









 本文详细解析了 Spring JDBC 模块的工作原理,包括如何使用 JdbcTemplate 进行数据库操作,从设置 DataSource 到执行 SQL 语句的全过程。通过实例展示了添加 Maven 依赖、配置连接池、执行查询与更新操作的方法。
本文详细解析了 Spring JDBC 模块的工作原理,包括如何使用 JdbcTemplate 进行数据库操作,从设置 DataSource 到执行 SQL 语句的全过程。通过实例展示了添加 Maven 依赖、配置连接池、执行查询与更新操作的方法。
《Spring源码深度解析》
spring-framework-reference
jdbc使用示例
1. 添加maven依赖
有表book:

jdbc
1. 添加maven依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
2. test
@Test
public void test_02_statement_query() throws Exception {
AbstractApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
//创建连接
Connection connectionMySQL = DriverManager.getConnection(URL, USERNAME, PASSWORD);
Statement statement = connectionMySQL.createStatement();
ResultSet resultSet = statement.executeQuery("SELECT * FROM book");
//遍历列头..
ResultSetMetaData mData = resultSet.getMetaData();
IntStream.rangeClosed(1,mData.getColumnCount()).forEach(index ->{
try {
System.out.print(mData.getColumnName(index)+"\t\t");
} catch (SQLException e) {
e.printStackTrace();
}
});
System.out.println();
//遍历数据
while (resultSet.next()){
IntStream.rangeClosed(1,mData.getColumnCount()).forEach(index ->{
try {
System.out.print(resultSet.getObject(index)+"\t\t");
} catch (SQLException e) {
e.printStackTrace();
}
});
System.out.println();
}
//关闭连接
connectionMySQL.close();
}
Sping - JdbcTemplate
1.maven依赖
<!-- 数据库连接池 -->
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>1.4</version>
</dependency>
2. 实现方法
//mapper
public class BookRowMapper implements RowMapper<Book> {
@Override
public Book mapRow(ResultSet set, int rowNum) throws SQLException {
Book book = new Book(set.getString(1), set.getString(2), set.getDouble(3), set.getDate(4));
return book;
}
}
//Service
public class BookServiceImpl implements BookService {
private JdbcTemplate jdbcTemplate;
public void setDataSource(DataSource dataSource){
jdbcTemplate = new JdbcTemplate(dataSource);
}
@Override
public void save(Book book) {
jdbcTemplate.update("insert into book(isbn,name,price,publish_date) values(?,?,?,?)", new Object[]{book.getIsbn(), book.getName(), book.getPrice(), book.getPublishDate()}, new int[]{Types.VARBINARY, Types.VARCHAR, Types.DOUBLE, Types.DATE});
}
@Override
public List<Book> listBooks() {
List<Book> list = jdbcTemplate.query("select * from book" ,new BookRowMapper());
return list;
}
}
3.applicationContext.xml 配置
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/test"/>
<property name="username" value="scott"/>
<property name="password" value="tiger"/>
<!-- 连接池启动时的初始值 -->
<property name="initialSize" value="1"/>
<!-- 最大连接数-->
<property name="maxActive" value="10"/>
<!--最大空闲值, 当经过高峰时间后,连接池可以慢慢将已经用不到的连接释放一部分,一直减到maxIdle为止。 -->
<property name="maxIdle" value="2"/>
<!--最小空闲数, 当空闲连接数少于阈值时,会主动去申请一些连接, 以防止来不及申请-->
<property name="minIdle" value="1"/>
</bean>
<bean id="bookService" class="spring.chap08.service.impl.BookServiceImpl">
<property name="dataSource" ref="dataSource"/>
</bean>
4. test
@Test
