




 本文详细介绍了Java中Map接口及其主要实现类的特点与应用场景,包括HashMap、LinkedHashMap、TreeMap、EnumMap、IdentityHashMap、ConcurrentHashMap及ConcurrentSkipListMap。探讨了每种Map的数据结构、构造方法、内部实现细节及最佳实践。
本文详细介绍了Java中Map接口及其主要实现类的特点与应用场景,包括HashMap、LinkedHashMap、TreeMap、EnumMap、IdentityHashMap、ConcurrentHashMap及ConcurrentSkipListMap。探讨了每种Map的数据结构、构造方法、内部实现细节及最佳实践。
Map
表示键与值的一对一关系,键不允许重复。通过键可以快速找到值。
API:
| 方法摘要 | |
|---|---|
void | clear() 从此映射中移除所有映射关系(可选操作)。 |
boolean | containsKey(Object key) 如果此映射包含指定键的映射关系,则返回 true。 |
boolean | containsValue(Object value) 如果此映射将一个或多个键映射到指定值,则返回 true。 |
Set<Map.Entry<K,V>> | entrySet() 返回此映射中包含的映射关系的 Set 视图。 |
boolean | equals(Object o) 比较指定的对象与此映射是否相等。 |
V | get(Object key) 返回指定键所映射的值;如果此映射不包含该键的映射关系,则返回 null。 |
int | hashCode() 返回此映射的哈希码值。 |
boolean | isEmpty() 如果此映射未包含键-值映射关系,则返回 true。 |
Set<K> | keySet() 返回此映射中包含的键的 Set 视图。 |
V |
如果此映射以前包含一个该键的映射关系,则用指定值替换旧值 |
void | putAll(Map<? extends K,? extends V> m) 从指定映射中将所有映射关系复制到此映射中(可选操作)。 |
V | remove(Object key) 如果存在一个键的映射关系,则将其从此映射中移除(可选操作)。 |
int | size() 返回此映射中的键-值映射关系数。 |
Collection<V> | values() 返回此映射中包含的值的 Collection 视图。 |
Map 的子类:
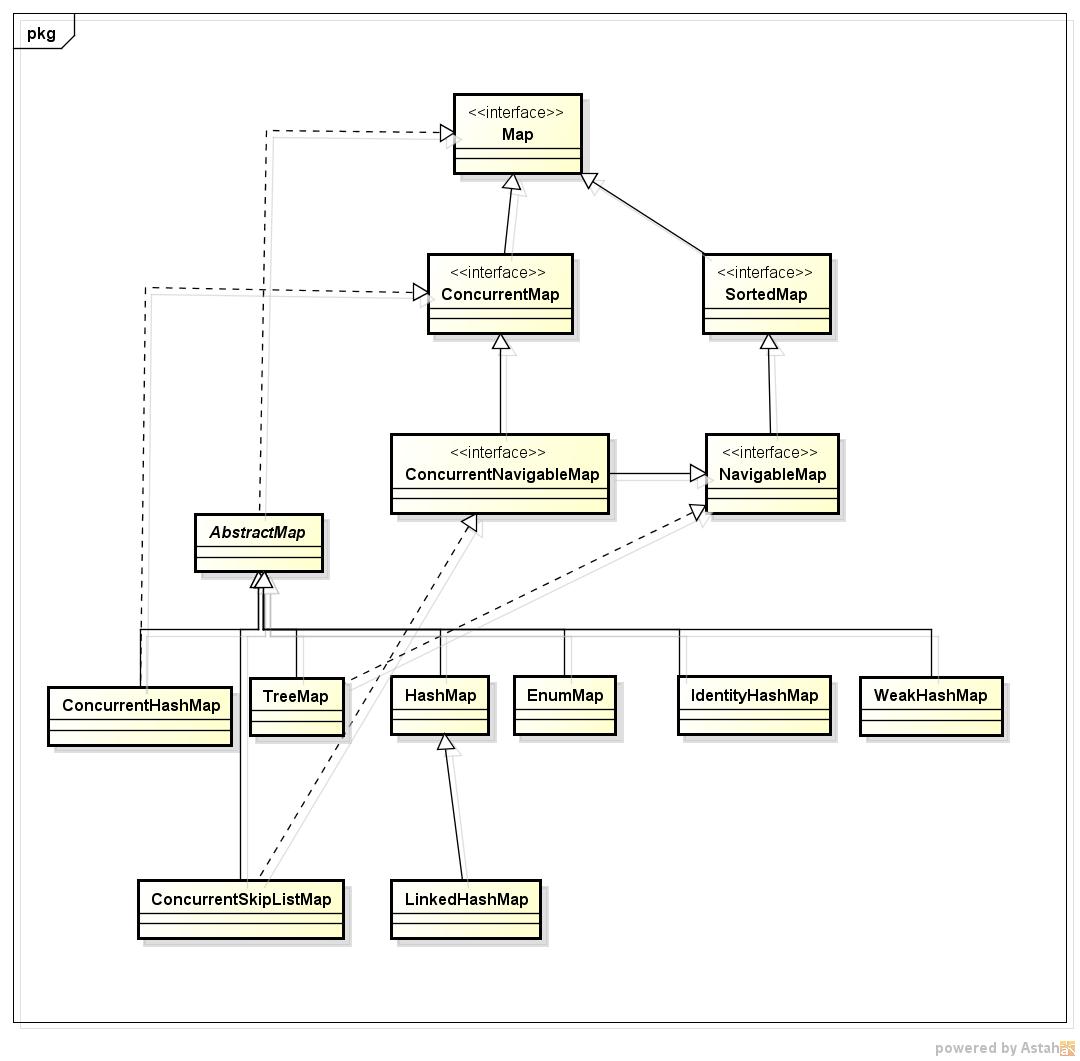
HashMap :非线程安全的,允许key或value 为null,不支持排序。key相等的判断条件:hashcode和equals 都相等。
LinkedHashMap:在 HashMap 的基础上提供了按插入顺序排序的功能。
TreeMap: 非线程安全的, 允许key或value 为null,支持自然排序或指定 的Comparator进行排序。key相等的判断条件:key.compareTo(map里面的key)==0 或Comparator.compare(key, map里面的) ==0
EnumMap:转为key为枚举类准备的MAP,key只能属于同一个枚举类。非线程安全的,不允许key为null,但允许value为null。 key相等的判断条件:key.ordinal() == map里面的 key.ordinal()
IdentityHashMap:非线程安全的,key相等的判断条件: 通过==(直等)来判断
ConcurrentHashMap:线程安全,不允许key或value为null,不支持排序,key相等的判断条件:hashcode和equals 都相等。
