



在数据量爆发式增长的今天,传统的、基于单机架构的ETL工具如Kettle,在性能、可维护性和云原生支持上已显疲态,是时候寻找一个更适应现代数据栈的解决方案了。
1. 为什么Kettle在现代化数据场景中开始力不从心?
Kettle作为一款开源ETL工具,以其图形化界面和灵活性在过去赢得了大量拥趸。然而,其核心架构诞生于云与大数据时代之前,在面对当前企业级需求时,暴露出几个关键瓶颈:
性能与扩展性瓶颈:Kettle本质上是一个单机工具。其并行处理能力依赖于手动拆分子作业,复杂且不稳定。当数据量达到亿级甚至更高时,内存和CPU很容易成为瓶颈,任务失败率显著升高。
运维成本高昂:缺乏原生的调度、监控和告警体系。通常需要结合Crontab、Airflow或其他调度器使用,故障排查如同大海捞针,需要投入大量运维人力。
云原生支持薄弱:难以无缝接入Kubernetes环境,无法实现资源的弹性伸缩。在混合云、多数据中心成为主流的今天,这极大地限制了其部署灵活性。
企业级功能缺失:在数据血缘、元数据管理、精细化的权限控制和操作审计方面,Kettle需要依赖其他组件或进行深度二次开发,开箱即用体验较差。
根据业界知名的《State of Data Engineering》报告,超过67%的数据团队将“可维护性和运维复杂度”列为评估数据工具时的首要考量,其重要性甚至超过了初期的学习成本。这正是Kettle用户痛点最真实的写照。
2. 现代化ETL平台应具备哪些核心特质?
一个面向未来的ETL工具,绝不仅仅是图形化拖拽这么简单。它需要是一个完整的“数据集成平台”,具备以下特质:
高可用与弹性伸缩:采用分布式架构,能够根据数据吞吐量的变化动态调配计算资源,保证任务SLA。
全面的运维监控能力:提供可视化的任务监控、实时日志、性能指标和智能告警,让运维工作从“救火”变为“预防”。
云原生与多租户:天然支持K8s部署,具备多租户隔离能力,满足大型企业的团队协作和安全需求。
开放与易集成:提供丰富的API,便于与现有的数据中台、数据治理体系无缝集成。

