






 本文深入探讨了Java集合中List的子集,包括ArrayList和LinkedList的实现方式、结构性能分析以及如何利用迭代器提高效率。通过源码解析,详细解读了add、remove、get等操作的时间复杂度,并提供了实际测试代码验证理论分析。
本文深入探讨了Java集合中List的子集,包括ArrayList和LinkedList的实现方式、结构性能分析以及如何利用迭代器提高效率。通过源码解析,详细解读了add、remove、get等操作的时间复杂度,并提供了实际测试代码验证理论分析。
下面我将使用jdk1.7.79版本的jdk从继承结构,实现方式,结构性能分析,扩展等几个方面聊一下java集合中List的子集,如果有什么不对的地方欢迎拍砖。
一、继承结构
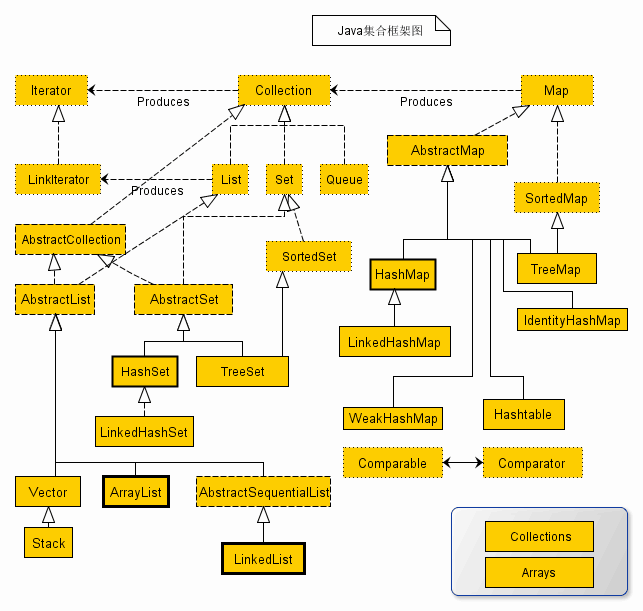
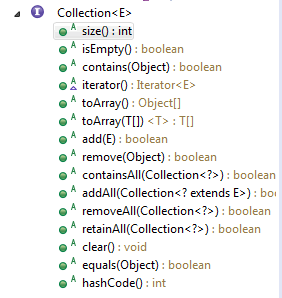
众所周知List集合的顶级接口是Collection,它定义了List,Set集合的共有操作:
但是应该会有相当一部分人没有注意过,Collection还有父接口Iterable,外表看上去它和我们一直在使用的Iterator接口很像,其实功能也有类似之处。都是迭代。并不是随随便便一个类就可以被增强for循环迭代的,要想被迭代必须实现Iterable接口,然后复写iterator()方法才可以:
public class B implements Iterable<Integer> {
private int[] b = { 1, 2, 3, 4, 5, 6 };
private int index = 0;
@Override
public Iterator<Integer> iterator() {
return new Iterator<Integer>() {
@Override
public boolean hasNext() {
return index < b.length;
}
@Override
public Integer next() {
return b[index++];
}
@Override
public void remove() {
// TODO
}
};
}
public static void main(String[] args) {
for (int i : new B()) {
System.out.print(i + ", ");//1, 2, 3, 4, 5, 6,
}
}
}现在也可以明白ArrayList,LinkedList中iterator方法的由来了。
先来看一下ArrayList和LinkedList他们到Collection接口之间还有几个抽象类,这些抽象类只是定义了一些子类的共有操作而已,在子类中找不到的方法,可以从这些抽象类中找到。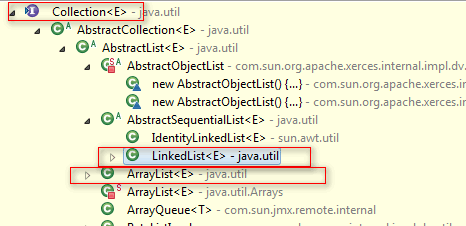
二、实现方式
ArrayList:
从名字也可以看出来它底层就是数组实现的:

transient关键字的作用是:实现Serializable接口的类在实现序列化时, transient关键字修饰的值不会被序列化。也就是说序列化之后这个字段的值就丢失了。
ArrayList集合中有那么多方法肯定不能注意分析了,在此会挑主要的追一下源码,如果有兴趣的朋友可以把其他的也追了。先看一下add(E e):
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return <tt>true</tt> (as specified by {@link Collection#add})
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
} 这里可以看出新插入的对象是被插入到数组最后的。千万不要忽视了之前的数组程度的安全检查:
private void ensureCapacityInternal(int minCapacity) {
if (elementData == EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}先在默认长度与传进来的长度之间作比较,取大值,然后:
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}modCount是个版本控制的变量,之后会讨论。判断数组长度是否需要扩充,如果需要扩充的话:
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}先将原来数组长度增加原来的一半,之后拷贝原数组到新数组。
再来看remove(Object o):
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}先将参数分情况讨论,看看是否为null,然后从起点开始遍历查找要删除的元素,单从这一点看时间复杂度为O(N),这很重要,之后性能分析分析的就是各操作的时间复杂度。从这一点上还可以看出ArrayList是支持null值的。如果删除了首次出现的元素就返回true,如果没有删除任何元素返回false。下面看一下怎么删除的
/*
* Private remove method that skips bounds checking and does not
* return the value removed.