public void test_spring_jdbcTmp(){
AbstractApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
BookService bookService = context.getBean("bookService", BookService.class);
bookService.save(new Book("i_003","m克",6.78d,new Date()));
bookService.listBooks().forEach(item -> {
System.out.println(item);
});
}
Spring-JDBC源码分析
jdbcTemplate的初始化,是从setDataSource开始的,DataSource创建过程是引入的第三方连接池(常见连接池有:dbcp,c3p0,druid等。),后续会专门分析。这里先分析jdbcTemplate的相关操作。
1.save/update
//org.springframework.jdbc.core.JdbcTemplate
public class JdbcTemplate extends JdbcAccessor implements JdbcOperations {
public int update(String sql, Object[] args, int[] argTypes) throws DataAccessException {
//构造ArgumentTypePreparedStatementSetter(args, argTypes);
return update(sql, newArgTypePreparedStatementSetter(args, argTypes));
}
public int update(String sql, PreparedStatementSetter pss) throws DataAccessException {
//构造SimplePreparedStatementCreator(sql)
return update(new SimplePreparedStatementCreator(sql), pss);
}
protected int update(final PreparedStatementCreator psc, final PreparedStatementSetter pss)
throws DataAccessException {
//构建 PreparedStatementCallback
return execute(psc, new PreparedStatementCallback<Integer>() {
public Integer doInPreparedStatement(PreparedStatement preparedStatement) throws SQLException {
try {
if (pss != null) {
//给preparedStatement设置参数
pss.setValues(preparedStatement);
}
int rows = preparedStatement.executeUpdate();
return rows;
} finally {
if (pss instanceof ParameterDisposer) {
((ParameterDisposer) pss).cleanupParameters();
}
}
}
});
}
public <T> T execute(PreparedStatementCreator psc, PreparedStatementCallback<T> callback)
throws DataAccessException {
//1.获取数据库连接
Connection con = DataSourceUtils.getConnection(getDataSource());
PreparedStatement preparedStatement = null;
try {
Connection conToUse = con;
if (this.nativeJdbcExtractor != null &&
this.nativeJdbcExtractor.isNativeConnectionNecessaryForNativePreparedStatements()) {
conToUse = this.nativeJdbcExtractor.getNativeConnection(con);
}
//psc.createPreparedStatement逻辑如下:
//return (PreparedStatement preparedStatement = con.prepareStatement(this.sql))
preparedStatement = psc.createPreparedStatement(conToUse);
//2. 应用用户输入的参数:如fetchSize,maxRows
applyStatementSettings(preparedStatement);
PreparedStatement psToUse = preparedStatement;
if (this.nativeJdbcExtractor != null) {
psToUse = this.nativeJdbcExtractor.getNativePreparedStatement(preparedStatement);
}
//3.执行回调函数doInPreparedStatement
T result = callback.doInPreparedStatement(psToUse);
//4.警告处理
handleWarnings(preparedStatement);
return result;
}
finally {
if (psc instanceof ParameterDisposer) {
((ParameterDisposer) psc).cleanupParameters();
}
JdbcUtils.closeStatement(preparedStatement);
//5.释放连接
DataSourceUtils.releaseConnection(con, getDataSource());
}
}
}
时序图
执行的时序图如下:
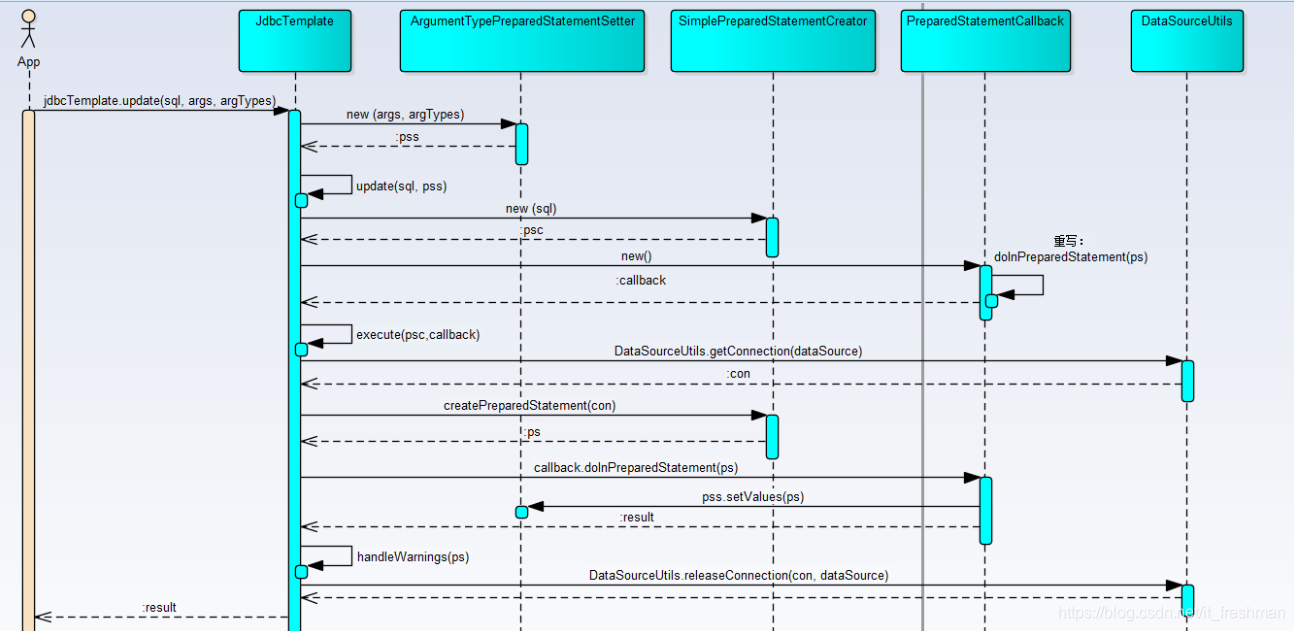
执行的流程:首先是构造不同类型的参数,最终调用execute方法,execute作为数据库操作的核心入口,将大多数数据库操作相同的步骤统一封装,而将个性化的操作使用PreparedStatementCallback作为回调执行。
