 Linux中终止进程的方法
Linux中终止进程的方法




 本文介绍如何在Linux系统中使用kill命令终止进程。包括查找进程ID(PID),发送默认信号和强力信号,以及批量终止多个进程的方法。适用于新手用户。
本文介绍如何在Linux系统中使用kill命令终止进程。包括查找进程ID(PID),发送默认信号和强力信号,以及批量终止多个进程的方法。适用于新手用户。
Iam a new Linux system user. How do I kill process on Linux based server using command line options? How can I kill running process on Unix?
Linux and Unix-like operating system come with thekill command to terminates stalled or unwanted processeswithout having to log out or restart the server.
The kill command sends the specified signal such as kill process to the specified process or process groups. If no signal is specified, the TERM signal is sent. Please note that kill command can be internal as part of modern shells built-in function or external located at /bin/kill. Usage and syntax remain similar regardless internal or external kill command.
| Tutorial details | |
|---|---|
| Difficulty | Easy(rss) |
| Root privileges | Yes |
| Requirements | kill |
| Estimated completion time | 10 minutes |
A list of commonTermsingles
Linux and Unix-like operating system supports the standard terminate signals listed below:
- SIGHUP(1) - Hangup detected on controlling terminal or death of controlling process. Use SIGHUP toreload configuration files and open/close logfiles.
- SIGKILL(9) - Kill signal. Use SIGKILL as alast resortto kill process. This will not save data or cleaning kill the process.
- SIGTERM(15) - Termination signal. This isthe default and safest wayto kill process.
What is a PID?
A Linux or Unix process is running instance of a program. For example, Firefox is a running process if you are browsing the Internet. Each time you start Firefox browser, the system is automatically assigned a unique process identification number (PID). A PID is automatically assigned to each process when it is created on the system. To find out PID of firefox or httpd process use the following command:
pidof httpd pidof apache2 pidof firefox
OR use the combination ofandgrep command:
ps aux | grep httpd ps aux | grep apache2 ps aux | grep firefox
Sample outputs:
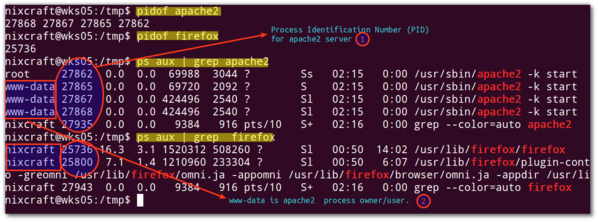
Fig.01: Find the process ID (PID) of a running firefox program and apache2 server.
kill command syntax
The syntax is:
kill [signal] PID kill -15 PID kill -9 PID kill -SIGTERM PID kill [options] -SIGTERM PID
What Linux or Unix permissions do I need to kill a process?
Rules are simple:
- You can kill all your own process.
- Only root user can kill system level process.
- Only root user can kill process started by other users.
kill command examples
In this example, I am going to kill lighttpd server.
Step #1: Find out the PID (process id)
Use the ps or pidof command to find out PID for any program. For example, if process name is lighttpd, you can use any one of the following command to obtain process ID:
pidof lighttpd
Sample outputs:
3486
OR
ps aux | grep lighttpd
Sample outputs:
lighttpd 3486 0.0 0.1 4248 1432 ? S Jul31 0:00 /usr/sbin/lighttpd -f /etc/lighttpd/lighttpd.conf lighttpd 3492 0.0 0.5 13752 3936 ? Ss Jul31 0:00 /usr/bin/php5-cg
Step #2: kill the process using a PID
The PID # 3486 is assigned to the lighttpd process. To kill the lighttpd server, you need to pass a PID as follows:# kill 3486
OR$ sudo kill 3486
This will terminate a process with a PID of 3486.
How do I verify that the process is gone / killed?
Use the ps or pidof command:$ ps aux | grep lighttpd
$ pidof lighttpd
A note about sending stronger signal # 9 (SIGKILL)
If no signal specified in the kill command, signal # 15 (SIGTERM), is sent by default. So thekill 3486command is same as the following command:# kill -15 3486
# kill -SIGTERM 3486
OR$ sudo kill -15 3486
$ sudo kill -SIGTERM 3486
Sometime signal # 15 is not sufficient. For example, lighttpd may not be killed by signal #15 due to open sockets. In that case process (PID) # 3486 would be killed with the powerful signal # 9:# kill -9 3486
# kill -SIGKILL 3486
OR$ sudo kill -9 3486
$ sudo kill -SIGKILL 3486
Where,
- -9or-SIGKILL- A special kill signal that nearly guarantee to kill the process with the iron fist.
How can I kill two or more PIDs?
The syntax is as follows to kill two or more PIDs as required can be used in a single command:
kill pid1 pid2 pid3 kill -15 pid1 pid2 pid3 kill -9 pid1 pid2 pid3 kill -9 3546 5557 4242
Say hello to killall command
This is a Linux only command. to kill processes by name. So no need to find the PIDs using the 'pidof process' or 'ps aux | grep process' command. Do not use killall command on Unix operating systems. This is a Linux specific command.
The syntax is
killall Process-Name-Here
To kill the lighttpd server, enter:# killall -15 lighttpd
OR# killall -9 lighttpd
To kill the Firefox web-browser process, enter:# killall -9 firefox-bin
As I said earlier, the killall command on UNIX-like system does something else. It kills all process and not just specific process. Do not use killall on UNIX system.
http://www.cyberciti.biz/faq/kill-process-in-linux-or-terminate-a-process-in-unix-or-linux-systems/

















 838
838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









