



 本文介绍了C++中常用的数据结构和算法,如栈的push、pop等操作,使用hashmap解决LeetCode问题,vector的使用包括排序和插入删除,处理AddressSanitizer的heap-buffer-overflow错误,字符串处理,set的遍历和操作,二叉树的遍历,以及位运算是如何实现加法的。此外,还讨论了std库中的其他有用数据结构和面试准备内容,如堆和栈的区别,C++的封装、继承、多态概念。
本文介绍了C++中常用的数据结构和算法,如栈的push、pop等操作,使用hashmap解决LeetCode问题,vector的使用包括排序和插入删除,处理AddressSanitizer的heap-buffer-overflow错误,字符串处理,set的遍历和操作,二叉树的遍历,以及位运算是如何实现加法的。此外,还讨论了std库中的其他有用数据结构和面试准备内容,如堆和栈的区别,C++的封装、继承、多态概念。
文章目录
刷题思路网站: https://www.algomooc.com/
常用
#include<string>
to_string 数字转字符串
int stoi(const strings str, size_t* pos = 0, int base = 10)
long stol(const strings str, size_t* pos = 0, int base = 10)
float stof(const strings str, size_t* pos = 0)
double stod(const strings str, size_t* pos = 0)
string str;
getline(cin,str);
//判断换行
int temp;
while(cin >> temp){
if(cin.get() == '\n'){
break;
}
}
#include<cmath>//pow(x,y)
#include<algorithm>//vector<int> sort
1、stack栈相关
top():返回一个栈顶元素的引用,类型为 T&。如果栈为空,返回值未定义。
push(const T& obj):可以将对象副本压入栈顶。这是通过调用底层容器的 push_back() 函数完成的。
push(T&& obj):以移动对象的方式将对象压入栈顶。这是通过调用底层容器的有右值引用参数的 push_back() 函数完成的。
pop():弹出栈顶元素。
size():返回栈中元素的个数。
empty():在栈中没有元素的情况下返回 true。
emplace():用传入的参数调用构造函数,在栈顶生成对象。
swap(stack & other_stack):将当前栈中的元素和参数中的元素交换。参数所包含元素的类型必须和当前栈的相同。对于 stack 对象有一个特例化的全局函数 swap() 可以使用。
std::stack<std::string> words;
stack<int> S; //定义一个存储整数类型的栈
2、leetcode138题hashmap哈希映射
class Solution {
public:
Node* copyRandomList(Node* head) {
if(head == nullptr) return nullptr;
Node* cur = head;
unordered_map<Node*, Node*> map;
// 3. 复制各节点,并建立 “原节点 -> 新节点” 的 Map 映射
while(cur != nullptr) {
map[cur] = new Node(cur->val);
cur = cur->next;
}
cur = head;
// 4. 构建新链表的 next 和 random 指向
while(cur != nullptr) {
map[cur]->next = map[cur->next];
map[cur]->random = map[cur->random];
cur = cur->next;
}
// 5. 返回新链表的头节点
return map[head];
}
};
统计第一个只出现一次的字符串
char firstUniqChar(string s) {
if(s=="")
return ' ';
unordered_map <char,int> charMap;
for(int i=0;i<s.length();i++)
{
if(charMap[s[i]])
charMap[s[i]]++;
else
charMap[s[i]]=1;
}
for(int i=0;i<s.length();i++)
{
if(charMap[s[i]]==1)
return s[i];
}
return ' ';
3、Vetor相关
int *dp=new int[n+1];//创建int数组
int Max_value = *max_element(tmp.begin(),tmp.end());//寻找最大值