- 获取数据库连接
- 应用用户输入的参数:如fetchSize,maxRows
- 执行回调函数
- 警告处理
- 释放资源
1.1 获取数据库连接
创建数据库连接和释放连接后续会详细介绍。
dbcp连接池
1.2 应用用户输入的参数
protected void applyStatementSettings(Statement stmt) throws SQLException {
//fetchSize: ResultSet.next() 一次从服务器读取多少行数据
int fetchSize = getFetchSize();
if (fetchSize > 0) {
stmt.setFetchSize(fetchSize);
}
//maxRows:返回的最大数据行数
int maxRows = getMaxRows();
if (maxRows > 0) {
stmt.setMaxRows(maxRows);
}
DataSourceUtils.applyTimeout(stmt, getDataSource(), getQueryTimeout());
}
1.3 执行回调函数
执行callback.doInPreparedStatement(),执行自定义的doInPreparedStatement函数,来完成个性化操作。
其中最重要的逻辑为:pss.setValues(ps),它想要实现的操作,同:
PreparedStatement pstmt = con.prepareStatement("insert into book(isbn,name,price,publish_date) values(?,?,?,?)");
pstmt.setString(1, "xx");
pstmt.setString(2, "xxx");
pstmt.setDouble(3, 12.3d);
pstmt.setDate(4, new Date());
1.4 警告处理
protected void handleWarnings(Statement stmt) throws SQLException {
if (isIgnoreWarnings()) {
//记录日志.... 略...
} else {
handleWarnings(stmt.getWarnings());
}
}
protected void handleWarnings(SQLWarning warning) throws SQLWarningException {
if (warning != null) {
throw new SQLWarningException("Warning not ignored", warning);
}
}
1.5 释放资源
创建数据库连接和释放连接后续会详细介绍。
2. query
前面的例子中,我们并没有使用参数,而实际的开发过程中我们常常会传入参数来查询数据,改造之前的demo,
@Override
public List<Book> listBooks(String isbn) {
if(StringUtils.isEmpty(isbn)){
return jdbcTemplate.query("select * from book " ,new BookRowMapper());
}
return jdbcTemplate.query("select * from book where isbn=?" ,new BookRowMapper(),isbn);
}
2.1 不带参数query
//a
public <T> List<T> query(String sql, RowMapper<T> rowMapper){
return query(sql, new RowMapperResultSetExtractor<T>(rowMapper));
}
//b
public <T> T query(final String sql, final ResultSetExtractor<T> rse) {
class QueryStatementCallback implements StatementCallback<T>, SqlProvider {
//不带参数查询, 直接使用 Statement
public T doInStatement(Statement stmt) throws SQLException {
//省略 try-catch , finally....
ResultSet rs = null;
rs = stmt.executeQuery(sql);
ResultSet rsToUse = rs;
//交由RowMapperResultSetExtractor 来转换结果
return rse.extractData(rsToUse);
}
}
//execute方法同update部分, 个性化操作全部交由 callback来处理。
return execute(new QueryStatementCallback());
}
2.2 带参数query
//a
public <T> List<T> query(String sql, RowMapper<T> rowMapper, Object... args) {
return query(sql, args, new RowMapperResultSetExtractor<T>(rowMapper));
}
//b
public <T> T query(String sql, Object[] args, ResultSetExtractor<T> rse) {
//构造 newArgPreparedStatementSetter参数 --- ps:很眼熟吧..
return query(sql, newArgPreparedStatementSetter(args), rse);
}
//c
public <T> T query(String sql, PreparedStatementSetter pss, ResultSetExtractor<T> rse) {
return query(new SimplePreparedStatementCreator(sql), pss, rse);
}
//d
public <T> T query(
PreparedStatementCreator psc, final PreparedStatementSetter pss, final ResultSetExtractor<T> rse) {
return execute(psc, new PreparedStatementCallback<T>() {
//省略 try-catch , finally....
