




步骤:
建立索引
1) 采集文档
2) 创建文档
3) 分析文档
4) 索引文档
查询索引
1) 创建查询
2) 执行搜索
3) 渲染搜素
建立索引库的流程:
采集文档: 链接:https://pan.baidu.com/s/17YPQcwWJFXU0qqARp_7TfQ 提取码:3ib1
创建文档(Lucene的文档对象, 并非原始文档):
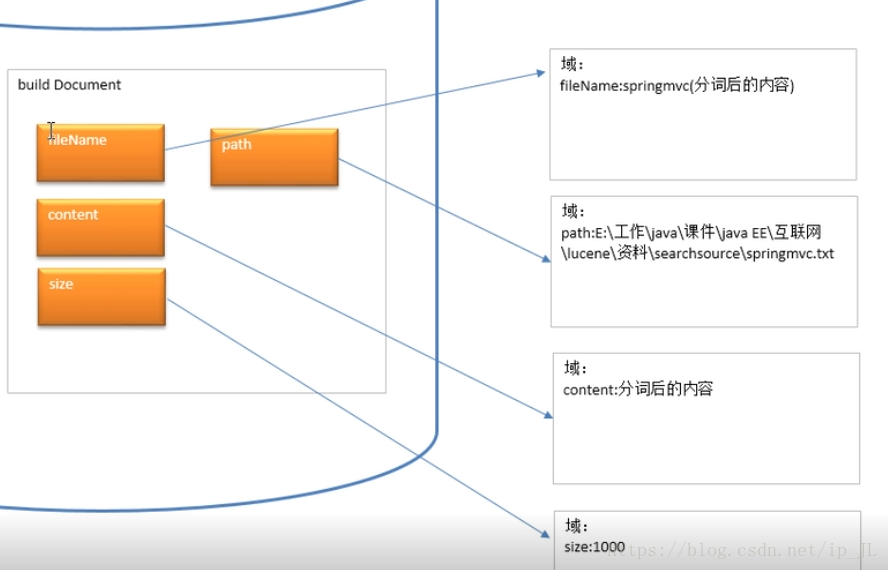
索引的导入
测试代码:
package cn.tx.test;
import java.io.File;
import java.nio.file.Path;
import java.nio.file.Paths;
import org.apache.commons.io.FileUtils;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.LongField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.FSDirectory;
import org.junit.Before;
import org.junit.Test;
public class LuceneTest {
@Before
public void setUp() throws Exception {
}
/**
* 导入索引
*/
@Test
public void importIndex() throws Exception {
//获取索引库的位置
Path path = Paths.get("C:\\Software\\JAVA\\EclipseMars4.5ForOthers\\workspace1\\lucene_demo\\index_loc");
//打开索引库
FSDirectory dir = FSDirectory.open(path);
//创建标准分词器
Analyzer al = new StandardAnalyzer();
//创建索引的写入配置对象
IndexWriterConfig iwc = new IndexWriterConfig(al);
//创建索引的Writer
IndexWriter iw = new IndexWriter(dir, iwc);
//采集原始文档
File sourceFile = new File("C:\\Software\\JAVA\\EclipseMars4.5ForOthers\\workspace1\\lucene_demo\\index_file");
//获取文件夹下的所有文件
File[] files = sourceFile.listFiles();
//遍历
for(File file: files){
//获取file的属性
String fileName = file.getName();
String content = FileUtils.readFileToString(file);
long size = FileUtils.sizeOf(file);
String path1 = file.getPath();
//创建域 参数③: 是否存储
Field fName = new TextField("fileName", fileName, Store.YES);
Field fContent = new TextField("content", content, Store.YES);
Field fSize = new LongField("size", size, Store.YES);
Field fPath = new TextField("path", path1, Store.YES);
//创建Lucene的文档对象
Document document = new Document();
document.add(fName);
document.add(fContent);
document.add(fSize);
document.add(fPath);
iw.addDocument(document);
}
iw.commit();
iw.close();
}
}
结果:
"域"Field的属性
1) 是否可以被分词
id 订单号 身份证号...不可被分词
2) 是否可以被索引
是否可以被搜索, 文件路径...不可被搜索
3) 是否可以被存储
是否存储在Lucene的文档中, 内容太大则不可被存储
Lucene是有固定的域的
| Field | 数据 | Analyzed | Indexd | Stored | 说明 |
| StringField("fileName", fileName, Store.YES) | 字符串 | N | Y | N/Y | 不会被分词, 会存储索引, 自定义是否存储在文档中 |
| TextField("content", content, Store.YES) | 字符串/流 | Y | Y | N/Y | |
| LongField("size", size, Store.YES) | Long | Y | Y | Y/N | |
| StoredField(name, value) | 多种类型 | N | N | Y | 不分词, 不索引, 但要存储 |
Lucene的分词器
主要用于索引分词和搜索分词, 此时需要使用一种分词器
标准分词器的使用
测试代码:
package cn.tx.test;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.analysis.tokenattributes.OffsetAttribute;
import org.junit.Before;
import org.junit.Test;
public class LuceneTest1 {
@Before
public void setUp() throws Exception {
}
@Test
public void importAnalyzer() throws Exception {
//创建一个标准分词器的对象
Analyzer al = new StandardAnalyzer();
//获取分词对象
TokenStream stream = al.tokenStream("content", "全文检索是将整本书java、整篇文章中的任意内容信息查找出来的检索,java。");
//分词对象的重置
stream.reset();
//获取每一个语汇偏移量的属性对象
OffsetAttribute oa = stream.addAttribute(OffsetAttribute.class);
//获取分词的语汇属性
CharTermAttribute ca = stream.addAttribute(CharTermAttribute.class);
//遍历
while(stream.incrementToken()){
System.out.println("开始索引: "+oa.startOffset()+"结束索引: "+oa.endOffset());
System.out.println("=====================");
System.out.println(ca);
}
}
}
测试结果:
开始索引: 0结束索引: 1
=====================
全
开始索引: 1结束索引: 2
=====================
文
开始索引: 2结束索引: 3
=====================
检
开始索引: 3结束索引: 4
=====================
索
开始索引: 4结束索引: 5
