程序,combine是 可行的,combine的输出(实际上是reduce的输出)与reduce的输入吻合。因此我们才可以有 job.setCombinerClass(MyReducer.class);
实际上,在Combiner和Reducer之间还有一个Partitioner类,该类用于在shuffle过程中将中间值分成R份,每份由一个Reducer负责。通过使用job.setPartitionerClass()来进行设置,默认使用HashPartitioner类。

















 1241
1241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