判断 vector<vector<int>> matrix;为空
if(matrix.size()==0)
判断 vector<vector<int>> matrix={{}};为空
if(matrix[0].size()==0)
直接声明二维vector
vector<vector<int>> visited(h, vector<int>(w));
vector升序排列
#include <iostream>
#include<vector>
vector<int> Nums;
sort(Nums.begin(),Nums.end());
emplace_back和push_back类似
pop_back()删除栈中最后一个元素
vector插入值
v2.insert(v2.begin()+4, L"3"); //在指定位置,例如在第五个元素前插入一个元素
v2.insert(v2.end(), L"3"); //在末尾插入一个元素
v2.push_back(L"9"); //在末尾插入一个元素
v2.insert(v2.begin(), L"3"); //在开头插入一个元素
删除元素
v2.erase(v2.begin()); //删除开头的元素
v2.erase(v2.begin(),v2.end); //删除[begin,end]区间的元素
v2.pop_back(); //删除最后一个元素
5、Queue
queue<TreeNode*> myQue;
myQue.empty();
myQue.push(A);
TreeNode* B = myQue.front();
myQue.pop();//弹出队列第一个元素
剑指41题,带排序的队列
class MedianFinder {
public:
/** initialize your data structure here. */
priority_queue<int, vector<int>, less<int>> queMin;//保存小的那一半,queMin.top保存小的一半里面最大的那个数
priority_queue<int, vector<int>, greater<int>> queMax;//保存大的那一半,queMax.top保存大的一半里面最小的那个数
MedianFinder() {}
void addNum(int num) {
if (queMin.empty() || num <= queMin.top()) {
queMin.push(num);
if (queMax.size() + 1 < queMin.size()) {
queMax.push(queMin.top());
queMin.pop();
}
} else {
queMax.push(num);
if (queMax.size() > queMin.size()) {
queMin.push(queMax.top());
queMax.pop();
}
}
}
double findMedian() {
if (queMin.size() > queMax.size()) {
return queMin.top();
}
return (queMin.top() + queMax.top()) / 2.0;
}
};
双端队列
#include <iostream>
#include <deque>
using namespace std;//必须加
int main() {
deque<int> mydeque;
mydeque.push_front(10); // 在队列前面插入元素
mydeque.push_back(20); // 在队列后面插入元素
mydeque.push_front(5); // 在队列前面插入元素
mydeque.push_back(30); // 在队列后面插入元素
cout << "队列中的元素: ";
for (auto it = mydeque.begin(); it != mydeque.end(); ++it) {
cout << *it << " ";
}
cout << endl;
cout << "队列的大小: " << mydeque.size() << endl;
mydeque.pop_front(); // 从队列前面删除元素
cout << "队列中的元素: ";
for (auto it = mydeque.begin(); it != mydeque.end(); ++it) {
cout << *it << " ";
}
cout << endl;
cout << "队列的第一个元素: " << mydeque.front() << endl;
cout << "队列的最后一个元素: " << mydeque.back() << endl;
return 0;
}
/*
队列中的元素: 5 10 20 30
队列的大小: 4
队列中的元素: 10 20 30
队列的第一个元素: 10
队列的最后一个元素: 30
*/
4 、AddressSanitizer: heap-buffer-overflow on address报错