=====================
是
开始索引: 5结束索引: 6
=====================
将
开始索引: 6结束索引: 7
=====================
整
开始索引: 7结束索引: 8
=====================
本
开始索引: 8结束索引: 9
=====================
书
开始索引: 9结束索引: 13
=====================
java
开始索引: 14结束索引: 15
=====================
整
开始索引: 15结束索引: 16
=====================
篇
开始索引: 16结束索引: 17
=====================
文
开始索引: 17结束索引: 18
=====================
章
开始索引: 18结束索引: 19
=====================
中
开始索引: 19结束索引: 20
=====================
的
开始索引: 20结束索引: 21
=====================
任
开始索引: 21结束索引: 22
=====================
意
开始索引: 22结束索引: 23
=====================
内
开始索引: 23结束索引: 24
=====================
容
开始索引: 24结束索引: 25
=====================
信
开始索引: 25结束索引: 26
=====================
息
开始索引: 26结束索引: 27
=====================
查
开始索引: 27结束索引: 28
=====================
找
开始索引: 28结束索引: 29
=====================
出
开始索引: 29结束索引: 30
=====================
来
开始索引: 30结束索引: 31
=====================
的
开始索引: 31结束索引: 32
=====================
检
开始索引: 32结束索引: 33
=====================
索
开始索引: 34结束索引: 38
=====================
java
标准分词器把标点符号都去掉, 每个中文字符都被分开了
比较常用的一种分词器: IKAnalyzer中文分词器
测试代码:
@Test
public void importAnalyzer() throws Exception {
//创建一个IK分词器的对象
Analyzer al = new IKAnalyzer();
//获取分词对象
TokenStream stream = al.tokenStream("content", "据IT市场要求,针对世界第一编程语言java开设java基础班课程和javaee+Hadoop就业班课程");
//分词对象的重置
stream.reset();
//获取每一个语汇偏移量的属性对象
OffsetAttribute oa = stream.addAttribute(OffsetAttribute.class);
//获取分词的语汇属性
CharTermAttribute ca = stream.addAttribute(CharTermAttribute.class);
//遍历
while(stream.incrementToken()){
System.out.println("开始索引: "+oa.startOffset()+"结束索引: "+oa.endOffset());
System.out.println("=====================");
System.out.println(ca);
}
}
三个配置文件, ext_stopword.dic 和 mydict.dic分别是排除/新增某些中文的配置, 均放在classpath下即可
1) ext_stopword.dic
2) mydict.dic
3) IKAnalyzer.cfg.xml
删除索引
测试代码:
1) 完全删除
@Test
public void deleteIndex() throws Exception{
IndexWriter iw = getIndexWriter();
iw.deleteAll();
iw.commit();
iw.close();
}
2) 查询删除
@Test
public void deleteIndexByQuery() throws Exception{
IndexWriter iw = getIndexWriter();
//创建语汇单元锁
Term term = new Term("fileName", "spring");
//创建指定语汇单元为查询条件的查询对象
TermQuery query = new TermQuery(term);
//删除指定索引
iw.deleteDocuments(query);
iw.commit();
iw.close();
}
ps: 生成索引时的分词器一定要跟删除索引时的分词器相同才能成功
Lucene全文检索之查询
查询1: 分词语汇单元查询
@Test
public void queryIndex() throws Exception{
Path path = Paths.get("C:\\Software\\JAVA\\EclipseMars4.5ForOthers\\workspace1\\lucene_demo\\index_loc");
FSDirectory fsd = FSDirectory.open(path);
//创建索引库的读取对象
DirectoryReader reader = DirectoryReader.open(fsd);
//创建索引库的搜索对象
IndexSearcher is = new IndexSearcher(reader);
//创建语汇单元的对象
Term term = new Term("content", "mybatis");
//创建分词的语汇查询对象
TermQuery query = new TermQuery(term);
//查询
TopDocs result = is.search(query, 10);
//总记录数
int totalHits = result.totalHits;
System.out.println("文件记录数: "+totalHits);
for(ScoreDoc sd: result.scoreDocs){
//获得文档的id
int id = sd.doc;
//获得文档对象
Document doc = is.doc(id);
String fileName = doc.get("fileName");
String content = doc.get("content");
String size = doc.get("size");
String path1 = doc.get("path");
System.out.println("文件名字: "+fileName);
System.out.println("文件内容: "+content);
System.err.println("文件大小: "+size);
System.out.println("文件路径: "+path1);
System.out.println("---------------------------");
}
}
查询2: 数值范围查询(以字节为单位)
@Test
public void queryIndex1() throws Exception{