*/
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}从删除索引处之后所有元素向前拷贝一位,将最后一位置为null。看源码不仅要学接口,还需要看细节,虽然最坏时间复杂度也是O(N)但是如此优雅的代码,以后还是要在自己程序中认真效仿的。
下一个再看iterator():
/**
* Returns an iterator over the elements in this list in proper sequence.
*
* <p>The returned iterator is <a href="#fail-fast"><i>fail-fast</i></a>.
*
* @return an iterator over the elements in this list in proper sequence
*/
public Iterator<E> iterator() {
return new Itr();
}它返回一个实现了Iterator接口的内部类。这也是增强for循环和Iterator对象调用的地方。个人感觉有必要先介绍其中的三个字段:
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;cursor:光标指向下一个要返回的元素。
lastRet:当前返回的元素。
expectedModCount:缓存集合当前版本。
现在有必要先解释一下modCount字段了。在ArrayList初始化时modCount字段为0即版本为0,然后add,set,remove等改变集合状态的操作,在调用时都会调用 modCount++ 版本数+1。
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}在remove时会调用:
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}来检查迭代器缓存集合版本与集合当前版本是否一致,如果不一致就会抛ConcurrentModificationException这也就解释了我们在for循环中remove,或者add元素时会抛异常的现象。那么为什么在迭代器中不会呢?
仔细查看上面的remove方法没有发现对版本字段的改变。所以即操作了集合还不会抛异常。cursor和lastRet两个字段维护了remove方法在执行之后next方法会自动找到后一个元素输出的现象。这里不解释了,仔细看一下两个方法会明白的。再者就是remove一次之后,在next之前如果再remove的话就会抛IllegalStateException异常。在性能分析是还会发现Iterator设计不单单只有这些好处,它在性能方面也有很大的贡献。
listIterator暂且先不看了,它与LinkedList中的listIterator基本上是一样的,在解释LinkedList时再接着看。
LinkedList:
LinkedList的存储结构是双向链表,节点源码:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
还有三个分别表示头节点(first),尾节点(last),元素数量(size)的字段:
transient int size = 0;
/**
* Pointer to first node.
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* Pointer to last node.
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;先看一下add(E e):
public boolean add(E e) {
linkLast(e);
return true;
}不解释,再向下追:
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}如果还记着ArrayList实现的同样的方法时,不禁会被链表的魅力所折服。再看remove:
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}向下追:
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}无非是拆链,重组,size-1,版本+1操作,个人感觉x.item = null;还是很有必要的,它可以让垃圾回收器从GCRoots无法搜索到x.item所引用的对象,从而出发垃圾回收。下面看一下ListItr是怎么实现的。
private class ListItr implements ListIterator<E> {
private Node<E> lastReturned = null;
private Node<E> next;
private int nextIndex;
private int expectedModCount = modCount;
ListItr(int index) {
// assert isPositionIndex(index);
next = (index == size) ? null : node(index);
nextIndex = index;
}
public boolean hasNext() {
return nextIndex < size;
}
public E next() {
checkForComodification();
if (!hasNext())
throw new NoSuchElementException();
lastReturned = next;
next = next.next;
nextIndex++;
return lastReturned.item;
}
public boolean hasPrevious() {
return nextIndex > 0;
}
public E previous() {
checkForComodification();
if (!hasPrevious())
throw new NoSuchElementException();
lastReturned = next = (next == null) ? last : next.prev;
nextIndex--;
return lastReturned.item;
}
public int nextIndex() {
return nextIndex;
}
public int previousIndex() {
return nextIndex - 1;
}
public void remove() {
checkForComodification();
if (lastReturned == null)
throw new IllegalStateException();
Node<E> lastNext = lastReturned.next;
unlink(lastReturned);
if (next == lastReturned)
next = lastNext;
else
nextIndex--;
lastReturned = null;
expectedModCount++;