FAQ:如何评估一个ETL工具是否适合我的团队?
您可以建立一个评估清单,从以下几个维度打分:
- 功能性:是否支持您所需的数据源和目标?转换组件是否丰富?
- 性能:在处理您的典型数据量时,速度和稳定性如何?
- 运维:监控、告警、调度是否完善?故障恢复是否便捷?
- 总拥有成本(TCO):包括许可费用、部署成本、运维人力成本和学习成本。
- 架构前瞻性:是否支持云原生、是否易于扩展?
3. ETLCloud:为现代数据架构而生的数据集成平台
RestCloud旗下的ETLCloud数据集成平台从设计之初就瞄准了Kettle的上述短板,并提供了企业级的解决方案。
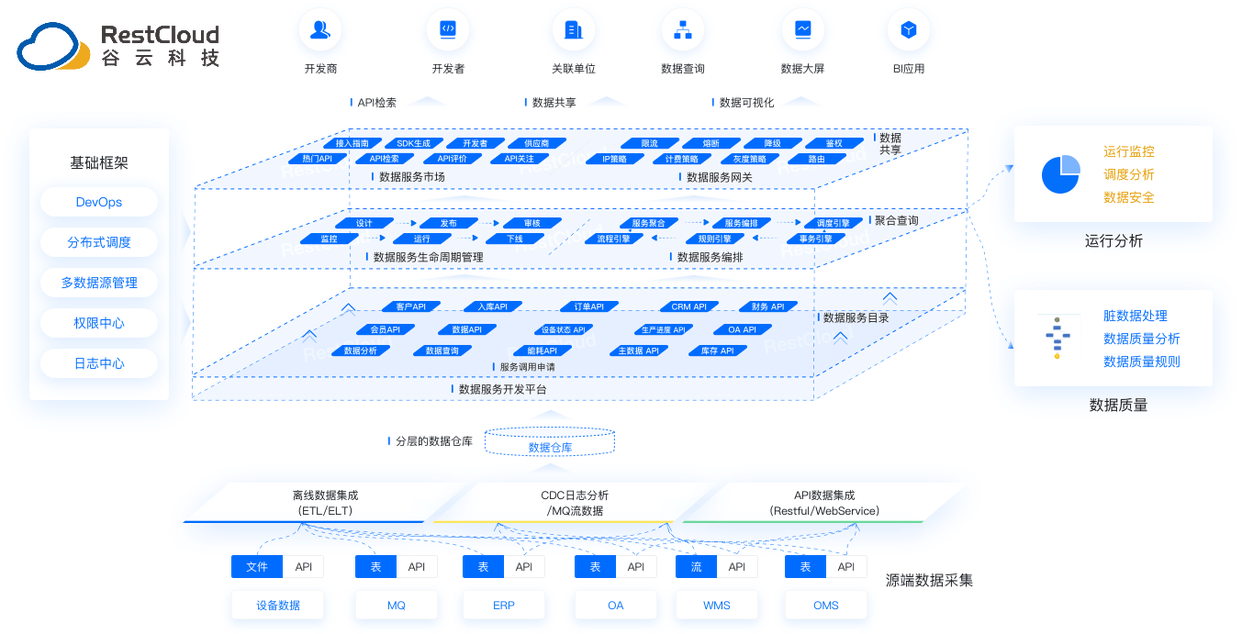
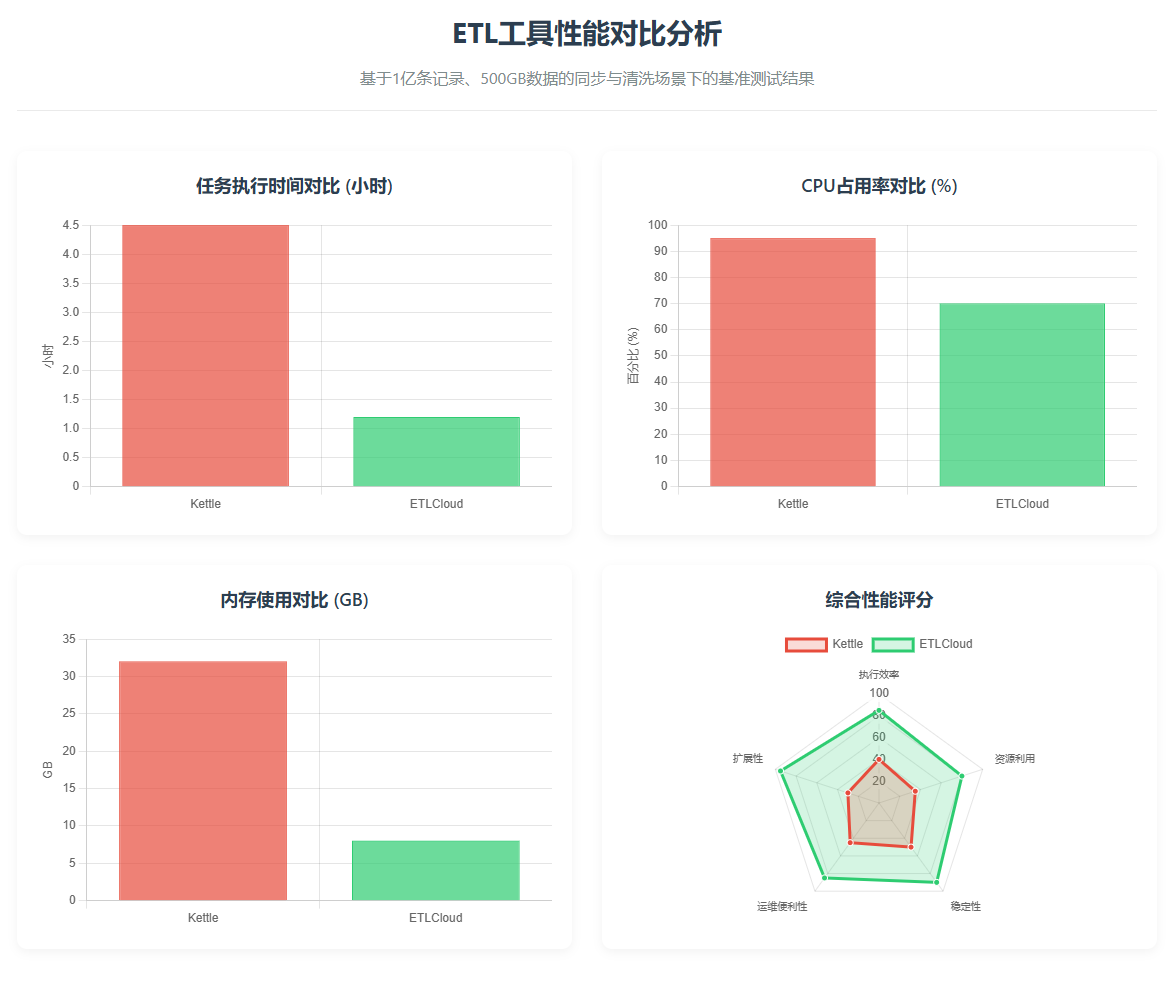
为了更直观地对比,我们在一个包含1亿条记录、约500GB数据的同步与清洗场景下,对Kettle和ETLCloud进行了基准测试,关键指标对比如下:

4. 从Kettle迁移到ETLCloud:平滑过渡的实践指南
迁移工具最担心的是历史作业的转换成本和团队的学习曲线。ETLCloud在这方面考虑得相当周到。
迁移的四个关键步骤:
步骤1:元数据梳理与评估
利用ETLCloud提供的Kettle作业/转换解析工具,将现有的Kettle XML文件导入平台,自动分析其结构和组件兼容性。
步骤2:组件映射与转换
平台能够将大部分Kettle的步骤(Step)自动映射为ETLCloud的组件。对于少数不支持的特定步骤,其图形化设计器使得手动重建工作变得非常简单。
步骤3:测试与验证
在隔离环境运行迁移后的任务,通过数据行级对比工具,确保输出结果与源任务完全一致。
步骤4:上线与监控
将任务部署到生产环境,利用平台强大的调度和监控能力接管原有任务,并逐步下线Kettle作业。
Kettle是一款功勋卓著的开源工具,但在数据规模和处理时效性要求极高的今天,其架构局限性已难以忽视,转向一个像ETLCloud这样具备云原生、高可用、易运维特性的现代化数据集成平台,不仅是解决当前性能瓶颈的方案,更是面向未来数据架构的战略投资。
对于正在评估Kettle替代方案的数据团队而言,关注平台的整体架构和长期总拥有成本,远比纠结于单一功能点的对比更为重要。

















 6710
6710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









