



 本文探讨了DbUtils中MapHandler处理聚合函数时的问题,即使用as关键字后,列名无法正确识别。通过分析源代码,找到了解决方案,并提出重载处理方式的建议。
本文探讨了DbUtils中MapHandler处理聚合函数时的问题,即使用as关键字后,列名无法正确识别。通过分析源代码,找到了解决方案,并提出重载处理方式的建议。
非常喜欢这种轻量级的JDBC封装,比起Hibernate和iBatis,可以非常自由和灵活地运用和自行二次封装,由于dbutils的
BeanHandler转换方式采取了反射技术,在性能上肯定有所损失,所以项目中基本上都使用MapHandler方式来转换数据,当然就是自己写的代
码多一点,也无所谓。一般的查询、子查询、联合查询、包括视图查询等等都很正常,但是发现一个比较小的问题,就是在使用聚合函数的场所,例
如:select user_type, count(*) as count from `user` group by
user_type这种类型查询的时候,MapHandler方式不起作用,as列都变成key为空串的K-V对,导致有许多地方使用
map.get("")代码的情况出现,这种写法当然是不太好的,容易出问题。
鉴于前面没有时间了解,就都粗略使用了上面那种粗暴的map.get("")来处理,最好的情况是让dbutils组件能自动识别到as类型的列名。于是有空了就专门看了看它的源代码,发现最主要的一段代码如下:

 public
Map
<
String, Object
>
toMap(ResultSet rs)
throws
SQLException
public
Map
<
String, Object
>
toMap(ResultSet rs)
throws
SQLException
 {
{2
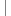 Map
<
String, Object
>
result
=
new
CaseInsensitiveHashMap();
Map
<
String, Object
>
result
=
new
CaseInsensitiveHashMap();3
ResultSetMetaData rsmd
=
rs.getMetaData();4
int
cols
=
rsmd.getColumnCount();5
6

 for
(
int
i
=
1
; i
<=
cols; i
++
)
{
for
(
int
i
=
1
; i
<=
cols; i
++
)
{7
result.put(rsmd.getColumnName(i), rs.getObject(i));8
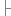 }
}
9
10
return
result;11
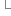 }
}
CaseInsensitiveHashMap是dbutils自定义的一个Map,忽略键大小写的K-V字典,但是key使用的是
ResultSetMetaData.getColumnName(),我想问题大概出在这里,于是认真翻了翻java的api文档(开发做久了容易遗忘
基础),果然,原来getColumnName()
是:获取指定列的名称;
而as关键字之后,使列名称变成用于显示的意义,这个时候应该使用getColumnLabel
():获取用于打印输出和显示的指定列的建议标题。建议标题通常由 SQL AS
子句来指定。如果未指定 SQL AS
,则从 getColumnLabel
返回的值将和 getColumnName
方法返回的值相同
。自己手动试验了一下,果然如所料,问题就出在这里。
所以呢,如果想要dbutils在自动转换Map及MapList时能识别聚合函数的列名,那么最好的做法就是重载这种方式,懒一点的,你就干脆修改上面
那段代码,让它判断是否使用了as关键字。个人暂时搞不清楚官方为什么没有考虑这一步,有时间再思考一下!
刚进场的时候戏就落幕

















 1440
1440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