ConcurrentSkipListMap:线程安全,不允许key或value为null,支持 排序,key相等的判断条件:key.compareTo(map里面的key)==0 或Comparator.compare(key, map里面的) ==0
Map的选择:
单线程下:
仅需要记录两个对象的映射关系就用HashMap,
需要按put时顺序遍历就用LinkedHashMap,
需要进行key的大小排序就用TreeMap
key中要放一个枚举类型的所有实例,就用EnumMap.
只能用key对象(逻辑上相等不行),才能取出value对象,则用IdentityHashMap。
多线程下:
仅需要记录两个对象的映射关系就用ConcurrentHashMap,
还需要进行key的大小排序就用 ConcurrentSkipListMap
也可以使用Collections.synchronizedMap(Map<K,V> map)对任何一个非线程安全的Map进行包装而达到线程安全的目的,但迭代时必须同步迭代器,多线程频繁该问时,性能没有优势。
{
HashMap:记录两个对象之间的映射关系,不在乎遍历时的随机顺序问题,以key对象的逻辑上(数据值)相等来查找value对象时使用,key对象需要实现hashCode和equals 。
LinkedHashMap: 记录两个对象之间的映射关系,按put时先后顺序遍历,以key对象的逻辑上(数据值)相等来查找value对象时使用,key对象需要实现hashCode和equals 。
TreeMap:记录两个对象之间的映射关系,按key的从小到大顺序遍历,以key对象compareTo(treeMap里的key)==0 来查找value对象时使用,key对象需要 Comparable接口。
EnumMap:记录一个枚举类的所有实例与其它对象的对应、按枚举实例的声明顺序遍历 时使用。
IdentityHashMap:记录两个对象之间的映射关系,只有与key对象是同一个实例,才能取出对应的value对象。
}
HashMap :
构建器: HashMap(int initialCapacity, float loadFactor)
构造一个带指定初始容量和加载因子的空 HashMap。
默认的 initialCapacity 为16,默认的 loadFactor 为0.7。
当HashMap中添加的元素数(HashMap.size())>= initialCapacity * loadFactor时, HashMap自动扩大容量,大约为原容量的2倍。如果较多数据存入HashMap,未设定 initialCapacity ,则HashMap 可能会多次扩充容量,多消耗性能。
key为自定义的类,需要实现equqls 和 hashCode 方法。
内部数据结构:
1.数组: Entry[] table = new Entry[capacity]
2. 链表:Entry 对象是个链表,通过next属性指向下一个 Entry :
Entry<K,V> {
final K key;
V value;
Entry<K,V> next;//下一个元素
final int hash;//key的hashCode值
}
put(key,value)时 ,根据key的hashCode 计算出table的数组下标i,如果table[i]已存在,则对table[i]即 Entry链表进行比较 ,如果 entry.hash == key.hash && entry.key.equals(key) 即key的hashCode和equals都相等,则认为key相同,则将value存入entry.value,即替换旧value.