第一处是substring[str_len] = '\0', 大小为N的数组,最后一位是N-1。
第二处错误在(*result)[*returnSize] = (char *)malloc( sizeof(char) * strlen(sublist) );中,新申请的内存大小应该是sizeof(char) * (strlen(sublist) + 1), 需要放在最后的'\0';
5、string、char相关
vector<string> v;//字符串的排序
sort(v.begin(),v.end());
string s="hello";
int n = s.length();
//string是一个类
std::swap(s[0], s[2]);
std::cout << s << std::endl;//lehlo
sting A = "ABCD";
reverse(A.begin(),A.end());
A.at(1);
ACM模式下输入字符串
string str;
while (getline(cin,str))
{}
string的查找函数
string str = "abc";
string subStr1 = "bc";
string subStr2 = "cd";
str.find(subStr1); //返回1,第一个匹配的下标
str.find(subStr2); //返回string::npos,不是子串的话,返回一个特殊值//subStr1是否为子串
if(str.find(subStr1) != string::npos){cout<<"subStr1 是 str 的子串"<<endl;
}
6、set用法
求字符串非重复最长连续子集
#include <iostream>
#include <vector>
#include <set>
using namespace std;
int lengthOfLongestSubstring(string s) {
//利用哈希表,设计一个滑动窗口
int result = 0;
std::set<char> Split_window;
int left = 0;
for (int i = 0; i < s.length(); i++)
{
char c = s[i];
if (Split_window.find(c) != Split_window.end())
{
Split_window.erase(s[left]);
left++;
}
Split_window.insert(c);
result = max((i + 1 - left), result);
}
return result;
}
int main()
{
cout << lengthOfLongestSubstring("pwwkew");
return 0;
}
set可以遍历
#include <iostream>
#include <set>
int main() {
std::set<int> mySet{1, 2, 3, 4, 5};
// 删除元素 3
mySet.erase(3);
// 输出剩余元素
for (auto it = mySet.begin(); it != mySet.end(); ++it) {
std::cout << *it << ' ';
}
std::cout << std::endl;
return 0;
}
7 、二叉树
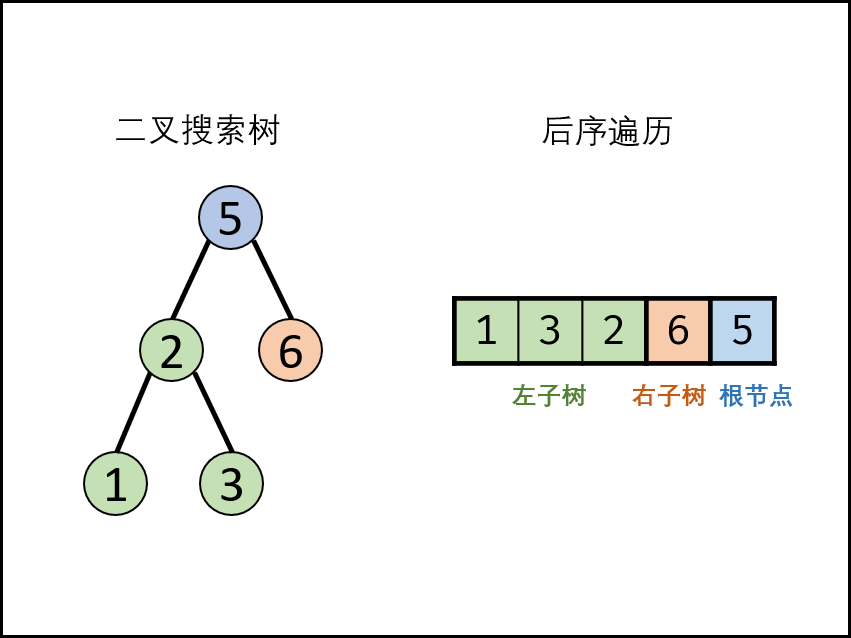
二叉搜索树定义:左子树中所有节点的值 < 根节点的值;右子树中所有节点的值 > 根节点的值;
其左、右子树也分别为二叉搜索树。
一、前序遍历
前序遍历:按 根结点->左子树->右子树 顺序进行遍历 。
上述二叉树前序遍历结果为:ABDGHECFI
二、中序遍历
中序遍历:按 左子树->根结点->右子树 顺序进行遍历 。
上述二叉树中序遍历结果为:GDHBEACIF
三、后序遍历
中序遍历:按 左子树->右子树->根结点 顺序进行遍历 。
上述二叉树后序遍历结果为:GHDEBIFCA
8 、位运算实现加法
a=b|c
若b=01000,c=00001,则a=01001
int add(int a, int b) {
while(b!=0)
{
a =a^b;//异或运算
unsigned int carry = (unsigned int) (a&b)<<1;//&表示且运算,<<表示二进制往左移动一位
b = carry;
}
return a;
}
9、std中好用的数据结构
std::vector<std::pair<int, int>> directions{ {0, 1}, {0, -1}, {1, 0}, {-1, 0} };
for (const auto dir : directions)
{
int i = dir.first;
int j = dir.second;
}
#include<map>
#include<iostream>