}
public void set(E e) {
if (lastReturned == null)
throw new IllegalStateException();
checkForComodification();
lastReturned.item = e;
}
public void add(E e) {
checkForComodification();
lastReturned = null;
if (next == null)
linkLast(e);
else
linkBefore(e, next);
nextIndex++;
expectedModCount++;
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
只要能理解前面四个字段的意思,这段代码就没有任何难度,感觉之前的解释如果全部看下来的话,这段代码也就没什么好解释的了。
三、结构性能
add:
ArrayList和LinkedList在add(E e)方法时都是将新元素加到了最后一个节点。并且两者都可以直接索引到最后一个节点。两个操作的时间复杂度都是常数级。再来看add(int index, E element)方法,ArrayList可以直接索引的index位置,但是拷贝数组是O(N)的时间复杂度,当然这是不考虑拷贝开销。LinkedList需要遍历查找位置时间复杂度也是O(N)。
remove:
ArrayList因为要遍历所有元素查找要删除的元素还要有一次拷贝数组,忽略拷贝的开销,它的最坏时间复杂度是O(N^2),LinkedList只需要一次遍历查找元素所以时间复杂度为O(N),
get:
ArrayList直接索引时间复杂度几乎没有,LinkedList需要一个遍历时间复杂度O(N)
下面来测一个比较好测的remove:
public class B {
public static void main(String[] args) {
List<String> s = new ArrayList<>();//4353
int i = 100000;
while (i-- > 0) {
s.add("" + i);
}
long l = System.currentTimeMillis();
i = 100000;
while (i-- > 0) {
s.remove("" + i);
}
System.out.println(s);
System.out.println(System.currentTimeMillis() - l);
}
}输出为:4347ms
public class B {
public static void main(String[] args) {
List<String> s = new LinkedList<>();//4353
int i = 100000;
while (i-- > 0) {
s.add("" + i);
}
long l = System.currentTimeMillis();
i = 100000;
while (i-- > 0) {
s.remove("" + i);
}
System.out.println(s);
System.out.println(System.currentTimeMillis() - l);
}
}输出为:52ms
同样的代码,只是换了容器差距就如此之大。
另一个测试:看下一段代码:
public class B {
public static void main(String[] args) {
List<String> s = new LinkedList<>();// 4353
int i = 2000000;
while (i-- > 0) {
s.add("" + i);
}
long l = System.currentTimeMillis();
i = 2000000;
while (i-- > 0) {
s.remove("" + i);
}
System.out.println(s);
System.out.println(System.currentTimeMillis() - l);
}
}输出:1655ms
使用迭代器:
public class B {
public static void main(String[] args) {
List<String> s = new LinkedList<>();// 4353
int i = 2000000;
while (i-- > 0) {
s.add("" + i);
}
long l = System.currentTimeMillis();
Iterator<String> it = s.iterator();
while (it.hasNext()) {
it.next();
it.remove();
}
System.out.println(s);
System.out.println(System.currentTimeMillis() - l);
}
}输出:233ms
为什么迭代器效果如此之大,是因为上边代码每一个remove都需要去遍历整个集合时间复杂度O(N^2)但是下面使用迭代器只遍历一次就行时间复杂读O(N)。
四、延伸
LinkedList实现队列:
public class MyQueue<T> extends AbstractQueue<T> {
private LinkedList<T> list = new LinkedList<>();
/**
* 入队
*/
@Override
public boolean offer(T e) {
return list.offer(e);
}
/**
* 出对
*/
@Override
public T poll() {
return list.poll();
}
/**
* 获取对首元素
*/
@Override
public T peek() {
return list.peek();
}
/**
* 迭代
*/
@Override
public Iterator<T> iterator() {
return list.iterator();
}
/**
* 大小
*/
@Override
public int size() {
return list.size();
}
}LinkedList实现Stack:
public class MyStack<E> {
private LinkedList<E> list = new LinkedList<>();
public MyStack() {
}
public void push(E item) {
list.push(item);
}
public E pop() {
return list.pop();
}
public E peek() {
return list.peek();
}
public boolean empty() {
return list.size() == 0;
}
public int search(Object o) {
return list.indexOf(o);
}
}

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