Entry链表中没有相同的key,则新生成Entry加入链表。
Entry链表存在的原因:多个hashCode计算出的table的数组下标相同。
LinkedHashMap :
在HashMap的基础上,记录了元素的添加顺序,keySet(),entrySet() 返回的Iterator 按添加顺序排序:
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
private void remove() {
before.after = after;
after.before = before;
}
/**
* Inserts this entry before the specified existing entry in the list.
*/
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
}
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<K,V>(hash, key, value, old);
table[bucketIndex] = e;
e.addBefore(header);//记录顺序
size++;
}
TreeMap:
TreeMap 提供对插入的元素排序的功能
keySet().iterator 或 entrySet().iterator 排key类由小到大顺序排列。
key 需要实现Comparable接口 或者提供Comparator类完成对KEY的自定义排序。
key 不需要实现equals 和 hashcode方法,get(key) 和containsKey(key) 方法是根据 key.compareTo(treeMap里的key)==0 或 Comparator.compare(key,treeMap里的key)==0 来判断的。
构建器:
TreeMap() 使用键的自然顺序构造一个新的、空的树映射。 |
TreeMap(Comparator<? super K> comparator) 构造一个新的、空的树映射,该映射根据给定比较器进行排序。 |
TreeMap(Map<? extends K,? extends V> m) 构造一个与给定映射具有相同映射关系的新的树映射,该映射根据其键的自然顺序 进行排序。 |
TreeMap(SortedMap<K,? extends V> m) 构造一个与指定有序映射具有相同映射关系和相同排序顺序的新的树映射。 |
内部数据结构:
红黑树(一种二叉树):树的最左侧存的是最小key的Entry,最右侧存的是最大key的Entry.
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left = null;//指向小key
Entry<K,V> right = null;//指向大key
Entry<K,V> parent;
boolean color = BLACK;
}
put 代码:
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {
// TBD:
// 5045147: (coll) Adding null to an empty TreeSet should
// throw NullPointerException
//
// compare(key, key); // type check
root = new Entry<K,V>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<K,V>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
TreeMap提供的方法API:
Map.Entry<K,V> | ceilingEntry(K key) 返回一个键-值映射关系,它与大于等于给定键的最小键关联;如果不存在这样的键,则返回 null。 |
K | ceilingKey(K key) 返回大于等于给定键的最小键;如果不存在这样的键,则返回 null。 |
NavigableSet<K> | descendingKeySet() 返回此映射中所包含键的逆序 NavigableSet 视图。 |
NavigableMap<K,V> | descendingMap() 返回此映射中所包含映射关系的逆序视图。 |
Map.Entry<K,V> | firstEntry() 返回一个与此映射中的最小键关联的键-值映射关系;如果映射为空,则返回 null。 |
Map.Entry<K,V> | floorEntry(K key) 返回一个键-值映射关系,它与小于等于给定键的最大键关联;如果不存在这样的键,则返回 null。 |
K | floorKey(K key) 返回小于等于给定键的最大键;如果不存在这样的键,则返回 null。 |
SortedMap<K,V> | headMap(K toKey) 返回此映射的部分视图,其键值严格小于 toKey。 |
NavigableMap<K,V> | headMap(K toKey, boolean inclusive) 返回此映射的部分视图,其键小于(或等于,如果 inclusive 为 true)toKey。 |
Map.Entry<K,V> | higherEntry(K key) 返回一个键-值映射关系,它与严格大于给定键的最小键关联;如果不存在这样的键,则返回 null。 |
K | higherKey(K key) 返回严格大于给定键的最小键;如果不存在这样的键,则返回 null。 |
Map.Entry<K,V> | lastEntry() 返回与此映射中的最大键关联的键-值映射关系;如果映射为空,则返回 null。 |
Map.Entry<K,V> | lowerEntry(K key) 返回一个键-值映射关系,它与严格小于给定键的最大键关联;如果不存在这样的键,则返回 null。 |
K | lowerKey(K key) 返回严格小于给定键的最大键;如果不存在这样的键,则返回 null。 |
NavigableSet<K> | navigableKeySet() 返回此映射中所包含键的 NavigableSet 视图。 |
Map.Entry<K,V> | pollFirstEntry() 移除并返回与此映射中的最小键关联的键-值映射关系;如果映射为空,则返回 null。 |
