




 本文介绍了一个使用Python爬虫抓取豆瓣最新电影信息并利用Flume实时传输到HDFS的案例。首先,阐述了Python爬虫如何访问网页、解析HTML,然后详细说明了Flume的配置文件设置,最后展示了数据在HDFS中的存储情况。
本文介绍了一个使用Python爬虫抓取豆瓣最新电影信息并利用Flume实时传输到HDFS的案例。首先,阐述了Python爬虫如何访问网页、解析HTML,然后详细说明了Flume的配置文件设置,最后展示了数据在HDFS中的存储情况。
首先,让我们看一下本案例的背景:通过python爬虫抓取豆瓣最新上映的电影信息,抓取的信息通过flume传输到HDFS中。python的版本是3.6,flume的版本是1.8。
Python 爬虫程序讲解
(1)编写网页爬虫程序,首先要对网页进行访问,python中使用的urllib库,代码如下:
from urllib import request
resp = request.urlopen('https://movie.douban.com/nowplaying/wuhan/')
html_data = resp.read().decode('utf-8')
其中https://movie.douban.com/nowplaying/wuhan/ 是豆瓣最新上映的电影页面,可以在浏览器中输入该网址进行查看。html_data是字符串类型的变量,里面存放了网页的html代码。
(2)对html代码进行解析,提取我们需要的数据。在python中使用BeautifulSoup库进行html代码的解析。(注:如果没有安装此库,则使用pip3 install beautifulsoup4进行安装即可!)
BeautifulSoup使用的格式如下:
BeautifulSoup(html,"html.parser")
第一个参数为需要提取数据的html,第二个参数是指定解析器。
(3)打开我们爬取网页的html代码,查看我们需要的数据所在html标签,如下图所示。
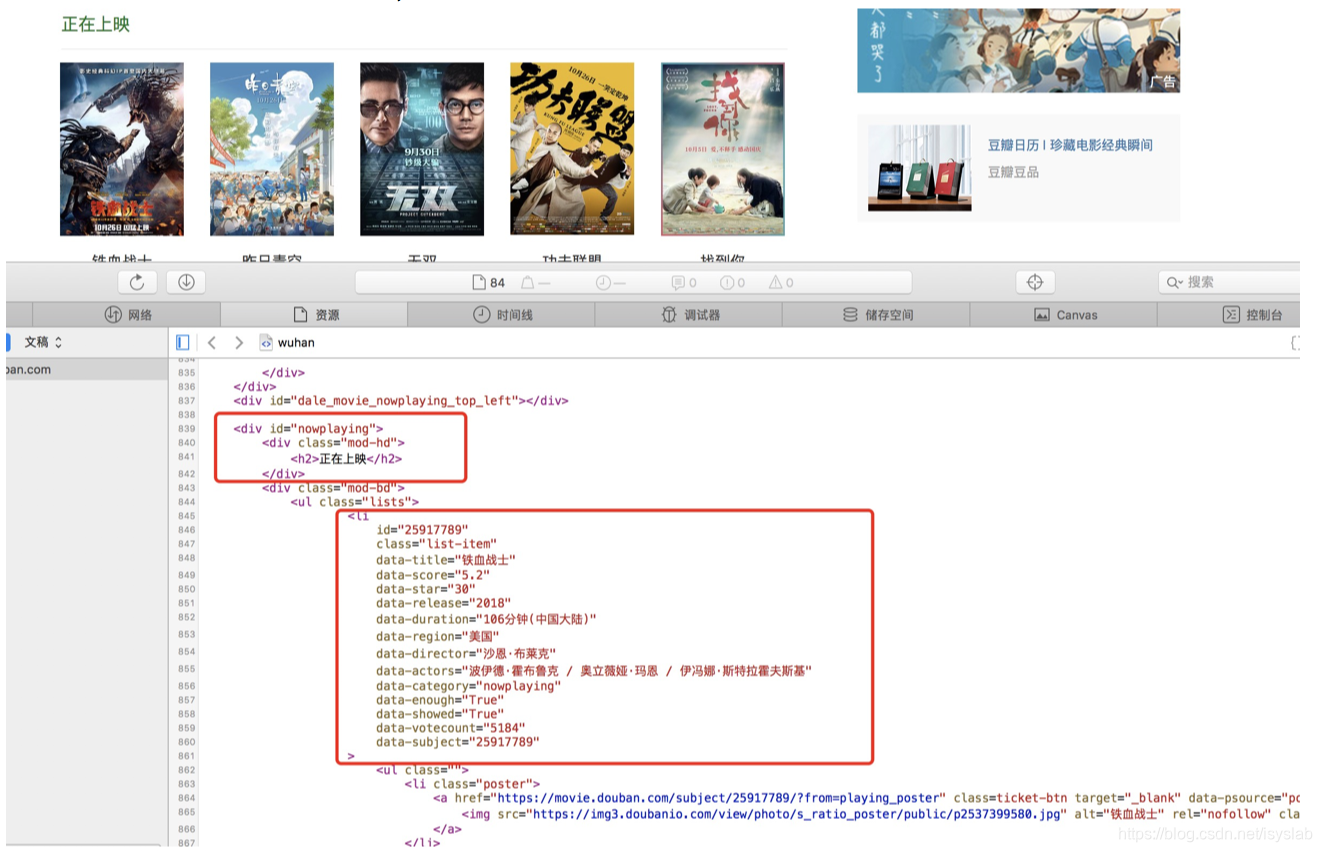
从上图中可以看出从div id=”nowplaying“标签开始是我们想要的数据,里面有电影的名称、评分、主演等信息。所以相应的代码编写如下:
from bs4 import BeautifulSoup 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1552
1552




 到【灌水乐园】发言
到【灌水乐园】发言