IndexSearcher is = getDirReader();
Query tq = NumericRangeQuery.newLongRange("size", 0l, 100l, true, true);
System.out.println("打印查询条件: "+tq);
printDoc(is,tq);
}
/**
* 获取IndexSearcher对象
*/
public static IndexSearcher getDirReader() throws Exception{
Path path = Paths.get("C:\\Software\\JAVA\\EclipseMars4.5ForOthers\\workspace1\\lucene_demo\\index_loc");
FSDirectory fsd = FSDirectory.open(path);
DirectoryReader reader = DirectoryReader.open(fsd);
IndexSearcher is = new IndexSearcher(reader);
return is;
}
/**
* 打印文档
*/
public static void printDoc(IndexSearcher is, Query q) throws Exception{
TopDocs result = is.search(q, 10);
int totalHits = result.totalHits;
System.out.println("文件记录数: "+totalHits);
for(ScoreDoc sd: result.scoreDocs){
int id = sd.doc;
Document doc = is.doc(id);
String fileName = doc.get("fileName");
String content = doc.get("content");
String size = doc.get("size");
String path1 = doc.get("path");
System.out.println("文件名字: "+fileName);
System.out.println("文件内容: "+content);
System.err.println("文件大小: "+size);
System.out.println("文件路径: "+path1);
System.out.println("---------------------------");
}
}
查询3: 多条件组合查询
@Test
public void queryIndex2() throws Exception{
IndexSearcher is = getDirReader();
//创建BooleanQuery查询对象
//这种查询对象类似于一个数组或集合的形式, 可以控制&或者|或者!
BooleanQuery bq = new BooleanQuery();
//创建分词的语汇查询
TermQuery query1 = new TermQuery(new Term("fileName", "spring"));
TermQuery query2 = new TermQuery(new Term("content", "spring"));
TermQuery query3 = new TermQuery(new Term("content", "java"));
//bq控制
//MUST表示该条件"必须有"
bq.add(query1, Occur.MUST);
//SHOULD表示该条件"可有可无"
bq.add(query2, Occur.SHOULD);
//MUST_NOT表示"必须无"
bq.add(query3, Occur.MUST_NOT);
System.out.println("打印查询条件: "+bq);
printDoc(is, bq);
}
查询4: 查询条件的解析查询
@Test
public void queryIndex3() throws Exception{
IndexSearcher is = getDirReader();
Analyzer al = new IKAnalyzer();
QueryParser qp = new QueryParser("fileName", al);
Query query = qp.parse("今天学习全文检索技术Lucene");
System.out.println("打印查询条件: "+query);
printDoc(is, query);
}
/**
* 手写查询条件的解析查询(不常用)
* @throws Exception
*/
@Test
public void queryIndex4() throws Exception{
IndexSearcher is = getDirReader();
Analyzer al = new IKAnalyzer();
QueryParser qp = new QueryParser("fileName", al);
Query query = qp.parse("fileName:spring AND content:java");
System.out.println("打印查询条件: "+query);
printDoc(is, query);
}
查询5: 多域条件的解析查询
/**
* 多域的条件解析查询
*/
@Test
public void queryIndex5() throws Exception{
IndexSearcher is = getDirReader();
Analyzer al = new IKAnalyzer();
String[] fields = {"fileName", "content"};
MultiFieldQueryParser mp = new MultiFieldQueryParser(fields, al);
Query query = mp.parse("今天学习全文检索技术Lucene");
System.out.println("打印查询条件: "+query);
printDoc(is, query);
}
/**
* 多域条件解析+数值范围联合查询
* @throws Exception
*/
@Test
public void queryIndex6() throws Exception{
IndexSearcher is = getDirReader();
Analyzer al = new IKAnalyzer();
String[] fields = {"fileName", "content"};
MultiFieldQueryParser mp = new MultiFieldQueryParser(fields, al);
Query mq = mp.parse("今天学习全文检索技术Lucene");
Query tq = NumericRangeQuery.newLongRange("size", 0l, 1024l, true, true);
BooleanQuery bq = new BooleanQuery();
bq.add(mq, Occur.MUST);
bq.add(tq, Occur.MUST);
System.out.println("打印查询条件: "+bq);
printDoc(is, bq);
}

















 5522
5522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