Map.Entry<K,V> | pollLastEntry() 移除并返回与此映射中的最大键关联的键-值映射关系;如果映射为空,则返回 null。 |
NavigableMap<K,V> | subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive) 返回此映射的部分视图,其键的范围从 fromKey 到 toKey。 |
SortedMap<K,V> | subMap(K fromKey, K toKey) 返回此映射的部分视图,其键值的范围从 fromKey(包括)到 toKey(不包括)。 |
SortedMap<K,V> | tailMap(K fromKey) 返回此映射的部分视图,其键大于等于 fromKey。 |
NavigableMap<K,V> | tailMap(K fromKey, boolean inclusive) 返回此映射的部分视图,其键大于(或等于,如果 inclusive 为 true)fromKey。 |
Comparator<? super K> | comparator() 返回对此映射中的键进行排序的比较器;如果此映射使用键的自然顺序,则返回 null。 |
Set<Map.Entry<K,V>> | entrySet() 返回在此映射中包含的映射关系的 Set 视图。 |
K | firstKey() 返回此映射中当前第一个(最低)键。 |
SortedMap<K,V> | headMap(K toKey) 返回此映射的部分视图,其键值严格小于 toKey。 |
Set<K> | keySet() 返回在此映射中所包含键的 Set 视图。 |
K | lastKey() 返回映射中当前最后一个(最高)键。 |
SortedMap<K,V> | subMap(K fromKey, K toKey) 返回此映射的部分视图,其键值的范围从 fromKey(包括)到 toKey(不包括)。 |
SortedMap<K,V> | tailMap(K fromKey) 返回此映射的部分视图,其键大于等于 fromKey。 |
Collection<V> | values() 返回在此映射中所包含值的 Collection 视图。 |
EnumMap:
以枚举类型为KEY的Map. 专为枚举类型使用。 Map中KEY只能源于同一个枚举类。
构建器:
创建一个具有指定键类型的空枚举映射。 keyType为枚举类Class对象。
内部数据结构:
K[] keyUniverse :保存key的数组。由于枚举类实例数固定的,在由构建器初始化时,能够获得枚举类实例个数从而定义数组大小。
Object[] vals:key对应的 value.
key 如何对应到数组中:
int index = ((Enum)key).ordinal();
ordinal() 方法返回该枚举实例在枚举类中的声明顺序序号。第一个实例枚举序号为0,以此类推。
IdentityHashMap:
key是否相同判断: 通过==(直等)来判断
内部使用数据结构:
Object[] table ,数组下标为偶数存key对象, 下标+1存该key对应的value.
key 如何对应的数组下标上:
通过key的默认hashCode()方法的获得 hashCode ,根据hashCode再计算出数组下标:
private static int hash(Object key, int length) {
int h = System.identityHashCode(key);
// Multiply by -127, and left-shift to use least bit as part of hash
return ((h << 1) - (h << 8)) & (length - 1);
}
不同key对应数组同一下标,如何存储:
后put的key ,计算出的下标+2,判断是否为null,不存null则存保存在该位置 ,否则下标继续下移二位。
put 方法:
public V put(K key, V value) {
Object k = maskNull(key);
Object[] tab = table;
int len = tab.length;
int i = hash(k, len);//根据key 计算出数组下标
Object item;
while ( (item = tab[i]) != null) {
if (item == k) {//相同的key 则覆盖value
V oldValue = (V) tab[i + 1];
tab[i + 1] = value;
return oldValue;
}
i = nextKeyIndex(i, len);//数组下标下移两位
}
modCount++;
tab[i] = k;//不为空则存上
tab[i + 1] = value;
if (++size >= threshold)
resize(len); // len == 2 * current capacity.
return null;
}
V |
相当于原子的执行下面的代码: if (!map.containsKey(key)) return map.put(key, value);
else
return map.get(key); |
| |
boolean |
相当于原子的执行: if (map.containsKey(key) && map.get(key).equals(value)) {
map.remove(key);
return true;
} else return false; |
V |
相当于原子的执行: if (map.containsKey(key)) {
return map.put(key, value);
} else return null; |
boolean |
相当于原子的执行: if (map.containsKey(key) && map.get(key).equals(oldValue)) {
map.put(key, newValue);
return true;
} else return false; |
ConcurrentSkipListMap:
与TreeMap 类似,但支持并发操作。线程安全的。

















 1001
1001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