//带参数查询使用PreparedStatement
public T doInPreparedStatement(PreparedStatement ps) throws SQLException {
ResultSet rs = null;
if (pss != null) {
//设置PreparedStatement 参数
pss.setValues(ps);
}
rs = ps.executeQuery();
ResultSet rsToUse = rs;
//交由RowMapperResultSetExtractor 来转换结果
return rse.extractData(rsToUse);
}
});
}
2.3 RowMapperResultSetExtractor
RowMapperResultSetExtractor较为简单, 处理逻辑就是遍历ResultSet,并使用rowMapper进行转换.
//org.springframework.jdbc.core.RowMapperResultSetExtractor
public class RowMapperResultSetExtractor<T> implements ResultSetExtractor<List<T>> {
private final RowMapper<T> rowMapper;
private final int rowsExpected;
public RowMapperResultSetExtractor(RowMapper<T> rowMapper) {
this(rowMapper, 0);
}
public List<T> extractData(ResultSet rs) throws SQLException {
List<T> results = (this.rowsExpected > 0 ? new ArrayList<T>(this.rowsExpected) : new ArrayList<T>());
int rowNum = 0;
while (rs.next()) {
results.add(this.rowMapper.mapRow(rs, rowNum++));
}
return results;
}
}
3.queryForObject
queryForObject 重载了多个方法,
public <T> T queryForObject(String sql, RowMapper<T> rowMapper, Object... args);
//....
public <T> T queryForObject(String sql, Object[] args, Class<T> requiredType);
我们以抽取上述的其中一个方法来分析, service添加如下方法:
@Override
public String getName(String isbn) {
String name = jdbcTemplate.queryForObject("select name from book where isbn=?" ,String.class,isbn);
return name;
}
分析源码:
//org.springframework.jdbc.core.JdbcTemplate
protected <T> RowMapper<T> getSingleColumnRowMapper(Class<T> requiredType) {
//使用SingleColumnRowMapper
return new SingleColumnRowMapper<T>(requiredType);
}
public <T> T queryForObject(String sql, Class<T> requiredType, Object... args) {
return queryForObject(sql, args, getSingleColumnRowMapper(requiredType));
}
public <T> T queryForObject(String sql, Object[] args, RowMapper<T> rowMapper) {
//调用query方法, 并指定返回rowsExpected=1
List<T> results = query(sql, args, new RowMapperResultSetExtractor<T>(rowMapper, 1));
return DataAccessUtils.requiredSingleResult(results);
}
与之前的query方法不同的是,它使用SingleColumnRowMapper转换,且只请求1条数据。
SingleColumnRowMapper
//org.springframework.jdbc.core.SingleColumnRowMapper
public class SingleColumnRowMapper<T> implements RowMapper<T> {
private Class<T> requiredType;
public SingleColumnRowMapper(Class<T> requiredType) {
this.requiredType = requiredType;
}
public T mapRow(ResultSet rs, int rowNum) throws SQLException {
//校验返回数据的列数.
ResultSetMetaData rsmd = rs.getMetaData();
int nrOfColumns = rsmd.getColumnCount();
//如果返回多列数据, 直接抛出异常。。。
if (nrOfColumns != 1) {
throw new IncorrectResultSetColumnCountException(1, nrOfColumns);
}
//getColumnValue包含两步操作
//a. 获取rs.getValue(1); //由于只返回1列数据,所以固定index=1
//b. 将结果转换为requiredType
Object result = getColumnValue(rs, 1, this.requiredType);
if (result != null && this.requiredType != null && !this.requiredType.isInstance(result)) {
//如果上述转换未成功, 再次尝试转换...
return (T) convertValueToRequiredType(result, this.requiredType);
}
return (T) result;
}
}

















 641
641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









