




机器学习中的评价指标
当一个机器学习模型建立好了之后,即模型训练已经完成,我们就可以利用这个模型进行分类识别。
正例,所关注的识别目标就是正例。
负例,正例以外就是负例。
TP、FN、TN、FP的各自含义(其中T代表True,F代表False,P即Positives,N即Negatives):
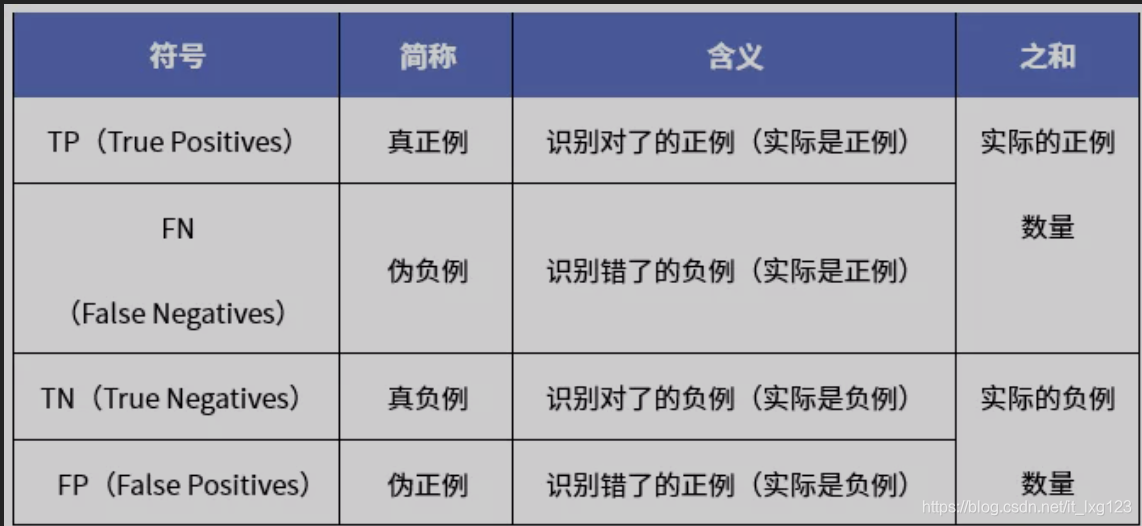
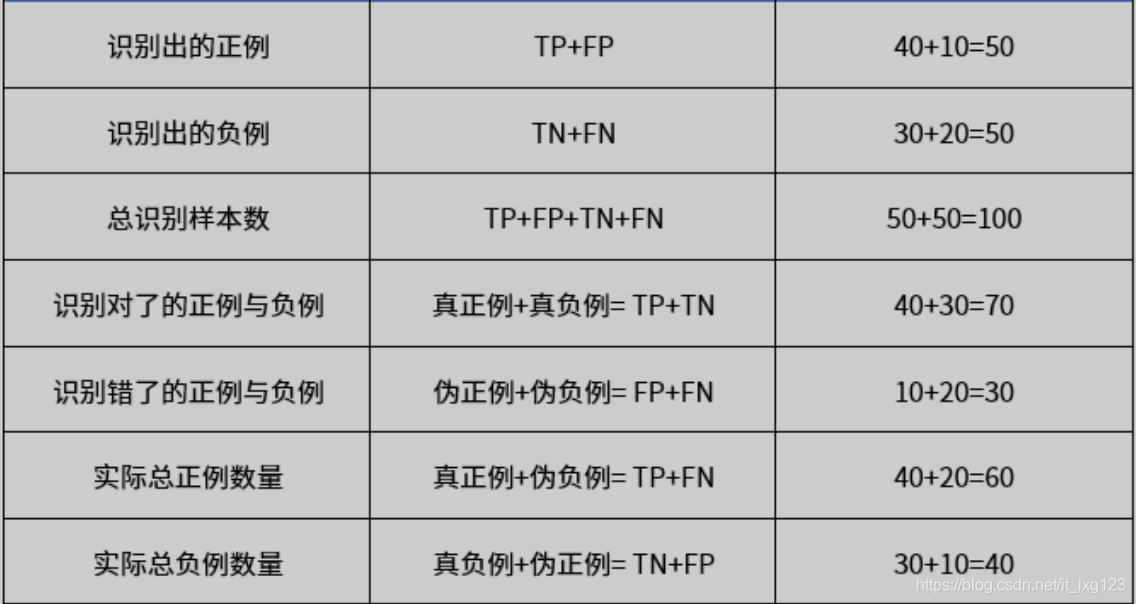
混淆矩阵
|
|
真实正例 |
真实负例 |
| 检测正例 |
TP |
FP |
| 检测反例 |
FN |
 本文详细介绍了机器学习模型的评价指标,包括准确性、错误率、精确度、召回率、PR曲线、AP、mAP、F-Measure、ROC曲线、AUC、IoU以及Top1和TopK等。这些指标用于评估模型的性能,如精度与召回率之间的平衡,以及在类别不平衡问题中的表现。理解这些指标对于优化和选择合适的模型至关重要。
本文详细介绍了机器学习模型的评价指标,包括准确性、错误率、精确度、召回率、PR曲线、AP、mAP、F-Measure、ROC曲线、AUC、IoU以及Top1和TopK等。这些指标用于评估模型的性能,如精度与召回率之间的平衡,以及在类别不平衡问题中的表现。理解这些指标对于优化和选择合适的模型至关重要。
机器学习中的评价指标
当一个机器学习模型建立好了之后,即模型训练已经完成,我们就可以利用这个模型进行分类识别。
正例,所关注的识别目标就是正例。
负例,正例以外就是负例。
TP、FN、TN、FP的各自含义(其中T代表True,F代表False,P即Positives,N即Negatives):
混淆矩阵
|
|
真实正例 |
真实负例 |
| 检测正例 |
TP |
FP |
| 检测反例 |
FN |
 3433
2635
508
3433
2635
508

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