using namespace std;
int main()
{
map<char,int>maps;
maps['d']=10;
maps['e']=20;
maps['a']=30;
maps['b']=40;
maps['c']=50;
maps['r']=60;
for(map<char,int>::iterator it=mp.begin();it!=mp.end();it++)
{
cout<<it->first<<" "<<it->second<<endl;
}
return 0;
}
10、包含重复数据的全排列
class Solution {
public:
vector<vector<int>> permuteUnique(vector<int>& nums) {
dfs(0, nums);
return ans;
}
private:
vector<vector<int> > ans;
void dfs(int i, vector<int>& nums) {
if(i>=nums.size()-1) {
ans.push_back(nums);
return;
}
set<int> used;
for(int j=i; j<nums.size(); ++j) {
if(used.find(nums[j])!=used.end()) continue;
used.insert(nums[j]);
swap(nums[i], nums[j]);
dfs(i+1,nums);
swap(nums[i], nums[j]);
}
}
};
面经准备
总结得不错的八股
牛客c++面试
TCP&IP协议三次握手四次挥手
1、封装、继承、多态
多态是指在面向对象的程序中,可以使用基类的指针或引用来引用派生类的对象
#include <iostream>
using namespace std;
class A {
public:
A() { std::cout << "A" << std::endl; };
virtual ~A() { std::cout << "~A" << std::endl; };
};
class B:public A {
public:
B(){ std::cout <<"B"<< std::endl;};
~B() { std::cout << "~B" << std::endl; };
};
int main()
{
A* a = new B();
a->~A();
return 0;
}
会调用基类的析构函数
/*
输出:
A
B
~B
~A
*/
2、C/C++内存区域划分详解
2.1 栈(Stack):
栈用于存储函数的局部变量、函数参数、以及函数调用时的一些临时数据。栈是一个自动分配和释放内存的区域,其特点是具有快速的分配和释放速度,但大小有限。每当一个函数被调用时,会在栈上分配一块内存空间用于存储函数的局部变量和参数,当函数执行完毕后,这块内存空间会被自动释放。
2.2 堆(Heap):
堆用于动态分配内存,即通过使用new和delete(C++)或malloc和free(C)等操作来分配和释放内存。堆的大小一般比较大,但是分配和释放内存的速度较慢。堆上分配的内存需要手动释放,否则可能导致内存泄漏。
全局区/静态存储区(Global/Static Storage):
全局区用于存储全局变量和静态变量。全局变量在程序运行期间一直存在,静态变量的生命周期也与程序的执行时间相同,但其作用域可能被限制在特定的函数或文件中。全局区在程序启动时被分配,在程序结束时释放。
2.3 常量区(Constant Area):
常量区用于存储常量字符串和全局常量。在程序编译期间,常量字符串和全局常量的值会被保存在常量区,在程序运行期间不能被修改。
2.4 代码区/文本区(Code/Text Area):
代码区存储程序的执行代码,包括函数的机器指令。这部分内存区域通常是只读的,不允许进行写操作。
3、内存泄漏:动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢、系统崩溃等
野指针:野指针指的是指向已经释放或无效的内存地址的指针。
悬空指针:悬空指针是指针最初指向的内存已经被释放了的一种指针。
4、进程与线程
进程:进程是系统分配资源和调度的基本单位,也就是说进程可以单独运行一段程序。
线程:线程是cpu调度和分派的最小基本单位。
5、初始化和拷贝
6、重载和隐藏
派生类跟基类中的函数可以重名(重载)
7、浅拷贝和和深拷贝的区别
浅拷贝只复制指针地址,深拷贝复制指针地址并且开辟新的内存空间。
8、内联函数在编译时直接将函数代码嵌入到目标代码中,省去函数调用的开销。内联函数有参数类型检查
多线程下volatile关键字声明,该关键字的作用是防止优化编译器把变量从内存装入CPU寄存器中。
虚函数的作用?

















 2596
2596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









