



 港大深圳医院作为大型公立医院,为适应信息化发展趋势,决定自建专业、高效的邮件系统。针对需求,U-Mail工程师团队提供了包括设置网络访问权限、邮箱收发权限审核、全球收发保障及超强安全稳定性在内的完善解决方案,确保了信息数据的安全与流通。
港大深圳医院作为大型公立医院,为适应信息化发展趋势,决定自建专业、高效的邮件系统。针对需求,U-Mail工程师团队提供了包括设置网络访问权限、邮箱收发权限审核、全球收发保障及超强安全稳定性在内的完善解决方案,确保了信息数据的安全与流通。
客户案例:
港大深圳医院2007年11月奠基,是“十一五”期间深圳市政府投资兴建的最大规模公立医 院。港大医院医疗手段不断丰富,充分应用各种精密医疗仪器,为病患者提供优质服务。为了适应信息化发展趋势,与国际接轨,港大决定规划自建一套专业、高效 的邮件系统,因为各种电子化医疗数据的保存和分析应用,以及对外的学术交流和服务患者都非常需要应用企业邮箱。
需求分析:
1.港大医院企业邮箱对外公开,征求病患者意见和承担交流重任,容易垃圾邮件泛滥;
2.避免遭受网络病毒攻击和黑客入侵窃取数据,急需安全稳定邮件系统保证信息数据安全;
3.确保畅通无阻:因院方需不定期跟香港及海外医疗机构进行联席会议和学术交流;
4.医院重要财务、药品数据和病患者资料,在传递过程中需建立监控和审核机制;
5.数据得到妥善存储和备份很重要。
解决方案
面对这种多层次、全方位的要求,U-Mail工程师们经过多次会商,提供了一份完善的解决方案,
一、设置网络访问权限
U-MAIL结合港大医院网络结构,采用邮件服务器放置内网,通过端口映射对外开放邮件服务,从网络物理上隔离保护邮件服务器安全。拓扑如下:
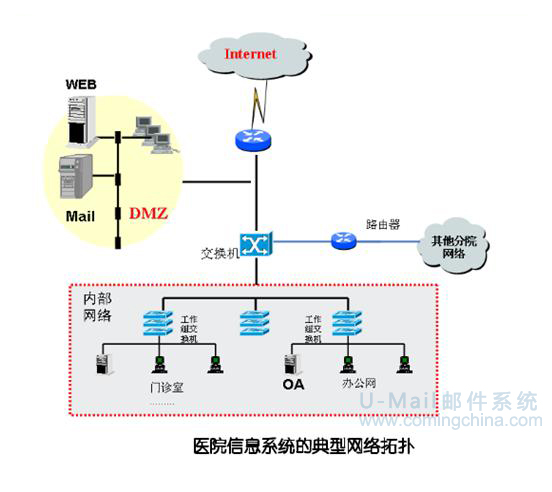
二、设置邮箱收发权限\签发审核邮件
涉及到病患者的医疗资料以及药品、财务等敏感信息,U-Mail邮件系统对内网用户设置关闭外网邮箱发送权限;同时对于某些需要对外的邮箱,进行外发邮件审核监控。规定要通过特定人员审核邮件内容,签发之后才能通过服务器外发,在源头就控制敏感信息流出。
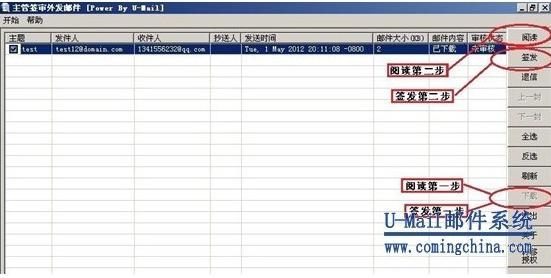
三、全球收发保障邮件全球送达
U-Mail邮件系统具备独一无二的全球收发保证功能(用户服务器的IP在收件人的垃圾邮件黑名单中,邮件照发不误),有力的保障了港大医院与外界交流的“精准到达”问题,使邮件畅邮全球无阻碍。
四、超强安全性和稳定性
U-Mail邮件系统集成了全球最好的杀毒引擎Commtouch,几乎可以100%过滤所有病毒;此外U-MAIL独有的“热点”技术和第四代基于行为识别的反垃圾引擎在保守设置下能过滤98%以上的垃圾邮件,做到了万无一失。
除了过硬的技术、强大的功能,U-Mail邮件系统的用户体验一流,在web界面就能完成大 多数操作,简单易用,而后续的维护和不断升级更是为您设身处地着想,尽量缩减费用:一次购买终身免费使用,终身免费升级。与同行业软件相比,它对与之配套 的硬件设备要求更低,但功能更全面,售后服务更体贴周到。

















 423
423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









