




1.数据基础表:
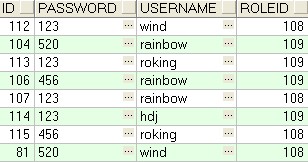
2.简单增删改语句:
insert into t_user(id,username,password,roleid) values(seq_user.nextval,'wind','520',109);delete from t_user t where t.roleid is null; update t_user t set t.username='saturn',t.password='456' where t.id=106;
3.查询语句:
1) count|distinct
select count(*) from t_user t; //统计表的记录数select distinct(t.username) from t_user t; //返回不重复的usernameselect count(distinct t.username||t.password) from t_user t;
//统计表不重复username和password的记录数select t.username,count(t.username) from t_user t group by t.username having count(t.username)>1 //统计重复username的:username及其重复次数
2)inner join | outer left join | outer right join
| 1 | A |
| 2 | B |
| 3 | C |
t_t2
| ColumnC | ColumnD |
| 2 | x |
| 4 | Y |
a)inner join
Select * from t_t1 a inner join t_t2 b on a.columna=b.columnc;
| columnA | columnB | columnC | columnD |
| 2 | B | 2 | X |
b)left outer join
Select * from t_t1 a left outer join t_t2 b on a.columna=b.columnc;
| columnA | columnB | columnC | columnD |
| 1 | A | ||
| 2 | B | 2 | X |
| 3 | C |
c)right outer join
Select * from t_t1 a right outer join t_t2 b on a.columna=b.columnc;
| columnA | columnB | columnC | columnD |
| 2 | B | 2 | X |
| 4 | Y |
d)连接三张表:
Select * from (tableA ainner join tableB b on a.id=b.id) inner join tableC c on c.id=tableA.id
3)oracle 分页查询:
select * from (select rownum,t.* from t_user t) where rownum>=1 and rownum<=5;select * from (select rownum rn,t.* from t_user t order by t.id desc) where rn between 4 and 20;
4)多表查询:
select t.* from t_user t,t_role t1 where t.roleid=t1.id and t1.rolename='管理员';
5)oracle时间的处理:
默认设置时间类型为:date 采用函数 to_date('2010-09-07','yyyy-mm-dd'),或 to_date('2010-9-5 10:00:00','yyyy-mm-dd HH24:MI:SS')
insert into t_log t values(hibernate_sequence.nextval,104,'新建用户114', to_date('2010-9-5 10:56:47','yyyy-mm-dd HH24:MI:SS'));
select t.* from t_log t where cdate between to_date('2010-09-05','yyyy-mm-dd') and to_date('2010-09-07','yyyy-mm-dd') 6)top N等问题:
select t.* from t_user t where rownum<=3 order by t.id ;
//前三最小值
select t.* from t_user t where rownum<=3 order by t.id desc;
//前三最大值
select avg(t.roleid),sum(t.id) from t_user t
//平均值与统计
select t.* from t_log t where t.userid<(select avg(id) from t_user);
//
select t.username,avg(t.roleid) from t_user t group by t.username ;
//统计表中某相同字段username的roleid平均值
select min(t.username),max(t.password) from t_user t
//最大值与最小值
7)字符函数:
select upper(substr(username,1,1))||lower(substr(username,2,length(username)-1)) from t_user
//将t_user表中的username字段内容的第一个字母大写显示,之后的小写显示8)相关函数
PL/SQL Mod,Ceil,floor,round函数
Mod是求余;
Ceil是取靠近值最大的整数;
floor是取靠近值最大的整数;
round是四舍五入;
Mod是求余;
Ceil是取靠近值最大的整数;
floor是取靠近值最大的整数;
round是四舍五入;
select mod(10,3) from dual ---1
select mod(4.1,3.1) from dual ---1
select mod(4.9,3.1) from dual ---1.8
select ceil(10/3) from dual ---4
select ceil(3.1) from dual ---4
select floor(3.1) from dual ---3
select floor(3.9) from dual ---3
select round(3.5) from dual ---4
select round(3.1) from dual ---33.oracle笔试题
题目1:显示各门课程的考场数目和可容纳的考生
各数据表结构如下:
表1:课程表 TC
cid 课程id
cname 课程名
Ctype 考试方式
表2:考场表 TR
Roomid 考场id
address 考场地址
Contain 容纳人数
表3:考场课程对应表 TCR
cid 课程id
roomId 考场id
表1:课程表 TC
cid 课程id
cname 课程名
Ctype 考试方式
表2:考场表 TR
Roomid 考场id
address 考场地址
Contain 容纳人数
表3:考场课程对应表 TCR
cid 课程id
roomId 考场id
sql:select s.cname,count(s.cname),sum(s.CONTAIN) from (select * from TC c,TR r,TCR cr where cr.cid=c.cid and cr.roomid=r.roomid) s group by s.cname; 写道
题目2:显示考试安排有冲突的考生及考试课程和时间
所谓有冲突,就是指一个考生同一时间(或考试时间有交集)安排了两门及两门以上的考试
所谓有冲突,就是指一个考生同一时间(或考试时间有交集)安排了两门及两门以上的考试
表1:课程表 TC
cid 课程id
cname 课程名
Ctype 考试方式
表2:考试表t_exam
eId 考试id
cid 课程id
beginTime 开始时间
endTime 结束时间
表3:考试安排表
studentId 学生id
examId 考试id
cid 课程id
cname 课程名
Ctype 考试方式
表2:考试表t_exam
eId 考试id
cid 课程id
beginTime 开始时间
endTime 结束时间
表3:考试安排表
studentId 学生id
examId 考试id
1) select distinct(t1.eid),t1.btime,t1.etime from t_exam t1, t_exam t2 where ((t1.btime between t2.btime and t2.etime)
2 or (t1.etime between t2.btime and t2.etime)) and t1.eid!=t2.eid order by t1.eid;
2) select distinct(t1.eid),t1.btime,t1.etime from t_exam t1, t_exam t2 where (t1.btime>t2.btime and t1.btime<t2.etime)
or (t1.etime>t2.btime and t1.etime<t2.etime) or (t1.btime in (select t.btime from t_exam t group by t.btime having count(t.btime)>1)) order by t1.eid;

















 219
219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









